Task: 2D 目标检测
Method: BiFPN + Compound Scaling + EfficientNet
Venue: CVPR
Year: 2020
Paper: https://arxiv.org/abs/1911.09070
Code: https://github.com/google/automl/tree/master/efficientdet
摘要
EfficientDet 系统性地研究了目标检测中的网络架构设计选择,提出两项关键优化:(1)加权双向特征金字塔网络(BiFPN),通过可学习权重实现快速多尺度特征融合;(2)复合缩放方法,用单一系数 $\phi$ 同时缩放 backbone、特征网络、预测头的宽度/深度以及输入分辨率。结合 EfficientNet backbone,作者开发了 D0~D7x 共 8 个级别的检测器,在全资源谱段上均显著优于前作。EfficientDet-D7x 以 77M 参数和 410B FLOPs 达到 55.1 AP(COCO test-dev),比 AmoebaNet + NAS-FPN 高 4 AP 且小 2.7×、快 7.4×。
核心论点:高效检测的核心不在于单一维度的优化,而在于多尺度融合(BiFPN)与全维度联合缩放(compound scaling)的系统性设计——EfficientDet 证明了小模型也可以达到大模型的精度。
问题与动机
2020 年目标检测领域面临精度与效率的矛盾:SOTA 模型体量巨大,部署困难。
| 方法 | COCO AP | 参数量 | FLOPs | 核心问题 |
|---|---|---|---|---|
| AmoebaNet + NAS-FPN + AA | 50.7 | 209M | 3045B | 体量太大,不可部署 |
| RetinaNet (ResNet-101) | 39.9 | 53M | 127B | 效率一般 |
| YOLOv3 | 33.0 | — | 71B | 精度较低 |
| NAS-FPN (ResNet-50) | 44.2 | 60M | 360B | NAS 搜索昂贵,结构不规则 |
核心痛点:如何构建一个可伸缩的检测架构,在 3B~400B FLOPs 的全资源范围内均实现最优精度-效率平衡?现有方法仅单维度缩放(换更大 backbone 或增大输入),未考虑各组件的联合优化。
核心洞察
洞察 1:加权双向特征融合(BiFPN)
传统做法:FPN 仅有自顶向下的单向信息流;PANet 增加了自底向上路径但参数多;NAS-FPN 用搜索找拓扑但结构不规则、搜索代价高。所有这些方法对不同分辨率的输入特征一视同仁地求和。
本文做法:BiFPN 做了三项优化——(1)去除只有单输入的节点(贡献少);(2)在同层增加跳连边(输入到输出的快捷路径);(3)将双向路径作为一个 layer 重复多次。更关键的是引入快速归一化融合(Fast Normalized Fusion):
$$O = \sum_i \frac{w_i}{\epsilon + \sum_j w_j} \cdot I_i, \quad w_i \geq 0$$其中 $w_i$ 通过 ReLU 保证非负,$\epsilon = 0.0001$。这比 softmax 融合快 26-31%,精度几乎无损。
消融实验证实:BiFPN(带权重)在相同 backbone 下相比 FPN 提升约 7 AP(37.0 → 44.4),同时参数减少 65%,FLOPs 减少 75%。
洞察 2:复合缩放(Compound Scaling)
传统做法:检测器缩放通常只调单一维度——换更大 backbone、增大输入分辨率、或堆叠更多 FPN 层。各维度独立调优效率低。
本文做法:用单一复合系数 $\phi$ 同时控制所有维度:
$$W_{\text{bifpn}} = 64 \cdot (1.35^\phi), \quad D_{\text{bifpn}} = 3 + \phi$$ $$D_{\text{box}} = D_{\text{class}} = 3 + \lfloor \phi / 3 \rfloor$$ $$R_{\text{input}} = 512 + \phi \cdot 128$$Backbone 则直接复用 EfficientNet-B0~B6 的缩放。$\phi = 0$ 得到 D0(512 输入,3 层 BiFPN,64 通道),$\phi = 7$ 得到 D7(1536 输入,8 层 BiFPN,384 通道)。
洞察 3:EfficientNet 作为高效 Backbone
传统做法:大多数检测器使用 ResNet/ResNeXt 作为 backbone,这些网络为分类设计,用于检测时效率不是最优。
本文做法:采用 EfficientNet 作为 backbone,它本身就通过复合缩放实现了分类任务上的高效性。替换 backbone 从 ResNet-50 到 EfficientNet-B3 即可在参数更少的情况下提升约 3 AP(37.0 → 40.3)。
三个关键数字:
- 55.1 AP:EfficientDet-D7x 在 COCO test-dev 上的 SOTA 精度,77M 参数 / 410B FLOPs
- 28×:EfficientDet-D0(33.8 AP)相比 YOLOv3(33.0 AP)减少的 FLOPs 倍数
- 44.4 vs 37.0 AP:EfficientNet-B3 + BiFPN 对比 ResNet-50 + FPN 的精度提升,参数和 FLOPs 均更少
方法设计
4.1 整体架构
$$\text{Image} \xrightarrow{\text{EfficientNet}} \{P_3,...,P_7\} \xrightarrow{\text{BiFPN} \times N} \text{Fused Features} \xrightarrow{\substack{\text{Class Net} \\ \text{Box Net}}} \text{Detections}$$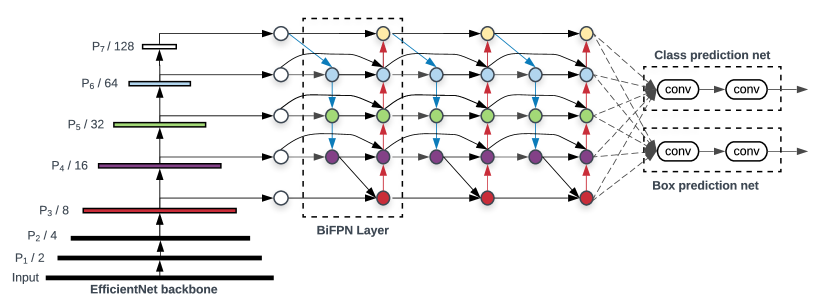
Input (R_input × R_input × 3)
│
▼
┌──────────────────────────┐
│ EfficientNet Backbone │
│ (B0~B6, ImageNet预训练) │
│ 输出: P3, P4, P5 │
└────────┬─────────────────┘
│ + P6, P7 (下采样生成)
▼
┌──────────────────────────┐
│ BiFPN × D_bifpn │
│ ┌──────────────────────┐ │
│ │ Top-Down (td) Path │ │
│ │ P7→P6→P5→P4→P3 │ │
│ │ + 可学习融合权重 │ │
│ ├──────────────────────┤ │
│ │ Bottom-Up (out) Path │ │
│ │ P3→P4→P5→P6→P7 │ │
│ │ + 跳连 + 可学习权重 │ │
│ └──────────────────────┘ │
│ Depthwise Sep Conv + BN │
└─────────┬────────────────┘
│
┌────┴────┐
▼ ▼
┌────────┐ ┌────────┐
│Class │ │Box │ ← 跨层共享参数
│Net │ │Net │
│D_class │ │D_box │
│层 conv │ │层 conv │
│+ BN │ │+ BN │
│+ SiLU │ │+ SiLU │
└───┬────┘ └───┬────┘
└────┬─────┘
▼
Soft-NMS → 检测结果
4.2 关键组件
EfficientDet 缩放配置:
| 模型 | $\phi$ | 输入分辨率 | Backbone | BiFPN 宽度 | BiFPN 深度 | Head 深度 |
|---|---|---|---|---|---|---|
| D0 | 0 | 512 | B0 | 64 | 3 | 3 |
| D1 | 1 | 640 | B1 | 88 | 4 | 3 |
| D2 | 2 | 768 | B2 | 112 | 5 | 3 |
| D3 | 3 | 896 | B3 | 160 | 6 | 4 |
| D4 | 4 | 1024 | B4 | 224 | 7 | 4 |
| D5 | 5 | 1280 | B5 | 288 | 7 | 4 |
| D6 | 6 | 1280 | B6 | 384 | 8 | 5 |
| D7 | 7 | 1536 | B6 | 384 | 8 | 5 |
BiFPN 融合公式(以 P6 为例):
$$P_6^{td} = \text{Conv}\left(\frac{w_1 \cdot P_6^{in} + w_2 \cdot \text{Resize}(P_7^{in})}{w_1 + w_2 + \epsilon}\right)$$ $$P_6^{out} = \text{Conv}\left(\frac{w_1' \cdot P_6^{in} + w_2' \cdot P_6^{td} + w_3' \cdot \text{Resize}(P_5^{out})}{w_1' + w_2' + w_3' + \epsilon}\right)$$损失函数:Focal Loss($\alpha = 0.25, \gamma = 1.5$)+ Smooth L1
4.3 关键代码
从官方 Google AutoML 仓库提取的核心代码。
BiFPN 特征融合:fast normalized fusion 实现
(来源:efficientdet/efficientdet_arch.py)
📄 点击展开 fuse_features 代码
def fuse_features(nodes, weight_method): |
检测头:共享参数的分类和回归网络
(来源:efficientdet/efficientdet_arch.py)
📄 点击展开 class_net 代码
def class_net(images, level, num_classes, num_anchors, num_filters, |
实验与分析
5.1 主要结果
COCO test-dev 结果(单模型单尺度):
| 模型 | AP | AP₅₀ | AP₇₅ | 参数量 | FLOPs | GPU 延迟 |
|---|---|---|---|---|---|---|
| YOLOv3 | 33.0 | 57.9 | 34.4 | — | 71B | — |
| EfficientDet-D0 | 34.6 | 53.0 | 37.1 | 3.9M | 2.5B | 10.2ms |
| RetinaNet (R50) | 39.2 | 58.0 | 42.3 | 34M | 97B | 25ms |
| EfficientDet-D1 | 40.5 | 59.1 | 43.7 | 6.6M | 6.1B | 13.5ms |
| EfficientDet-D4 | 49.7 | 68.4 | 53.9 | 21M | 55B | 42.8ms |
| EfficientDet-D7x | 55.1 | 74.3 | 59.9 | 77M | 410B | 153ms |
关键发现:
- D0 与 YOLOv3 精度相当但 FLOPs 少 28×
- D1 超越 RetinaNet 但参数少 5×、FLOPs 少 16×
- D7x 刷新 COCO 单模型单尺度 SOTA(55.1 AP),比 AmoebaNet + NAS-FPN 高 4 AP 且快 7.4×
5.2 消融实验:验证三个洞察
Backbone 与 BiFPN 解耦消融(RetinaNet 训练设置,COCO val):
| 配置 | AP | 参数量 | FLOPs | 验证洞察 |
|---|---|---|---|---|
| ResNet-50 + FPN | 37.0 | 34M | 97B | — |
| EfficientNet-B3 + FPN | 40.3 (+3.3) | 21M | 75B | 洞察 3 |
| EfficientNet-B3 + BiFPN | 44.4 (+7.4) | 12M | 24B | 洞察 1 + 3 |
特征网络拓扑消融:
| 特征网络 | AP | 参数 (相对) | FLOPs (相对) | 验证洞察 |
|---|---|---|---|---|
| Repeated top-down FPN | 42.29 | 1.0× | 1.0× | 洞察 1 |
| Repeated FPN + PANet | 44.08 | 1.0× | 1.0× | 洞察 1 |
| NAS-FPN | 43.16 | 0.71× | 0.72× | 洞察 1 |
| BiFPN (无权重) | 43.94 | 0.88× | 0.67× | 洞察 1 |
| BiFPN (带权重) | 44.39 | 0.88× | 0.68× | 洞察 1 |
融合方式消融:
| 融合方式 | AP | GPU 速度比 | 验证洞察 |
|---|---|---|---|
| Softmax fusion | 基准 | 1.0× | 洞察 1 |
| Fast normalized fusion | -0.01~-0.11 AP | 1.26×~1.31× | 洞察 1 |
注:Fast normalized fusion 精度几乎无损但速度提升约 30%。
5.3 性能瓶颈分析
- 小模型需要更长训练:EfficientDet-D1 在 300 epoch 时仍未完全饱和,而 RetinaNet 较早趋于稳定
- 大 scale jitter 需要长训练配合:[0.1, 2.0] 的 jitter 在 30 epoch 时反而降低精度,300 epoch 时才显现优势
- 复合缩放 vs 单维度缩放:复合缩放在相同 FLOPs 下始终优于仅缩放分辨率、深度或宽度
5.4 失效场景分析
- 极小目标:尽管 BiFPN 改善了多尺度融合,AP_S 仍显著低于 AP_L
- 超低延迟场景:D0 虽然 FLOPs 极低(2.5B),但 AP 仅 34.6,距高精度需求仍有差距
- NAS 搜索可能找到更优 BiFPN 拓扑:现有 BiFPN 设计基于启发式优化,非全局最优
工程实践
6.1 训练配置
Backbone: EfficientNet-B0~B6(ImageNet 预训练) |
6.2 复现要点
- BiFPN 权重初始化:所有融合权重初始化为 1.0,经 ReLU 保证非负;$\epsilon = 0.0001$ 防止除零
- SiLU 激活函数:使用 $x \cdot \sigma(x)$ 替代 ReLU,对 EfficientNet 和 BiFPN 均有效
- **Scale jitter [0.1, 2.0]**:大范围 jitter 需配合长训练(≥300 epoch),短训练反而降低精度
- EMA:使用 decay=0.9998 的指数移动平均更新模型权重
- Soft-NMS:使用 Soft-NMS 替代标准 NMS 可提升约 0.5 AP
6.3 性能优化方向
精度提升:
- 使用 auto-augmentation 可进一步提升精度(AmoebaNet + AA 提升约 2 AP),但增加训练成本
- D7x 使用更大 backbone(B7)和额外 P8 层,说明探索更深层级仍有空间
速度优化:
- 固定 640×640 分辨率的 D6 可在 34ms 内达到 47.9 AP,适合实时场景
- Depthwise separable conv 是 BiFPN 效率的关键,替换为标准 conv 会显著增加 FLOPs
研究启示
7.1 可迁移的思想
- 加权特征融合:不同尺度特征的重要性不同,可学习的融合权重优于简单求和,该思想可迁移到分割、关键点检测等多尺度任务
- 复合缩放方法论:用单一系数联合控制所有架构维度的方法论,可推广到任何需要模型家族的场景(如 3D 检测、视频理解)
- 高效 backbone 的传导效应:backbone 的效率提升会传导到整个检测管线,选择高效 backbone 是最基本的优化
- Fast normalized fusion 的简洁性:用 ReLU + 简单归一化替代 softmax 的技巧,在需要加权聚合的任何场景都适用
7.2 方法局限
- 复合缩放公式基于启发式搜索,非理论最优
- BiFPN 仍是手工设计的拓扑,NAS 搜索可能找到更好结构
- 训练成本较高(D7/D7x 需要 128 TPUv3 × 600 epoch)
7.3 技术影响
- 确立了”高效 backbone + 加权特征融合 + 复合缩放”的检测器设计范式
- BiFPN 的加权融合思想被广泛采纳到后续工作(如 YOLOv5/v8 的 PANet 变体)
- 复合缩放方法直接影响了 YOLO 系列的模型家族设计(nano/small/medium/large/xlarge)
- 证明了 EfficientNet 在检测任务中的有效性,推动了精度-效率帕累托前沿的改进