Task: 2D 目标检测
Method: Focal Loss + FPN + Anchor Boxes
Venue: ICCV
Year: 2017
Paper: https://arxiv.org/abs/1708.02002
Code: https://github.com/facebookresearch/Detectron
摘要
RetinaNet 系统性地研究了单阶段检测器精度落后于两阶段方法的根本原因,发现核心障碍是训练过程中前景-背景的极端类别不平衡(约 1:1000)。本文提出 Focal Loss,通过在标准交叉熵中引入调制因子 $(1 - p_t)^\gamma$ 自动降低易分类样本的损失权重,使训练聚焦于少量困难样本。基于 Focal Loss,作者设计了简洁的 RetinaNet 检测器(ResNet-FPN backbone + 分类/回归双子网络),首次使单阶段检测器在 COCO 上超越所有两阶段方法,达到 39.1 AP(ResNet-101-FPN),最优变体达 40.8 AP(ResNeXt-101-FPN)。
核心论点:单阶段检测器精度低的根因不在于网络架构而在于类别不平衡——Focal Loss 通过可微的损失重塑解决了这一根本问题,使简单的密集检测器即可达到 SOTA 精度。
问题与动机
2017 年检测领域的核心矛盾是:两阶段方法精度高但速度慢,单阶段方法速度快但精度差 10+ AP。
| 方法类型 | 代表作 | COCO AP | 处理类别不平衡的方式 | 核心问题 |
|---|---|---|---|---|
| 两阶段 | Faster R-CNN + FPN | 36.2 | 提议级联 + 1:3 采样 | 速度慢 (172ms) |
| 单阶段 | SSD513 | 31.2 | Hard Negative Mining 3:1 | 易分负样本淹没梯度 |
| 单阶段 | YOLOv2 | 21.6 | 启发式采样 | 精度差距大 |
核心痛点:单阶段检测器在每张图上评估约 100k 个候选位置,其中绝大多数为易分类的背景样本(easy negatives)。这些样本虽然单个损失小,但数量庞大,累积起来主导了总损失和梯度,导致模型退化。
核心洞察
洞察 1:类别不平衡是单阶段检测器的核心瓶颈
传统观点认为单阶段检测器精度低于两阶段方法是因为网络架构不够强或缺少精细的特征对齐。
本文发现:真正的瓶颈是训练时的极端类别不平衡。两阶段方法通过提议级联(将 100k 候选缩减至 1-2k)和硬编码采样比例(1:3 正负比)隐式解决了这一问题。单阶段方法的 OHEM 或 Hard Negative Mining 策略虽有帮助,但完全丢弃了易分样本的信息。
洞察 2:Focal Loss 的动态损失重塑
传统做法:使用 α-balanced CE 手动设定正负样本权重,或用 OHEM 选取 top-k 困难样本。前者无法区分难易样本,后者完全丢弃了易分样本。
本文做法:在标准交叉熵中引入调制因子 $(1 - p_t)^\gamma$,构造 Focal Loss:
$$\text{FL}(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t)$$其中 $p_t$ 是模型对真实类别的预测概率。关键性质:
- 当样本被正确分类($p_t \to 1$),调制因子趋近 0,损失自动衰减
- 当样本被误分类($p_t$ 小),调制因子近 1,损失保持不变
- $\gamma = 2$ 时,$p_t = 0.9$ 的样本损失降低 100×,$p_t \approx 0.968$ 的样本降低 1000×
最优参数为 $\gamma = 2, \alpha = 0.25$。当 $\gamma$ 增大时 $\alpha$ 应适当减小(因易分负样本已被降权,正样本权重无需太高)。
洞察 3:简洁架构 + 正确的损失函数 > 复杂的采样策略
传统做法:设计复杂的网络结构(如 R-FCN 的位置敏感 score maps、DSSD 的反卷积模块)或繁琐的训练策略(OHEM 需要额外的 NMS 和 batch 构造)来提升单阶段检测器。
本文做法:使用标准的 ResNet-FPN backbone + 两个参数不共享的 FCN 子网络(分类 4 层 3×3 conv + 回归 4 层 3×3 conv),架构极其简洁。在所有约 100k 个 anchor 上直接计算 Focal Loss,无需任何采样策略。
RetinaNet-101-800 达到 37.8 AP(minival)/ 39.1 AP(test-dev),超越 Faster R-CNN + FPN 的 36.2 AP,而 OHEM 最优配置仅 32.8 AP,相差 3.2 AP。
三个关键数字:
- 39.1 AP:RetinaNet(ResNet-101-FPN)在 COCO test-dev 上的性能,首次单阶段超越所有两阶段方法
- **$\gamma = 2$**:Focal Loss 的最优聚焦参数,使 $p_t = 0.9$ 的易分样本损失降低 100×
- 100k:每张图约 100k 个 anchor 全部参与 Focal Loss 计算,无需采样
方法设计
4.1 整体架构
RetinaNet 的核心流程:
$$\text{Image} \xrightarrow{\text{ResNet + FPN}} \{P_3, P_4, P_5, P_6, P_7\} \xrightarrow{\substack{\text{Cls Subnet} \\ \text{Box Subnet}}} \text{(scores, deltas)} \xrightarrow{\text{NMS}} \text{Detections}$$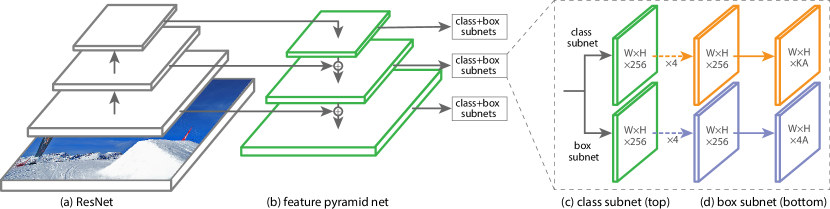
Input Image
│
▼
┌─────────────────────────┐
│ ResNet-50/101 Backbone │
│ (ImageNet pretrained) │
└────────┬────────────────┘
│
▼
┌─────────────────────────┐
│ Feature Pyramid Network│
│ P3 ~ P7 (C=256 each) │
│ P3: stride 8 │
│ P7: stride 128 │
└────────┬────────────────┘
│
┌────┴────┐
▼ ▼
┌────────┐ ┌────────┐
│Cls Sub │ │Box Sub │ ← 参数不共享
│4×3×3 │ │4×3×3 │ ← 参数跨层共享
│conv │ │conv │
│+ReLU │ │+ReLU │
│ │ │ │
│3×3 out │ │3×3 out │
│K×A ch │ │4×A ch │
│sigmoid │ │linear │
└───┬────┘ └───┬────┘
│ │
└────┬─────┘
▼
NMS (IoU=0.5, top-1k/level)
→ 最终检测结果
4.2 关键组件
Anchor 配置:
| FPN 层 | 分辨率 | Anchor 面积 | 子尺度 | 宽高比 | Anchor 数/位置 |
|---|---|---|---|---|---|
| P3 | stride 8 | 32² | {2⁰, 2^(1/3), 2^(2/3)} | {1:2, 1:1, 2:1} | 9 |
| P4 | stride 16 | 64² | 同上 | 同上 | 9 |
| P5 | stride 32 | 128² | 同上 | 同上 | 9 |
| P6 | stride 64 | 256² | 同上 | 同上 | 9 |
| P7 | stride 128 | 512² | 同上 | 同上 | 9 |
每个位置 $A = 9$ 个 anchor,覆盖 32 ~ 813 像素。匹配阈值:IoU ≥ 0.5 为正样本,≤ 0.4 为负样本,中间忽略。
分类子网络:4 层 3×3 conv(C=256,各接 ReLU)→ 3×3 conv 输出 K×A 通道 → sigmoid
回归子网络:结构与分类子网络相同,输出 4×A 通道,class-agnostic
Focal Loss(分类损失):
$$\text{FL}(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t), \quad \gamma = 2, \alpha = 0.25$$回归损失:标准 Smooth L1
分类头初始化:最后一层偏置 $b = -\log((1 - \pi) / \pi)$,$\pi = 0.01$,确保训练初期前景预测概率低(约 1%),防止大量背景 anchor 产生不稳定的大损失。
4.3 关键代码
从 Detectron2(官方代码后续版本)中提取的 RetinaNet 核心实现。
RetinaNetHead:分类和回归子网络
(来源:detectron2/modeling/meta_arch/retinanet.py)
📄 点击展开 RetinaNetHead 代码
class RetinaNetHead(nn.Module): |
Focal Loss 计算与损失汇总
(来源:detectron2/modeling/meta_arch/retinanet.py)
📄 点击展开 RetinaNet losses 代码
def losses(self, anchors, pred_logits, gt_labels, pred_anchor_deltas, gt_boxes): |
实验与分析
5.1 主要结果
COCO test-dev 结果:
| 方法 | Backbone | AP | AP₅₀ | AP₇₅ | AP_S | AP_M | AP_L |
|---|---|---|---|---|---|---|---|
| Faster R-CNN+++ | ResNet-101-C4 | 34.9 | 55.7 | 37.4 | 15.6 | 38.7 | 50.9 |
| Faster R-CNN w FPN | ResNet-101-FPN | 36.2 | 59.1 | 39.0 | 18.2 | 39.0 | 48.2 |
| YOLOv2 | DarkNet-19 | 21.6 | 44.0 | 19.2 | 5.0 | 22.4 | 35.5 |
| SSD513 | ResNet-101-SSD | 31.2 | 50.4 | 33.3 | 10.2 | 34.5 | 49.8 |
| DSSD513 | ResNet-101-DSSD | 33.2 | 53.3 | 35.2 | 13.0 | 35.4 | 51.1 |
| RetinaNet | ResNet-101-FPN | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| RetinaNet | ResNeXt-101-FPN | 40.8 | 61.1 | 44.1 | 24.1 | 44.2 | 51.2 |
关键发现:
- RetinaNet 以 5.9 AP 的优势超越最佳单阶段方法 DSSD(39.1 vs 33.2)
- 以 2.3 AP 超越最佳两阶段方法 Faster R-CNN + TDM(39.1 vs 36.8)
- 使用 ResNeXt-101 backbone 可进一步达到 40.8 AP
5.2 消融实验:验证三个洞察
Focal Loss 参数消融(ResNet-50-FPN, 600px, minival):
| $\gamma$ | $\alpha$ | AP | AP₅₀ | AP₇₅ | 验证洞察 |
|---|---|---|---|---|---|
| 0 (CE) | 0.75 | 31.1 | 49.4 | 33.0 | 洞察 1 |
| 0.5 | 0.50 | 32.9 | 51.7 | 35.2 | 洞察 2 |
| 1.0 | 0.25 | 33.7 | 52.0 | 36.2 | 洞察 2 |
| 2.0 | 0.25 | 34.0 | 52.5 | 36.5 | 洞察 2 |
| 5.0 | 0.25 | 32.2 | 49.6 | 34.8 | 洞察 2 |
Focal Loss vs OHEM(ResNet-101, minival):
| 方法 | 配置 | AP | 验证洞察 |
|---|---|---|---|
| Focal Loss | γ=2, α=0.25 | 36.0 | 洞察 3 |
| OHEM | batch=128, nms=0.5 | 32.8 | 洞察 3 |
| OHEM 1:3 | batch=128, nms=0.5 | 31.1 | 洞察 3 |
注:Focal Loss 比最优 OHEM 高 3.2 AP,且无需调节 NMS 阈值和 batch 大小。
Anchor 密度消融:
| 尺度数 | 宽高比数 | Anchor/位置 | AP | 验证洞察 |
|---|---|---|---|---|
| 1 | 1 | 1 | 30.3 | 洞察 3 |
| 2 | 3 | 6 | 34.2 | 洞察 3 |
| 3 | 3 | 9 | 34.0 | 洞察 3 |
注:增加到 6-9 anchor/位置后性能饱和,说明密集采样有上限。
5.3 性能瓶颈分析
- 小目标仍有改进空间:AP_S = 21.8 远低于 AP_L = 50.2,尽管 FPN 已改善了多尺度问题
- 高 IoU 精度突出:AP₇₅ = 42.3,Focal Loss 对定位精度同样有帮助
- 推理速度与精度的权衡:ResNet-101-800(198ms)精度最高,ResNet-50-500(72ms)在速度优先场景更实用
5.4 失效场景分析
- 极端类别不平衡以外的场景:当正负样本比例较均衡时,Focal Loss 与 CE 差异不大
- γ 过大时的过拟合:γ=5 性能下降,过度忽略半困难样本可能导致欠拟合
- 高密度小目标:FPN 的最低层 P3(stride=8)对极小目标的分辨率仍有限
工程实践
6.1 训练配置
Backbone: ResNet-50/101-FPN(ImageNet 预训练) |
6.2 复现要点
- 分类头 bias 初始化:$b = -\log((1-\pi)/\pi)$, $\pi = 0.01$,这是训练能收敛的前提;不设置此初始化会导致训练发散
- Focal Loss 数值稳定性:将 sigmoid 和 log 操作合并实现(log-sum-exp trick),避免 $\log(0)$ 数值问题
- α 与 γ 的耦合:γ 增大时应减小 α,推荐组合 γ=2/α=0.25;不调 α 会损失约 0.4 AP
- 损失归一化:用匹配到正样本的 anchor 数量(而非总 anchor 数)归一化总损失,使用 EMA 平滑
- 推理优化:每个 FPN 层取 top-1k(置信度 > 0.05),再 NMS(IoU=0.5),最终保留 top-100
6.3 性能优化方向
精度提升:
- 使用更强 backbone(如 ResNeXt-101)可从 39.1 提升至 40.8 AP
- 增加 scale jitter + 延长训练(1.5×)可额外提升 1.3 AP
速度优化:
- 减小输入分辨率(800→500)可将推理时间从 198ms 降至 90ms,AP 从 37.8 降至 34.4
- 使用 ResNet-50 替代 ResNet-101 在相同分辨率下速度提升约 20%
研究启示
7.1 可迁移的思想
- 损失函数重塑解决类别不平衡:Focal Loss 的思想被广泛应用于分割(Dice Loss)、点云检测、3D 检测等所有存在类别不平衡的任务
- 简单架构 + 正确训练 > 复杂架构:RetinaNet 架构极其标准,全部增益来自损失函数设计,这一理念影响了后续研究方法论
- 调制因子的通用设计模式:$(1 - p_t)^\gamma$ 这种自适应降权思想可推广到任何需要聚焦困难样本的场景
- 先验初始化稳定训练:$b = -\log((1-\pi)/\pi)$ 的初始化策略在极端不平衡分类中被广泛采用
7.2 方法局限
- Focal Loss 对 γ 不太敏感([0.5, 5] 均有效),但极端值仍可能导致欠/过拟合
- 仍依赖 anchor-based 框架,后续 anchor-free 方法(FCOS 等)提供了更简洁的替代
- 两个子网络参数量较大,不如共享参数的变体轻量
7.3 技术影响
- 终结了”单阶段 vs 两阶段精度差距”的固有认知,开启了高精度单阶段检测的时代
- Focal Loss 成为目标检测领域的标准组件,几乎所有后续检测器都直接或间接受益
- RetinaNet 的 FPN + anchor + subnet 架构成为后续 anchor-based 单阶段检测器(如 ATSS、GFL)的通用基线
- 论文的分析方法论(CDF 分析损失分布)为理解分类损失函数提供了经典范例