Task: Object Detection, Instance Segmentation
Method: Region-based CNN
Venue: CVPR 2014 / ICCV 2015 / NeurIPS 2015 / ICCV 2017
Year: 2014–2017
Paper: https://arxiv.org/abs/1311.2524 (R-CNN) | https://arxiv.org/abs/1504.08083 (Fast) | https://arxiv.org/abs/1506.01497 (Faster) | https://arxiv.org/abs/1703.06870 (Mask)
摘要
R-CNN 系列是深度学习目标检测的奠基之作,开创了”区域提议 + CNN 特征提取”的两阶段检测范式,并在四年间沿着效率与能力两条主线持续演进。
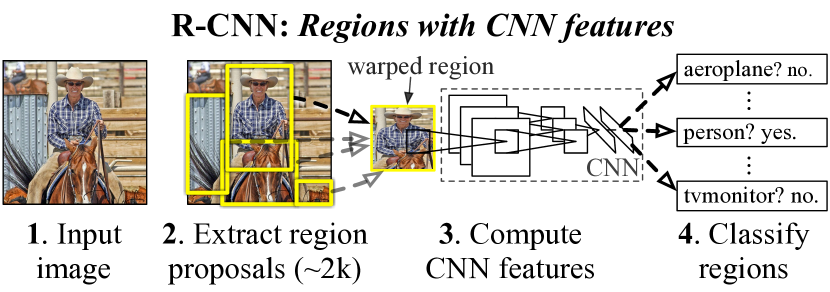
R-CNN(CVPR 2014)首次将 CNN 特征引入目标检测,利用 Selective Search 生成约 2000 个候选区域,每个区域独立通过 CNN 提取 4096 维特征,再用线性 SVM 分类与边界框回归。该方法在 VOC 2012 上比当时最优的 DPM 方法提升超过 30% 的相对精度。
Fast R-CNN(ICCV 2015)通过 RoI Pooling 层实现卷积特征共享,将整图只过一次 CNN,再从共享特征图上提取每个区域的固定尺寸特征。同时引入多任务损失,将分类与回归合并为单阶段训练,测试速度比 R-CNN 快 146 倍(不含候选区域生成)。
Faster R-CNN(NeurIPS 2015)提出区域提议网络(RPN),用共享卷积特征生成候选区域,取代耗时约 2 秒的 Selective Search,RPN 推理仅约 10ms。整体框架实现了从特征提取到区域提议再到检测的全流程共享。
Mask R-CNN(ICCV 2017)在 Faster R-CNN 基础上增加并行的 FCN 掩码分支,将检测扩展至实例分割。关键创新 RoIAlign 用双线性插值替代 RoI Pooling 的量化操作,消除了像素级对齐误差,仅增加约 20% 计算开销即实现了精确的实例分割。
核心论点:R-CNN 系列确立了”区域提议 + CNN 特征 + 分类回归”的两阶段检测范式,并通过特征共享、端到端训练、锚框机制和像素对齐四次关键改进,将该范式从粗粒度检测推进至像素级实例分割,成为现代目标检测与实例分割的基石。
问题与动机
2012 年 AlexNet 在图像分类上取得突破后,如何将 CNN 的强大特征表示能力迁移至目标检测,成为核心问题。当时目标检测的主流方案各有瓶颈:
| 阶段 | 方法 | 核心问题 | 性能/效率 |
|---|---|---|---|
| 2014 前 | DPM (HOG+SVM) | 手工特征表达力有限 | 33.7% mAP (VOC 2007) |
| R-CNN | CNN per region | 重复计算,训练流程割裂 | 66.0% mAP, 13s/image |
| Fast R-CNN | 共享卷积特征 | 候选区域生成仍是瓶颈 | 66.9% mAP, ~0.3s + 2s SS |
| Faster R-CNN | RPN 替代 SS | 仅支持框级检测 | 73.2% mAP, 5 FPS (VGG) |
| Mask R-CNN | 增加掩码分支 | — | 39.8% bbox AP, 37.1% mask AP |
R-CNN 系列的演进动力可归纳为逐步消除四个瓶颈:
- 特征瓶颈:手工特征 → CNN 特征(R-CNN)
- 计算瓶颈:逐区域卷积 → 共享卷积(Fast R-CNN)
- 提议瓶颈:外部 Selective Search → 网络内部 RPN(Faster R-CNN)
- 任务瓶颈:框级检测 → 像素级分割(Mask R-CNN)
核心痛点:如何在保持高检测精度的同时,实现端到端训练、高效推理,并将检测能力向更细粒度的视觉理解(实例分割)扩展。
核心洞察
洞察 1:区域识别 + CNN 特征 = 迁移学习革命
传统做法:DPM 等方法依赖手工设计的 HOG 特征,特征表达力有限,目标检测精度长期停滞。
R-CNN 的做法:将 ImageNet 预训练的 CNN 作为通用特征提取器,应用于 Selective Search 生成的候选区域。每个区域缩放至 $227 \times 227$,经过 CNN 提取 4096 维特征向量,再用类别特定的 SVM 进行分类。
这个看似简单的组合产生了划时代的效果:
- VOC 2007 mAP 从 DPM 的 33.7% 跃升至 R-CNN 的 58.5%(AlexNet),进一步到 66.0%(VGG-16)
- 证明了”大规模有监督预训练 + 小数据集微调”的迁移学习范式在检测任务上的有效性
关键机制:R-CNN 发现在 ImageNet 上预训练后,针对检测任务进行 domain-specific 微调至关重要。微调使 CNN 适应检测任务的特点(局部区域识别 vs 整图分类),在 VOC 2007 上带来约 8 个百分点的提升。
洞察 2:共享计算 + 端到端训练 = 统一高效检测
R-CNN 的割裂:R-CNN 的训练流程分为三个独立阶段——CNN 微调、SVM 训练、边界框回归,彼此不互通梯度。推理时每个候选区域独立过 CNN,约 2000 个区域导致海量冗余计算。
Fast R-CNN → Faster R-CNN 的统一:
Fast R-CNN 引入两个关键改进:
- RoI Pooling:整图只过一次 CNN,从共享特征图上用 max pooling 提取每个区域的固定尺寸($7 \times 7$)特征
- 多任务损失:softmax 分类 + smooth $L_1$ 回归在同一网络中联合优化
其中 $L_{cls}$ 为 softmax 交叉熵,$L_{loc}$ 为 smooth $L_1$ 损失,$\lambda = 1$。
这使得测试速度比 R-CNN 快 146 倍(不含候选区域生成),训练速度快 9 倍。
Faster R-CNN 进一步消除了最后的外部依赖——将 Selective Search(2s)替换为 RPN(10ms)。RPN 在共享特征图上滑动 $3 \times 3$ 窗口,每个位置预测 9 个锚框(3 尺度 × 3 比例)的前景/背景分数与边界框偏移:
至此,从图像输入到检测输出的全流程都在一个统一网络中完成。
洞察 3:像素级扩展 + 对齐精度
RoI Pooling 的缺陷:RoI Pooling 将浮点数坐标量化为整数(两次取整),导致 RoI 与提取的特征之间存在像素级错位。对于分类和边界框回归而言,这种错位影响较小;但对于需要像素精度的掩码预测,量化误差是致命的。
Mask R-CNN 的 RoIAlign:用双线性插值替代量化取整,在每个 RoI bin 内均匀采样 4 个点,通过双线性插值计算每个采样点的精确特征值,再 max/average pooling 得到 bin 输出。
RoIAlign 的影响:掩码 AP 提升约 3 个百分点。
解耦掩码预测:Mask R-CNN 为每个类别独立预测二值掩码,而非使用 softmax 在类别间竞争。即掩码分支输出 $K$ 个 $m \times m$ 的二值掩码($K$ 为类别数),分类任务由检测分支的 softmax 负责。这种解耦设计消除了类间竞争,让掩码分支专注于空间分割质量。
三个关键数字:
- 66.0% mAP:R-CNN (VGG-16) 在 VOC 2007 上的成绩,比 DPM 的 33.7% 相对提升约 30%,标志着深度学习检测时代的开始
- 73.2% mAP:Faster R-CNN 在 VOC 2007 上的成绩,RPN 仅需约 10ms 即生成高质量提议,替代了耗时约 2 秒的 Selective Search
- 37.1% mask AP:Mask R-CNN (ResNeXt-101-FPN) 在 COCO 上的实例分割成绩,仅增加约 20% 计算开销即将检测扩展至像素级分割
方法设计
整体架构
$$\text{Detection} = \text{Region Proposals} + \text{CNN Features} + \text{Classification/Regression}$$R-CNN 系列的核心流程在四个版本中逐步统一与简化:
┌─────────────────────────────────────────────────────────────────────┐ │ R-CNN 系列架构演进 │ ├─────────────────────────────────────────────────────────────────────┤ │ │ │ R-CNN (2014): │ │ Image → Selective Search (~2000) → Warp 227×227 │ │ → CNN (AlexNet/VGG) per region → 4096-d feature │ │ → SVM (per class) + BBox Regression │ │ │ │ Fast R-CNN (2015): │ │ Image → Shared CNN → Feature Map │ │ → Selective Search → RoI Pooling (7×7) │ │ → FC layers → Softmax + BBox Regression │ │ │ │ Faster R-CNN (2015): │ │ Image → Shared CNN → Feature Map │ │ ├→ RPN (3×3 sliding, 9 anchors) → Proposals │ │ └→ RoI Pooling → FC → Softmax + BBox Regression │ │ │ │ Mask R-CNN (2017): │ │ Image → FPN (ResNet/ResNeXt) → Multi-scale Feature Maps │ │ ├→ RPN → Proposals │ │ └→ RoIAlign (14×14/7×7) → FC → Softmax + BBox + Mask (FCN) │ │ │ └─────────────────────────────────────────────────────────────────────┘
关键组件
四版本核心差异对比
| 维度 | R-CNN | Fast R-CNN | Faster R-CNN | Mask R-CNN |
|---|---|---|---|---|
| 区域提议 | Selective Search (~2s) | Selective Search (~2s) | RPN (~10ms) | RPN (~10ms) |
| 特征提取 | 逐区域过 CNN | 整图共享 CNN | 整图共享 CNN | FPN 多尺度特征 |
| 区域特征 | Warp + CNN forward | RoI Pooling 7×7 | RoI Pooling 7×7 | RoIAlign 7×7/14×14 |
| 分类器 | SVM (per class) | Softmax (end-to-end) | Softmax (end-to-end) | Softmax (end-to-end) |
| 训练方式 | 三阶段独立训练 | 单阶段多任务 | 四步交替/联合训练 | 多任务联合训练 |
| 输出 | 类别 + 边界框 | 类别 + 边界框 | 类别 + 边界框 | 类别 + 边界框 + 掩码 |
| 典型速度 | 13s/image (GPU) | ~0.3s (不含 SS) | 5 FPS (VGG-16) | 约 5 FPS |
RoI Pooling vs RoIAlign
RoI Pooling 与 RoIAlign 是理解 Fast R-CNN → Mask R-CNN 演进的关键:
| 特性 | RoI Pooling | RoIAlign |
|---|---|---|
| 坐标处理 | 两次量化取整 | 双线性插值,无量化 |
| 像素对齐 | 存在错位 | 精确对齐 |
| 分类/检测影响 | 较小 | 略有提升 |
| 掩码预测影响 | 严重 | 提升约 3 AP |
| 采样策略 | 直接 max pool | 每 bin 4 点采样后 pool |
损失函数
Fast R-CNN / Faster R-CNN 多任务损失:
$$L = L_{cls}(p, u) + \lambda [u \geq 1] L_{loc}(t^u, v)$$Mask R-CNN 多任务损失:
$$L = L_{cls} + L_{box} + L_{mask}$$其中 $L_{mask}$ 为逐像素的二值交叉熵损失,仅在 GT 类别对应的掩码通道上计算,实现类别解耦。
RPN 详解
RPN 在共享特征图的每个位置放置 $k$ 个锚框,对每个锚框预测:
- 前景/背景二分类:$2k$ 个分数
- 边界框偏移回归:$4k$ 个坐标偏移
锚框设计(Faster R-CNN):
- 3 种尺度:$128^2, 256^2, 512^2$
- 3 种比例:1:1, 1:2, 2:1
- 每位置共 9 个锚框
训练时正样本定义:与任意 GT 框的 IoU > 0.7,或与某 GT 框的 IoU 最大的锚框。
实验与分析
主要结果
VOC 2007 检测结果
| 方法 | Backbone | mAP (%) | 速度 | 备注 |
|---|---|---|---|---|
| DPM v5 | HOG | 33.7 | — | 手工特征基线 |
| R-CNN (T-Net FT+BB) | AlexNet | 58.5 | 13s/image | CNN 检测开端 |
| R-CNN (O-Net FT+BB) | VGG-16 | 66.0 | — | 更大网络更高精度 |
| Fast R-CNN | VGG-16 | 66.9 (单尺度) | ~0.3s (不含 SS) | 特征共享 |
| Fast R-CNN | VGG-16 | 70.0 (多尺度) | — | 多尺度测试 |
| Faster R-CNN | VGG-16 | 73.2 | 5 FPS | RPN 端到端 |
| Faster R-CNN | ZF | 59.9 | 17 FPS | 轻量 backbone |
COCO 检测与分割结果
| 方法 | Backbone | bbox AP (%) | mask AP (%) | 备注 |
|---|---|---|---|---|
| Faster R-CNN | VGG-16 | 42.7 (test-dev) | — | COCO 基线 |
| Mask R-CNN | ResNet-101-FPN | 38.2 | 35.7 | 标准配置 |
| Mask R-CNN | ResNeXt-101-FPN | 39.8 | 37.1 | 最佳配置 |
关键发现:
- CNN 特征的巨大优势:R-CNN (VGG-16) 在 VOC 2007 上达到 66.0% mAP,相比 DPM 的 33.7% 几乎翻倍,证明深度特征对检测任务的决定性价值
- 共享计算的效率提升:Fast R-CNN 将逐区域 CNN 前传改为整图共享,推理加速 146 倍(不含候选区域),精度不降反升
- 掩码分支的低成本扩展:Mask R-CNN 在 Faster R-CNN 基础上仅增加约 20% 开销,即在 COCO 上同时达到 39.8% bbox AP 和 37.1% mask AP
消融实验:验证三个洞察
洞察 1 验证:预训练 + 微调的效果(R-CNN, VOC 2007)
| 配置 | mAP (%) | 验证洞察 |
|---|---|---|
| R-CNN (AlexNet, 无微调) | 46.2 | 洞察 1 |
| R-CNN (AlexNet, 微调) | 54.2 | 洞察 1 |
| R-CNN (AlexNet, 微调+BB) | 58.5 | 洞察 1 |
| R-CNN (VGG-16, 微调+BB) | 66.0 | 洞察 1 |
微调带来约 8 个百分点的提升,边界框回归进一步提升约 4 个百分点。
洞察 2 验证:端到端训练与特征共享的效果
| 配置 | mAP (VOC 07, %) | 速度 | 验证洞察 |
|---|---|---|---|
| R-CNN (VGG-16, 三阶段) | 66.0 | 13s/image | 洞察 2 |
| Fast R-CNN (VGG-16, 单阶段) | 66.9 | ~0.3s (不含 SS) | 洞察 2 |
| Faster R-CNN (VGG-16, RPN) | 73.2 | 5 FPS | 洞察 2 |
注:跨论文对比,结果受训练细节差异影响,但总趋势明确。
洞察 3 验证:RoIAlign 的效果(Mask R-CNN, COCO)
| RoI 方式 | mask AP (%) | 验证洞察 |
|---|---|---|
| RoI Pooling | ~34 | 洞察 3 |
| RoIAlign | ~37 | 洞察 3 |
注:RoIAlign 相比 RoI Pooling 在 mask AP 上提升约 3 个百分点,论文中明确报告了该量级差异。
性能瓶颈分析
R-CNN 系列各阶段的主要瓶颈逐步转移:
| 版本 | 主要瓶颈 | 后续解决方案 |
|---|---|---|
| R-CNN | 逐区域 CNN 前传(~2000 次) | Fast R-CNN 共享卷积 |
| Fast R-CNN | Selective Search (~2s) | Faster R-CNN 的 RPN |
| Faster R-CNN | 两阶段框架整体速度有限 | 单阶段检测器(YOLO, SSD) |
| Mask R-CNN | 掩码分辨率受 RoI 尺寸限制 | 后续 PointRend 等方法 |
失效场景分析
- 密集小目标:R-CNN 系列对小目标检测能力有限,Faster R-CNN 的锚框最小为 $128^2$,小于该尺度的目标容易漏检。Mask R-CNN 引入 FPN 在一定程度上缓解了该问题
- 严重遮挡:候选区域只能覆盖目标的可见部分,严重遮挡时区域提议质量下降,导致分类和回归均受影响
- 类别不平衡:RPN 中前景/背景样本比例严重失衡(绝大多数锚框为背景),论文中通过采样策略(每个 mini-batch 选 128 正 + 128 负)缓解
- 实时性不足:VGG-16 backbone 下 Faster R-CNN 仅约 5 FPS,难以满足实时应用需求
工程实践
训练配置
**R-CNN (CVPR 2014)**:
Backbone: AlexNet / VGG-16 |
**Fast R-CNN (ICCV 2015)**:
Backbone: VGG-16 |
**Faster R-CNN (NeurIPS 2015)**:
Backbone: VGG-16 / ZF |
**Mask R-CNN (ICCV 2017)**:
Backbone: ResNet-50/101-FPN, ResNeXt-101-FPN |
复现要点
- ImageNet 预训练是必要条件:R-CNN 无预训练 mAP 仅 46.2%,预训练后升至 54.2%,这一结论在后续所有版本中保持成立
- 正负样本采样比例:RPN 训练时 1:1 采样(128 正 + 128 负),Fast R-CNN 中正样本比例 25%,比例失衡会导致训练不稳定
- RoI Pooling 的输入坐标:注意特征图到原图之间的尺度对齐,这是 RoI Pooling 量化误差的来源,也是 RoIAlign 解决的关键问题
- NMS 阈值调优:Faster R-CNN 中 RPN 使用 IoU=0.7 的 NMS,检测阶段使用 IoU=0.3 的 NMS,阈值设置显著影响最终精度
- Mask 分支中 class-specific 预测:Mask R-CNN 为每个类别单独预测掩码(K 个二值掩码),训练时只对 GT 类别的掩码通道计算损失
性能优化方向
精度提升:
- 使用更强的 backbone(ResNeXt、Swin Transformer 等)可带来显著 AP 提升,但计算开销也相应增加
- FPN 多尺度特征融合对小目标检测有明显帮助,Mask R-CNN 中已采用该设计
- Cascade R-CNN 通过多级精炼进一步提升检测精度,核心思想是逐级提高 IoU 阈值
速度优化:
- 轻量化 backbone(MobileNet、ShuffleNet)替代 VGG/ResNet 可大幅加速,但精度会有一定损失
- RoI 数量减少(从 2000 降至 300)可在精度损失较小的情况下明显加速推理
- TensorRT 等推理优化工具可对 Faster/Mask R-CNN 进行算子融合与精度量化
研究启示
可迁移的思想
- “预训练 + 微调”迁移学习范式:R-CNN 首次在检测任务中验证了该范式的有效性,后续被广泛应用于分割、跟踪、姿态估计等几乎所有视觉任务,至今仍是默认训练策略
- “共享特征 + 任务特定头”的多任务架构:从 Fast R-CNN 的 RoI Pooling + 多任务损失开始,到 Mask R-CNN 的检测+分割并行分支,这种设计模式成为多任务学习的通用模板
- “锚框 + 二阶段细化”的检测范式:RPN 的锚框机制虽已被 anchor-free 方法(如 CenterNet、FCOS)挑战,但其 coarse-to-fine 的思路在 DETR 的 query 机制等现代方法中仍有体现
- “对齐精度决定任务上限”的原则:RoIAlign 对 RoI Pooling 的改进看似微小(仅消除量化),却带来约 3 AP 的实质提升,说明特征与空间的精确对齐对像素级任务至关重要
方法局限
- 两阶段框架的推理速度仍受限于逐 RoI 处理,难以达到真正实时(VGG-16 仅 5 FPS)
- 锚框设计需要针对数据集手动调整尺度和比例,泛化性不足
- Mask R-CNN 的掩码分辨率受 RoI 尺寸限制(通常 $28 \times 28$),对大目标的边缘精度不足
技术影响
- 开创两阶段检测范式:R-CNN 系列定义了”提议 + 分类”的基本框架,后续 FPN、Cascade R-CNN、HTC 等方法均在此基础上改进
- 推动检测基准发展:R-CNN 系列在 VOC 和 COCO 上设立了标杆性能,推动社区从 VOC 转向更大规模的 COCO 基准
- 催生 anchor-free 运动:R-CNN 系列中锚框设计的复杂性激发了 CornerNet、CenterNet、FCOS 等无锚框方法的研究,推动了检测方法多样化
- 实例分割的工业标准:Mask R-CNN 至今仍是实例分割的默认基线和实际工业应用中的常用方案,其简洁架构和稳定性能使其在自动驾驶、医疗影像等领域广泛部署