Task: Image Classification / Feature Backbone
Method: Residual Learning, Shortcut Connection
Venue: CVPR
Year: 2016
Paper: https://arxiv.org/abs/1512.03385
Code: https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
摘要
更深的神经网络通常更难训练。本文提出一种残差学习框架,使得训练远超以往深度的网络成为可能。该方法将网络层显式地重新表述为学习相对于层输入的残差函数,而非学习无参照的映射函数。在 ImageNet 数据集上,作者评估了深达 152 层的残差网络——比 VGG 网络深 8 倍,但复杂度更低。这些残差网络的集成在 ImageNet 测试集上取得了 3.57% 的 top-5 错误率,赢得了 ILSVRC 2015 分类任务第一名。极深的表征在 COCO 目标检测数据集上也表现出色,带来了 28% 的相对提升。深度残差网络是 ILSVRC & COCO 2015 竞赛多个赛道第一名的基础,涵盖 ImageNet 检测、ImageNet 定位、COCO 检测和 COCO 分割。
核心论点:通过引入恒等快捷连接(identity shortcut connection),将”学习目标映射”重塑为”学习残差映射”,从根本上解决了深层网络的退化问题,使网络深度从 ~20 层突破至 152 层乃至 1000+ 层,奠定了此后几乎所有视觉模型的骨干网络基础。
问题与动机
在 ResNet 之前,深度卷积网络的发展陷入了”深度悖论”:
| 方法 | 代表作 | 最大有效深度 | 核心问题 |
|---|---|---|---|
| 经典 CNN | LeNet / AlexNet | ~8 层 | 梯度消失/爆炸 |
| 归一化辅助 | VGGNet / BN-Inception | ~30 层 | 退化问题(非过拟合) |
| 门控机制 | Highway Networks | ~100 层 | 门参数依赖数据,无法全通 |
关键发现:当网络深度从 20 层增加到 56 层时,训练误差反而上升——这不是过拟合(测试误差也上升),而是优化困难。理论上,更深网络至少可以构造出与浅层网络等价的解(额外层执行恒等映射),但实际训练中优化器找不到这个解。
核心痛点:深度网络存在退化问题(degradation problem),即增加网络深度导致训练误差上升,这不是过拟合,而是优化器无法在深层网络中找到好的解。
核心洞察
洞察 1:学习残差比学习完整映射更容易
传统做法:让堆叠的非线性层直接学习期望的底层映射 $\mathcal{H}(\mathbf{x})$。
本文做法:让这些层学习残差函数 $\mathcal{F}(\mathbf{x}) := \mathcal{H}(\mathbf{x}) - \mathbf{x}$,原始映射变为 $\mathcal{F}(\mathbf{x}) + \mathbf{x}$。
$$\mathbf{y} = \mathcal{F}(\mathbf{x}, \{W_i\}) + \mathbf{x}$$如果最优映射接近恒等变换,将残差推向零远比从零开始拟合恒等映射容易。实验证明(论文 Fig.7),学到的残差函数响应值普遍很小,说明恒等映射提供了合理的预条件化(preconditioning)。
洞察 2:恒等快捷连接零参数、零计算开销
传统做法(Highway Networks):用可学习的门控函数决定信息是否通过,引入额外参数,且门关闭时退化为普通层。
本文做法:恒等快捷连接(identity shortcut)直接将输入加到输出上,不引入额外参数和计算。当输入输出维度不同时,仅用 $1 \times 1$ 卷积做线性投影:
$$\mathbf{y} = \mathcal{F}(\mathbf{x}, \{W_i\}) + W_s \mathbf{x}$$论文对比了三种方案:(A) 零填充、(B) 仅在维度变化时投影、(C) 全部投影。三者差异极小,说明投影快捷连接不是解决退化的关键——恒等映射才是。
洞察 3:Bottleneck 结构实现深度-效率平衡
传统做法(ResNet-34):每个残差块用 2 层 $3 \times 3$ 卷积,深度增加时参数和计算量线性增长。
本文做法(ResNet-50/101/152):用 $1 \times 1 \to 3 \times 3 \to 1 \times 1$ 的”瓶颈”设计,先降维再升维。$1 \times 1$ 卷积负责调整通道数,使 $3 \times 3$ 卷积工作在低维空间中。
- ResNet-50 (3.8 GFLOPs) 与 ResNet-34 (3.6 GFLOPs) 计算量接近
- ResNet-152 (11.3 GFLOPs) 仍低于 VGG-16 (15.3 GFLOPs)
- 恒等快捷连接尤为重要:如果换成投影快捷连接,瓶颈结构的时间复杂度和模型大小会翻倍
三个关键数字:
- **3.57%**:ResNet 集成模型在 ImageNet 测试集上的 top-5 错误率,ILSVRC 2015 分类赛第一名
- 152 层:最深的 ResNet 变体,比 VGG 深 8 倍但复杂度更低(11.3 vs 19.6 GFLOPs)
- **28%**:在 COCO 检测数据集上的相对 mAP 提升(使用 Faster R-CNN 替换 VGG 为 ResNet-101)
方法设计
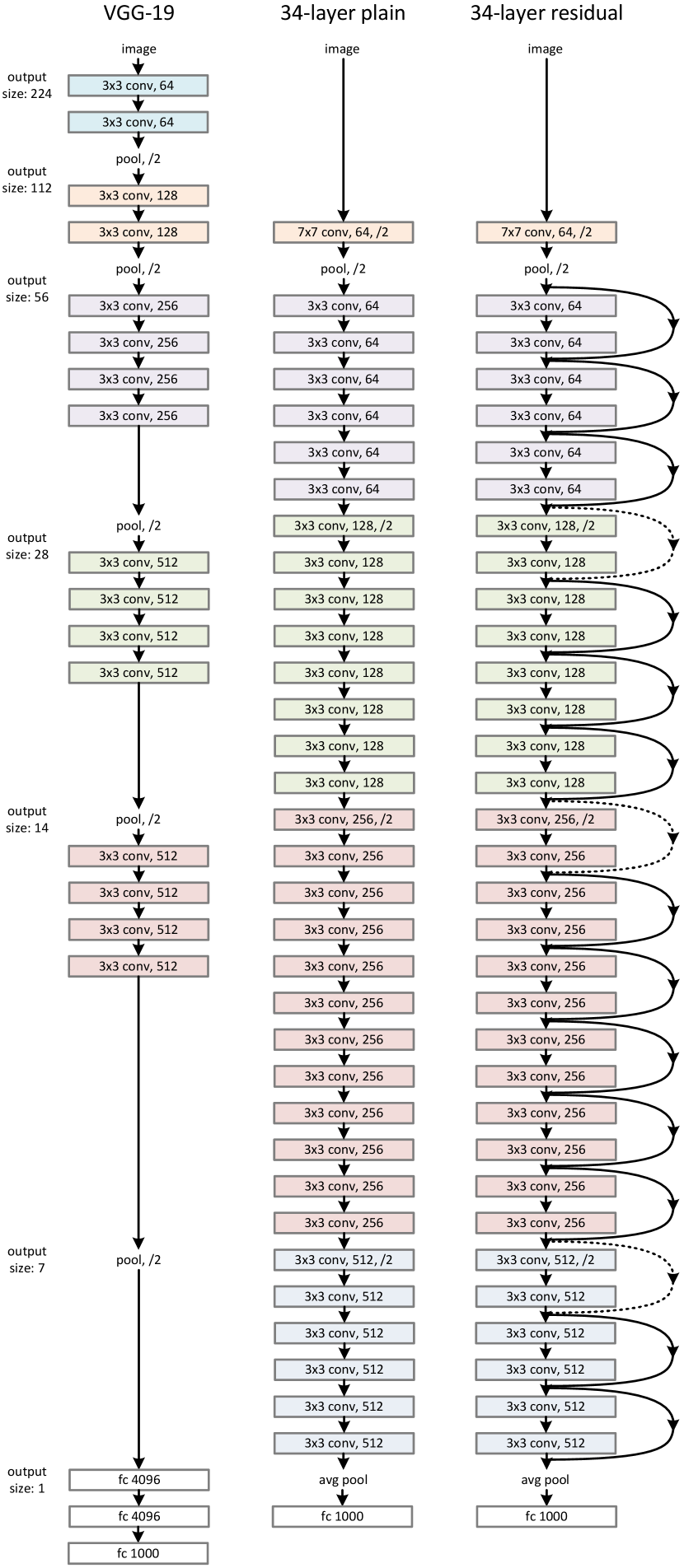
4.1 整体架构
核心流程:输入图像 → 7×7 Conv + BN + ReLU + MaxPool → 4 个残差阶段 → Global AvgPool → FC → 分类输出
输入 (224×224×3)
│
┌────┴────┐
│ 7×7 Conv│ stride=2, 64 通道
│ + BN │
│ + ReLU │
└────┬────┘
│ (112×112×64)
┌────┴────┐
│ MaxPool │ 3×3, stride=2
└────┬────┘
│ (56×56×64)
┌────┴────┐
│ Stage 1 │ conv2_x: BasicBlock×2 (ResNet-18)
└────┬────┘ Bottleneck×3 (ResNet-50)
│ (56×56×64/256)
┌────┴────┐
│ Stage 2 │ conv3_x: stride=2 下采样
└────┬────┘
│ (28×28×128/512)
┌────┴────┐
│ Stage 3 │ conv4_x: stride=2 下采样
└────┬────┘
│ (14×14×256/1024)
┌────┴────┐
│ Stage 4 │ conv5_x: stride=2 下采样
└────┬────┘
│ (7×7×512/2048)
┌────┴────┐
│ GAP+FC │ → 1000 类 softmax
└─────────┘
4.2 关键组件
ResNet 变体对比:
| 变体 | 层数 | Block 类型 | 各阶段 Block 数 | FLOPs | 参数量 |
|---|---|---|---|---|---|
| ResNet-18 | 18 | BasicBlock | [2, 2, 2, 2] | 1.8G | 11.7M |
| ResNet-34 | 34 | BasicBlock | [3, 4, 6, 3] | 3.6G | 21.8M |
| ResNet-50 | 50 | Bottleneck | [3, 4, 6, 3] | 3.8G | 25.6M |
| ResNet-101 | 101 | Bottleneck | [3, 4, 23, 3] | 7.6G | 44.5M |
| ResNet-152 | 152 | Bottleneck | [3, 8, 36, 3] | 11.3G | 60.2M |
Block 设计:
| Block 类型 | 结构 | expansion | 适用变体 |
|---|---|---|---|
| BasicBlock | 3×3 Conv → BN → ReLU → 3×3 Conv → BN → (+shortcut) → ReLU | 1 | ResNet-18/34 |
| Bottleneck | 1×1 Conv → BN → ReLU → 3×3 Conv → BN → ReLU → 1×1 Conv → BN → (+shortcut) → ReLU | 4 | ResNet-50/101/152 |
损失函数:标准交叉熵损失
$$L = -\sum_{i=1}^{C} y_i \log(\hat{y}_i)$$4.3 关键代码
以下为 torchvision 官方实现中的核心组件。
Bottleneck 残差块(来源:torchvision/models/resnet.py)
📄 点击展开 Bottleneck 代码
class Bottleneck(nn.Module): |
ResNet 主体网络(来源:torchvision/models/resnet.py)
📄 点击展开 ResNet 网络构建代码
class ResNet(nn.Module): |
实验与分析
5.1 主要结果
ImageNet 分类性能(单模型,10-crop 测试):
| 方法 | 层数 | top-1 err. (%) | top-5 err. (%) |
|---|---|---|---|
| VGG-16 | 16 | 28.07 | 9.33 |
| GoogLeNet | 22 | - | 9.15 |
| plain-34 | 34 | 28.54 | 10.02 |
| ResNet-34 C | 34 | 24.19 | 7.40 |
| ResNet-50 | 50 | 22.85 | 6.71 |
| ResNet-101 | 101 | 21.75 | 6.05 |
| ResNet-152 | 152 | 21.43 | 5.71 |
COCO 检测性能(Faster R-CNN):
| Backbone | mAP@.5 | mAP@[.5,.95] |
|---|---|---|
| VGG-16 | 41.5 | 21.2 |
| ResNet-101 | 48.4 | 27.2 |
关键发现:
- ResNet-34 比 plain-34 top-1 错误率降低 3.5%,验证了残差学习在深层网络上的有效性
- 从 ResNet-50 到 ResNet-152,性能持续提升且不出现退化
- 在 COCO 检测上,ResNet-101 相比 VGG-16 带来 6.0% 绝对 mAP 提升(28% 相对提升),纯粹源于特征表示的改进
5.2 消融实验:验证三个洞察
| 实验设置 | top-1 err. (%) | 相对于 plain 的变化 | 验证洞察 |
|---|---|---|---|
| plain-18 | 27.94 | baseline | - |
| plain-34 | 28.54 | +0.60(退化) | 洞察 1 |
| ResNet-18 | 27.88 | -0.06(持平) | 洞察 1 |
| ResNet-34 A(零填充) | 25.03 | -3.51 | 洞察 2 |
| ResNet-34 B(投影匹配维度) | 24.52 | -4.02 | 洞察 2 |
| ResNet-34 C(全投影) | 24.19 | -4.35 | 洞察 2 |
| ResNet-50(Bottleneck) | 22.85 | -5.69 | 洞察 3 |
| ResNet-101(Bottleneck) | 21.75 | -6.79 | 洞察 3 |
| ResNet-152(Bottleneck) | 21.43 | -7.11 | 洞察 3 |
- 洞察 1 验证:plain-34 比 plain-18 更差(退化),而 ResNet-34 比 ResNet-18 好 2.8%,残差学习逆转了退化趋势
- 洞察 2 验证:A/B/C 三种快捷连接方案差异极小(25.03 vs 24.52 vs 24.19),恒等映射足以解决退化问题
- 洞察 3 验证:Bottleneck 结构使 ResNet-50 在接近 ResNet-34 的计算量下(3.8 vs 3.6 GFLOPs)取得大幅精度提升
5.3 性能瓶颈分析
- 在 CIFAR-10 上训练 1202 层网络仍可收敛(训练误差 < 0.1%),但测试误差 7.93% 高于 110 层的 6.43%,原因是过拟合(19.4M 参数对小数据集过多)
- 论文残差函数响应分析(Fig.7)表明:更深的 ResNet 每层残差响应越小,说明单层修改信号的幅度随深度递减
5.4 失效场景分析
- 极小数据集过拟合:1202 层 ResNet 在 CIFAR-10(50k 训练样本)上出现过拟合,论文建议引入更强正则化(如 dropout/maxout),但未在本文采用
- 超深网络收敛困难:110 层 ResNet 需要学习率 warmup(先用 0.01 训练 400 迭代再切换到 0.1),否则无法收敛
- 训练初期学习率敏感:当使用初始学习率 0.1 直接训练 110 层网络时,训练不稳定
工程实践
6.1 训练配置
Backbone: ResNet-18 / 34 / 50 / 101 / 152 |
6.2 复现要点
- BN 放在每个卷积之后、激活之前:这是 ResNet 的标准结构,BN 保证了前向信号的方差不会退化
- Kaiming 初始化:采用 He 初始化(fan_out 模式),确保每层方差保持一致
- 不使用 dropout:BN 已提供正则化效果,加 dropout 反而可能互相干扰
- 0.1 学习率 + 分段衰减:在验证误差平台期将学习率除以 10,通常在 30/60 epoch 处衰减
- 残差分支 BN 零初始化:将每个残差块最后一个 BN 的 $\gamma$ 初始化为 0,使残差块初始时表现为恒等映射,可提升约 0.2~0.3%
- stride 放在 3×3 卷积(V1.5):torchvision 实现将下采样 stride 放在 Bottleneck 的 3×3 卷积上(而非原论文的 1×1 卷积),精度略有提升
6.3 性能优化方向
精度提升:
- 引入 SE(Squeeze-and-Excitation)通道注意力模块,增加少量参数换取约 1% top-1 提升
- 采用更先进的训练策略(如 cosine 学习率、mixup、label smoothing),torchvision V2 权重 ResNet-50 可达 80.858% top-1
速度优化:
- 使用分组卷积(ResNeXt)在相同计算量下提升精度
- 通道剪枝可在精度损失无明显损失的前提下减少 FLOPs
- 量化(INT8)推理可将速度提升约 2-3 倍
研究启示
7.1 可迁移的思想
- 残差连接是深度网络的通用设计原则:几乎所有后续网络(DenseNet、Transformer、ViT、Swin)都采用了某种形式的残差连接,在任何需要建立梯度直通路径的场景都可使用
- “让网络学习差异而非完整映射”的思想:可推广至目标检测(回归偏移量而非绝对坐标)、光流估计(残差流)、超分辨率(学习高低频差异)等任务
- Bottleneck 降维-升维设计:通过低维空间计算减少开销,在 Transformer 的 FFN($d \to 4d \to d$)中同样被广泛使用
- “构造解存在性论证”的研究方法论:通过理论构造证明更深网络至少不应更差,从而将问题定位为优化问题而非表达能力问题
7.2 方法局限
- 恒等映射要求输入输出维度完全一致,跨阶段仍需投影快捷连接,无法避免维度变化时的参数引入
- 极深网络(>1000 层)在小数据集上过拟合,需要额外正则化手段
- ResNet 的平移等变性和局部感受野限制了全局信息建模能力,被后来的 Transformer 架构超越
7.3 技术影响
- 定义了视觉骨干网络标准:ResNet-50 成为计算机视觉中”默认 baseline”,几乎所有检测、分割、BEV 感知论文都以 R50 作为基准对比
- 催生了整个残差学习家族:ResNeXt(分组)、WideResNet(宽度)、ResNeSt(Split-Attention)、Res2Net(多尺度)等变体持续发展
- 跨领域影响:残差连接被 Transformer(Vaswani et al., 2017)直接采用,成为 NLP 和多模态模型的核心组件
- 工业部署基石:ResNet 因其简洁结构和良好的推理效率,成为边缘设备和云端部署中最广泛使用的视觉骨干网络