Task: 2D 目标检测
Method: Multi-scale Default Boxes + VGG-16
Venue: ECCV
Year: 2016
Paper: https://arxiv.org/abs/1512.02325
Code: https://github.com/weiliu89/caffe/tree/ssd
摘要
SSD 提出了一种基于单个深度网络的目标检测方法。该方法将输出空间离散化为一组不同宽高比和尺度的默认框(default boxes),在多个不同分辨率的特征图上同时预测每个默认框的类别得分和位置偏移量,最终通过非极大值抑制生成检测结果。与需要区域提议的方法不同,SSD 完全去除了提议生成和后续特征重采样步骤,所有计算封装在单一网络中。在 300×300 输入下,SSD 在 VOC2007 test 上达到 74.3% mAP、59 FPS;在 512×512 输入下达到 76.8% mAP,超过同期 Faster R-CNN(73.2% mAP, 7 FPS)。
核心论点:通过在不同分辨率的特征图上密铺多尺度默认框并同时预测类别与位置,SSD 首次证明单阶段检测器可以在速度和精度上同时超越两阶段方法。
问题与动机
2016 年目标检测的主流范式是两阶段方法:先生成区域提议,再对每个提议进行分类和回归。这种流程精度高但速度慢。
| 方法类型 | 代表作 | 核心问题 | VOC07 mAP | 速度 |
|---|---|---|---|---|
| 两阶段 | Faster R-CNN | 提议生成+特征重采样,7 FPS | 73.2% | 慢 |
| 单阶段(粗粒度) | YOLO | 仅用最顶层特征图,空间分辨率低 | 63.4% | 45 FPS |
核心痛点:单阶段检测器虽快但精度差 10+ 个点,关键瓶颈在于缺乏多尺度表示和系统化的默认框设计。
核心洞察
洞察 1:多尺度特征图联合预测
传统做法:YOLO 仅在最顶层特征图(7×7)上做预测,小目标信息严重丢失。Faster R-CNN 虽有 RPN 但需要后续 ROI Pooling。
本文做法:在 VGG-16 的多个中间层(conv4_3、fc7 以及额外添加的 conv6_2、conv7_2、conv8_2、conv9_2)上分别做预测,特征图尺寸从 38×38 到 1×1,自然覆盖从小到大的目标。
每个预测层对应不同的默认框尺度,通过线性插值公式确定:
$$s_k = s_{\min} + \frac{s_{\max} - s_{\min}}{m - 1}(k - 1), \quad k \in [1, m]$$其中 $s_{\min} = 0.2$,$s_{\max} = 0.9$,$m$ 为预测层数目。
这样做更好的原因:不同层的感受野天然匹配不同尺度的目标,低层高分辨率特征图捕捉小目标细节,高层低分辨率特征图覆盖大目标的全局信息。
洞察 2:默认框的系统化密铺
传统做法:YOLO 每个网格只预测 2 个框,Faster R-CNN 虽有 anchor 但仅在单一特征图上生成。
本文做法:在每个预测层的每个位置放置一组不同宽高比的默认框。宽高比取 $a_r \in {1, 2, 3, \frac{1}{2}, \frac{1}{3}}$,对 $a_r=1$ 还额外增加尺度 $s’k = \sqrt{s_k \cdot s{k+1}}$ 的框,每个位置最多 6 个默认框。每个默认框预测 $(c + 4)$ 个值($c$ 个类别得分 + 4 个位置偏移),总输出大小为 $(c+4) \times k \times m \times n$。
SSD300 总共生成 8732 个默认框($38^2 \times 4 + 19^2 \times 6 + 10^2 \times 6 + 5^2 \times 6 + 3^2 \times 4 + 1^2 \times 4$),远多于 YOLO 的 98 个或 Faster R-CNN 的约 6000 个候选区域。
洞察 3:数据增强作为多尺度训练的替代
传统做法:Fast/Faster R-CNN 仅使用原图和水平翻转。也有方法通过图像金字塔处理多尺度,但计算量大。
本文做法:采用激进的数据增强策略——随机裁剪(zoom in)要求与目标的最小 IoU 达到 {0.1, 0.3, 0.5, 0.7, 0.9},以及随机扩展(zoom out,将图像放在 16× 大小的画布上)。这等效于在训练时模拟了多尺度目标。
论文消融实验表明数据增强带来 8.8% mAP 的巨大提升(65.5% → 74.3%),是所有组件中增益最大的。
三个关键数字:
- 74.3% mAP / 59 FPS:SSD300 在 VOC2007 test 上的性能(07+12 训练),首个超过 70% mAP 的实时检测器
- 8732:SSD300 每张图像生成的默认框总数,密铺确保了高召回率
- **8.8%**:数据增强策略带来的 mAP 提升幅度,体现了训练策略的关键作用
方法设计
4.1 整体架构
SSD 的核心流程:
$$\text{Image} \xrightarrow{\text{VGG-16 (truncated)}} \text{Multi-scale Feature Maps} \xrightarrow{3 \times 3 \text{ Conv}} \text{(scores, offsets)} \xrightarrow{\text{NMS}} \text{Detections}$$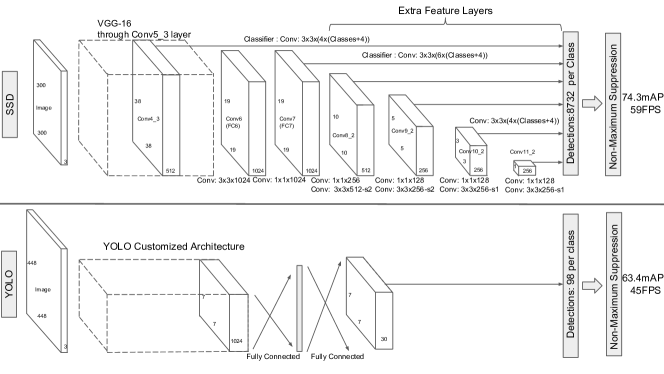
Input (300×300×3)
│
▼
┌──────────────────────┐
│ VGG-16 Base │
│ (conv1 ~ conv5) │
│ pool5: 3×3-s1 │
│ fc6 → conv (atrous) │
│ fc7 → conv │
└────────┬─────────────┘
│
┌────┴────────────────────────────────────┐
│ Multi-scale Feature Maps │
│ │
│ conv4_3 ──→ 38×38 ──→ 4 boxes/loc │
│ fc7 ──→ 19×19 ──→ 6 boxes/loc │
│ conv6_2 ──→ 10×10 ──→ 6 boxes/loc │
│ conv7_2 ──→ 5×5 ──→ 6 boxes/loc │
│ conv8_2 ──→ 3×3 ──→ 4 boxes/loc │
│ conv9_2 ──→ 1×1 ──→ 4 boxes/loc │
│ │
│ 每个位置: 3×3 conv → (c+4)×k 通道 │
└────────────┬────────────────────────────┘
│
▼
NMS (IoU=0.45, top-200) → 检测结果
4.2 关键组件
多尺度预测层配置:
| 预测层 | 特征图尺寸 | 默认框数 | 宽高比 | 步长 |
|---|---|---|---|---|
| conv4_3 | 38×38 | 4 | {1, 2, 1/2, 1’} | 8 |
| fc7 | 19×19 | 6 | {1, 2, 3, 1/2, 1/3, 1’} | 16 |
| conv6_2 | 10×10 | 6 | {1, 2, 3, 1/2, 1/3, 1’} | 32 |
| conv7_2 | 5×5 | 6 | {1, 2, 3, 1/2, 1/3, 1’} | 64 |
| conv8_2 | 3×3 | 4 | {1, 2, 1/2, 1’} | 100 |
| conv9_2 | 1×1 | 4 | {1, 2, 1/2, 1’} | 300 |
注:1’ 表示额外添加的尺度 $s’k = \sqrt{s_k \cdot s{k+1}}$ 对应的 aspect ratio = 1 的框。conv4_3 单独使用 L2 归一化(scale=20)。
总损失函数:
$$L(x, c, l, g) = \frac{1}{N}\left(L_{\text{conf}}(x, c) + \alpha \cdot L_{\text{loc}}(x, l, g)\right)$$其中 $N$ 为匹配的默认框数量,$\alpha = 1$。
定位损失(Smooth L1):
$$L_{\text{loc}} = \sum_{i \in \text{Pos}} \sum_{m \in \{cx,cy,w,h\}} x_{ij}^k \cdot \text{smooth}_{L1}(l_i^m - \hat{g}_j^m)$$分类损失(Softmax CE + Hard Negative Mining,neg:pos = 3:1):
$$L_{\text{conf}} = -\sum_{i \in \text{Pos}} x_{ij}^p \log(\hat{c}_i^p) - \sum_{i \in \text{Neg}} \log(\hat{c}_i^0)$$4.3 关键代码
从官方 Caffe 仓库中提取的关键代码。
模型架构配置:预测层定义与默认框参数
(来源:examples/ssd/ssd_pascal.py)
📄 点击展开 SSD 模型配置代码
# 参数设置:多尺度预测层定义 |
默认框生成:PriorBoxLayer 的核心逻辑
(来源:src/caffe/layers/prior_box_layer.cpp)
📄 点击展开 PriorBoxLayer Forward 代码
// 遍历特征图每个位置,为每个位置生成一组默认框 |
实验与分析
5.1 主要结果
PASCAL VOC2007 test:
| 方法 | Backbone | 训练数据 | mAP | FPS | 默认框数 |
|---|---|---|---|---|---|
| Fast R-CNN | VGG-16 | 07+12 | 70.0% | ~3 | ~2000 |
| Faster R-CNN | VGG-16 | 07+12 | 73.2% | 7 | ~6000 |
| YOLO | 自定义 | 07+12 | 63.4% | 45 | 98 |
| SSD300 | VGG-16 | 07+12 | 74.3% | 59 | 8732 |
| SSD512 | VGG-16 | 07+12 | 76.8% | 22 | 24564 |
| SSD300* | VGG-16 | 07+12 | 77.2% | 46 | 8732 |
| SSD512* | VGG-16 | 07+12 | 79.8% | 19 | 24564 |
注:SSD300*/SSD512* 为加入”expand”数据增强后的版本。
COCO test-dev 2015:
| 方法 | AP@[.5:.95] | AP@.5 | AP@.75 | AP_S | AP_M | AP_L |
|---|---|---|---|---|---|---|
| Faster R-CNN | 24.2 | 45.3 | 23.5 | 7.7 | 26.4 | 37.1 |
| SSD300 | 23.2 | 41.2 | 23.4 | 5.3 | 23.2 | 39.6 |
| SSD512 | 26.8 | 46.5 | 27.8 | 9.0 | 28.9 | 41.9 |
关键发现:
- SSD300 是首个同时达到 70%+ mAP 和实时速度的检测器
- SSD512 在精度上全面超越 Faster R-CNN,同时速度快 3×
- SSD 在大目标上表现优异,但小目标仍是瓶颈(AP_S 远低于 AP_L)
5.2 消融实验:验证三个洞察
组件消融(VOC2007 test, SSD300, 07+12 训练):
| 配置 | mAP | 验证洞察 |
|---|---|---|
| 基线(无数据增强,仅 {1/3, 3} box) | 65.5% | — |
| + 数据增强 | 71.6% (+6.1) | 洞察 3 |
| + 添加 {1/3, 3} 宽高比 | 73.7% (+2.1) | 洞察 2 |
| + 使用 atrous VGG | 74.3% (+0.6) | — |
多尺度预测层消融:
| 使用的预测层数 | 预测层 | mAP (含边界框) | mAP (不含边界框) | 验证洞察 |
|---|---|---|---|---|
| 6 层 | conv4_3 ~ conv9_2 | 74.3% | 63.4% | 洞察 1 |
| 5 层 | conv4_3 ~ conv8_2 | 74.6% | 63.1% | 洞察 1 |
| 4 层 | conv4_3 ~ conv7_2 | 73.8% | 68.4% | 洞察 1 |
| 3 层 | conv4_3 ~ conv6_2 | 70.7% | 69.2% | 洞察 1 |
| 1 层 | fc7 | 62.4% | 64.0% | 洞察 1 |
注:去除层时调整默认框分配保持总数约 8732。单用 fc7 性能最差,验证了多尺度分布预测的关键性。
5.3 性能瓶颈分析
论文使用检测分析工具发现:
- 小目标检测差:小目标在高层特征图上可能完全没有信息,SSD 在 XS/S 级别 BBox 上性能明显低于 M/L/XL
- 类别混淆:由于多类别共享位置预测,SSD 在相似类别间的混淆(尤其是动物类)高于 R-CNN
- 定位精度高于 R-CNN:直接回归框位置优于两步解耦方法
5.4 失效场景分析
- 极小目标:在最高分辨率特征图 conv4_3(38×38)上默认框尺度仍为 30 像素,更小的目标难以检测
- 相似外观的不同类别:如猫 vs 狗,共享检测位置导致混淆
- 高密度重叠场景:当多个目标聚集在同一位置时,固定数量的默认框可能不足以覆盖所有目标
- 极端宽高比目标:虽然有 {1/3, 3} 等宽高比,但超出预设范围的长条形目标仍难以匹配
工程实践
6.1 训练配置
Backbone: VGG-16(ImageNet 预训练,fc6/fc7 转卷积,atrous) |
6.2 复现要点
- conv4_3 的 L2 归一化:conv4_3 特征尺度与其他层差异大,必须用 L2 归一化(初始 scale=20,可学习),否则训练不稳定
- Hard Negative Mining 比例:neg:pos = 3:1 是关键平衡点,比使用所有负样本或 OHEM 更稳定
- 数据增强不可省略:随机裁剪+扩展带来 8.8% mAP 提升,是 SSD 方法的核心组成部分
- 默认框匹配策略:先最大 IoU 匹配,再将 IoU > 0.5 的所有默认框都匹配(而非只取最佳),这简化了学习问题
- atrous 卷积加速:将 pool5 改为 3×3-s1 并在 fc6 上使用 atrous 卷积,精度不变速度提升约 20%
6.3 性能优化方向
精度提升:
- 使用更强的 backbone(如 ResNet)替换 VGG-16,可能提升特征质量但需调整多尺度层
- 引入特征融合(如 FPN)补充低层语义信息和高层空间信息
速度优化:
- VGG-16 占用约 80% 前向时间,替换为轻量级 backbone(如 MobileNet)可显著加速
- NMS 耗时约 1.7ms/image,可通过提高置信度阈值减少候选框
研究启示
7.1 可迁移的思想
- 多尺度特征图联合预测:在不同分辨率的特征图上分别检测不同大小目标的思想,直接启发了 FPN 和后续所有多尺度检测架构
- 默认框系统化设计:通过公式化的尺度和宽高比分配覆盖目标空间,这一思想延续到 RetinaNet 的 anchor 设计
- 数据增强即多尺度训练:用裁剪/扩展模拟目标尺度变化,成本远低于图像金字塔,广泛应用于后续检测器
- 单阶段端到端检测:证明去除提议机制的单阶段方法可以通过密集采样弥补精度差距
7.2 方法局限
- 小目标检测能力不足,低层特征语义信息弱
- 默认框参数需要针对不同数据集手动调优
- 依赖 VGG-16 的计算体量较大(约占 80% 推理时间)
7.3 技术影响
- 确立了”多尺度特征图 + anchor / default box + 单阶段预测”的检测范式,FPN、RetinaNet 等均沿此思路发展
- 在工业部署中被广泛采用,因其简洁的端到端结构容易适配嵌入式硬件
- 与 YOLO 共同推动了实时目标检测的研究热潮
- Hard Negative Mining 的 3:1 比例策略被后续(如 RetinaNet 的 focal loss)从另一角度优化