Task: Object Detection
Method: Deformable Attention, Multi-Scale Feature, Transformer
Venue: ICLR
Year: 2021
Paper: https://arxiv.org/abs/2010.04159
Code: https://github.com/fundamentalvision/Deformable-DETR
摘要
DETR 通过 Transformer 实现了端到端目标检测,消除了 NMS、anchor 等手工设计组件,但存在两大缺陷:收敛速度极慢(需 500 epochs)和小物体检测性能差。根本原因在于 Transformer 注意力模块处理图像特征图时的固有限制——初始化时注意力近乎均匀分布在所有像素上,需要长时间训练才能聚焦到有意义的稀疏位置;同时全局注意力的二次计算复杂度使其难以处理高分辨率多尺度特征。本文提出 Deformable DETR,其核心是多尺度可变形注意力模块,仅关注参考点周围的少量采样位置,将可变形卷积的稀疏空间采样优势与 Transformer 的关系建模能力相结合。Deformable DETR 以仅 1/10 的训练 epochs 即可超越 DETR 的性能(尤其在小物体上),并在此基础上进一步探索了迭代边界框精化和两阶段检测方案。在 COCO 基准上,该方法使用 ResNeXt-101+DCN 达到 50.1 AP。
核心论点:通过将 Transformer 中的全局密集注意力替换为数据依赖的稀疏可变形注意力,同时原生支持多尺度特征聚合,从根本上解决了 DETR 收敛慢和高分辨率特征处理代价高的问题,使端到端检测器在实用性上迈出关键一步。
问题与动机
DETR 开创了端到端检测范式,但其实用性受限于两个核心问题:
| 问题 | 表现 | 根本原因 |
|---|---|---|
| 收敛慢 | 500 epochs(传统检测器 12-36 epochs) | 初始化时注意力均匀分布于所有像素,需极长时间学习聚焦到稀疏有意义位置 |
| 小物体差 | $AP_S$ 20.5,比 Faster R-CNN 低 6.1 | 自注意力 $O(H^2W^2C)$ 复杂度使高分辨率特征图不可行;缺乏多尺度特征 |
同时,在图像领域已有一种高效的稀疏空间采样机制——可变形卷积(Deformable Convolution),它能有效聚焦于稀疏空间位置,但缺乏 Transformer 的元素间关系建模能力。
核心痛点:DETR 的 Transformer 注意力在图像特征图上计算代价与空间尺寸的平方成正比,且初始化时的均匀注意力导致收敛极其缓慢,亟需一种既保留关系建模能力又具备稀疏高效采样的注意力机制。
核心洞察
洞察 1:数据依赖的稀疏采样替代全局密集注意力
Transformer 的标准多头注意力对所有空间位置计算注意力权重,复杂度为 $O(N_q N_k C)$。但实际上检测任务中每个 query 只需关注少数几个关键位置。
传统做法(DETR):全局自注意力扫描所有 $H \times W$ 个像素 → 初始化均匀 → 需要非常长的训练才能学到稀疏模式
本文做法:每个 query 仅在参考点周围采样 $K$ 个位置($K=4$),采样偏移和注意力权重均由数据驱动预测
可变形注意力公式:
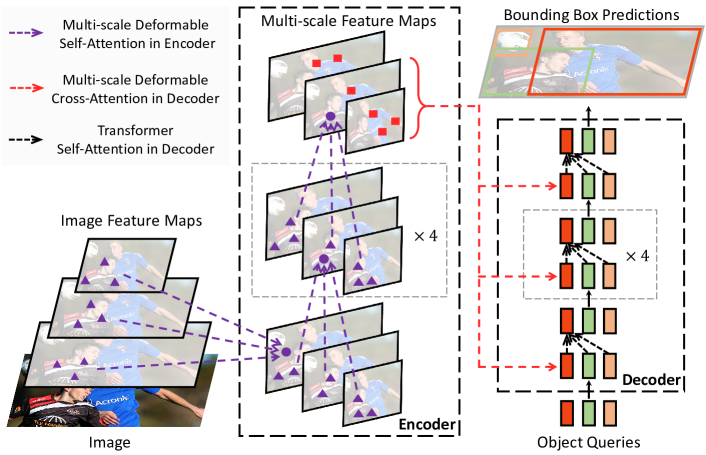
$$\text{DeformAttn}(\boldsymbol{z}_q, \boldsymbol{p}_q, \boldsymbol{x}) = \sum_{m=1}^{M} \boldsymbol{W}_m \left[ \sum_{k=1}^{K} A_{mqk} \cdot \boldsymbol{W}'_m \boldsymbol{x}(\boldsymbol{p}_q + \Delta\boldsymbol{p}_{mqk}) \right]$$ 其中 $\Delta\boldsymbol{p}_{mqk}$ 是学习的采样偏移,$A_{mqk}$ 是预测的注意力权重。复杂度在编码器中降为 $O(HWC^2)$(线性于空间尺寸),在解码器交叉注意力中降为 $O(NKC^2)$(与空间尺寸无关)。为什么更优:稀疏采样的预过滤机制使模型从初始化时就聚焦于参考点附近的局部区域,不再需要从均匀分布中缓慢学习聚焦模式,训练收敛速度提升至 10 倍。
洞察 2:注意力机制原生聚合多尺度特征
现代检测器依赖 FPN 等手工设计的特征金字塔来处理多尺度问题。DETR 由于自注意力的二次复杂度,只能使用单尺度特征(stride 32),导致小物体信息严重丢失。
传统做法(DETR + FPN):先用 FPN 独立构建多尺度特征 → 再在单尺度上做注意力
本文做法:将可变形注意力自然扩展为多尺度版本,每个 query 直接从 $L$ 个尺度的特征图上采样
多尺度可变形注意力公式:
$$\text{MSDeformAttn}(\boldsymbol{z}_q, \hat{\boldsymbol{p}}_q, \{\boldsymbol{x}^l\}_{l=1}^{L}) = \sum_{m=1}^{M} \boldsymbol{W}_m \left[ \sum_{l=1}^{L} \sum_{k=1}^{K} A_{mlqk} \cdot \boldsymbol{W}'_m \boldsymbol{x}^l(\phi_l(\hat{\boldsymbol{p}}_q) + \Delta\boldsymbol{p}_{mlqk}) \right]$$从 $L$ 个尺度共采样 $LK$ 个点(默认 $L=4$,$K=4$,共 16 个点),注意力权重在所有尺度和采样点上归一化:$\sum_{l=1}^{L}\sum_{k=1}^{K} A_{mlqk} = 1$。
为什么更优:多尺度注意力本身即实现了跨尺度信息交换,使 FPN 变得多余(实验证实加 FPN 或 BiFPN 均不提升性能),同时大幅提升小物体检测精度($AP_S$ 从单尺度 21.2 提升至 26.4)。
洞察 3:快速收敛使迭代精化和两阶段方案成为可能
DETR 收敛慢的根本障碍使得探索更复杂的检测方案变得不现实。Deformable DETR 的快速收敛打开了新的可能性。
传统做法(DETR):单次预测,500 epochs 才勉强收敛,无法承受额外模块带来的优化负担
本文做法:利用快速收敛的优势,在 50 epochs 内探索两种增强方案——
- 迭代边界框精化:受光流估计启发,每个解码器层基于上一层预测的边界框进一步精化
- 两阶段方案:编码器先生成区域候选(每个像素作为 query),再由解码器精化 top-$k$ 候选
为什么更优:迭代精化使每层解码器都能做增量修正而非从零预测;两阶段方案让 object queries 从图像相关的候选初始化(而非图像无关的可学习嵌入),两者共同将 COCO test-dev AP 从 43.8 提升至 46.9(R50)。
三个关键数字:
- 10×:Deformable DETR 仅需 DETR 1/10 的训练 epochs(50 vs 500)即可达到更好性能
- 43.8 AP:Deformable DETR(R50,50 epochs)在 COCO val 上超越 DETR-DC5(43.3 AP,500 epochs)
- 50.1 AP:Two-stage Deformable DETR(ResNeXt-101+DCN)在 COCO test-dev 上的最佳结果
方法设计
整体架构
$$\text{Deformable DETR} = \text{CNN Backbone} + \text{Multi-scale Feature Maps} + \text{Deformable Transformer Encoder-Decoder} + \text{Detection Head}$$
输入图像
↓
[3, H₀, W₀]
↓
┌──────────────────────────┐
│ CNN Backbone │
│ ResNet-50 │
└──────────────────────────┘
↓ ↓ ↓ ↓
C₃ C₄ C₅ 3×3 Conv s2
[H/8,W/8] [H/16,W/16] [H/32,W/32] [H/64,W/64]
↓ ↓ ↓ ↓
┌────────────────────────────────────────────┐
│ 1×1 Conv → 256-d + Scale-level Embedding │
│ 展平并拼接为统一序列 │
│ [Σ(Hₗ×Wₗ), 256] │
└────────────────────────────────────────────┘
↓
┌────────────────────────────────────────────┐
│ Deformable Transformer Encoder │
│ 6 层 × (MSDeformAttn + FFN) │
│ 每层参数跨尺度共享 │
│ 自注意力:每个像素在 4 个尺度上各采样 4 点 │
│ 参考点 = 像素自身坐标 │
│ d=256, M=8 heads, K=4, L=4 │
└────────────────────────────────────────────┘
↓
编码器记忆 [Σ(Hₗ×Wₗ), 256]
↓
Object Queries ──→ ┌──────────────────────────────┐
[300, 512] │ Deformable Transformer │
(embedding → │ Decoder │
256 content + │ 6 层 × (Self-Attn + │
256 position) │ MSDeformAttn cross + FFN) │
│ 交叉注意力:从多尺度记忆采样 │
│ 参考点由 query 学习预测 │
└──────────────────────────────┘
↓
[300, 256] 解码器输出
↓
┌──────────────────────┼──────────────────────┐
│ │
↓ ↓
┌─────────────┐ ┌─────────────┐
│ Class Head │ │ BBox Head │
│ Linear │ │ 3-layer MLP │
│ 256 → 91 │ │ 256→256→4 │
│ Focal Loss │ │ + sigmoid │
└─────────────┘ └─────────────┘
↓ ↓
[300, 91] logits [300, 4] boxes
└──────────────────────┼──────────────────────┘
↓
┌────────────────────────────┐
│ 二分图匹配(匈牙利算法) │
│ 预测 ↔ GT 一对一匹配 │
└────────────────────────────┘
↓
输出检测框
关键组件
多尺度特征图构建:
| 特征层 | 来源 | 分辨率 | 变换 |
|---|---|---|---|
| $\boldsymbol{x}^1$ | ResNet C₃ | $H/8 \times W/8$ | 1×1 Conv → 256-d |
| $\boldsymbol{x}^2$ | ResNet C₄ | $H/16 \times W/16$ | 1×1 Conv → 256-d |
| $\boldsymbol{x}^3$ | ResNet C₅ | $H/32 \times W/32$ | 1×1 Conv → 256-d |
| $\boldsymbol{x}^4$ | C₅ output | $H/64 \times W/64$ | 3×3 Conv stride 2 |
注意:不使用 FPN 的自顶向下结构,多尺度可变形注意力本身即实现跨尺度信息交换。
编码器 vs 解码器注意力设计差异:
| 组件 | 编码器自注意力 | 解码器交叉注意力 | 解码器自注意力 |
|---|---|---|---|
| 类型 | MSDeformAttn | MSDeformAttn | 标准多头注意力 |
| Query | 各像素 | Object queries | Object queries |
| Key | 多尺度像素 | 编码器输出 | Object queries |
| 参考点 | 像素自身坐标 | 由 query embedding 学习预测 | — |
预测头设计:
| 预测头 | 结构 | 输出尺寸 | 损失 |
|---|---|---|---|
| 分类头 | Linear(256, 91) | $300 \times 91$ | Focal Loss(权重 2) |
| 边界框头 | 3 层 MLP + Sigmoid | $300 \times 4$ | $\ell_1$ + GIoU |
损失函数与 DETR 类似,采用匈牙利匹配 + 集合预测损失,但分类损失从交叉熵改为 Focal Loss(权重 2),object queries 从 100 增加到 300。
迭代边界框精化:第 $d$ 层解码器基于第 $d-1$ 层预测的边界框 $\hat{\boldsymbol{b}}_q^{d-1}$ 做增量修正:
$$\hat{\boldsymbol{b}}_q^d = \left\{ \sigma\left(\Delta b_{qx}^d + \sigma^{-1}(\hat{b}_{qx}^{d-1})\right),\ \sigma\left(\Delta b_{qy}^d + \sigma^{-1}(\hat{b}_{qy}^{d-1})\right),\ \ldots \right\}$$梯度仅通过 $\Delta \boldsymbol{b}$ 反向传播,阻断于上一层预测 $\hat{\boldsymbol{b}}^{d-1}$,以稳定训练。
关键代码
核心模块分布在以下文件中:
| 函数/类 | 文件 | 功能 |
|---|---|---|
MSDeformAttn |
models/ops/modules/ms_deform_attn.py | 多尺度可变形注意力(核心) |
DeformableTransformer |
models/deformable_transformer.py | 编码器-解码器 Transformer |
DeformableDETR |
models/deformable_detr.py | 主模型:backbone + transformer + 检测头 |
(来源:models/ops/modules/ms_deform_attn.py)
📄 点击展开 MSDeformAttn 代码
class MSDeformAttn(nn.Module): |
(来源:models/deformable_transformer.py)
📄 点击展开 DeformableTransformerEncoderLayer 代码
class DeformableTransformerEncoderLayer(nn.Module): |
(来源:models/deformable_transformer.py)
📄 点击展开 DeformableTransformerDecoderLayer 代码
class DeformableTransformerDecoderLayer(nn.Module): |
实验与分析
主要结果
与 DETR 对比(COCO 2017 val):
| 方法 | Backbone | Epochs | AP | AP$_{50}$ | AP$_{75}$ | AP$_S$ | AP$_M$ | AP$_L$ | FPS |
|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN + FPN | R50 | 109 | 42.0 | 62.1 | 45.5 | 26.6 | 45.4 | 53.4 | 26 |
| DETR-DC5 | R50 | 500 | 43.3 | 63.1 | 45.9 | 22.5 | 47.3 | 61.1 | 12 |
| DETR-DC5 | R50 | 50 | 35.3 | 55.7 | 36.8 | 15.2 | 37.5 | 53.6 | 12 |
| Deformable DETR | R50 | 50 | 43.8 | 62.6 | 47.7 | 26.4 | 47.1 | 58.0 | — |
关键发现:
- 仅用 50 epochs,Deformable DETR 即超越 500 epochs 的 DETR-DC5(43.8 vs 43.3 AP)
- $AP_S$ 从 DETR 的 22.5 大幅提升至 26.4,接近 Faster R-CNN 水平(26.6),多尺度特征功不可没
- 在相同 50 epochs 下,Deformable DETR 领先 DETR-DC5 达 8.5 AP(43.8 vs 35.3)
COCO test-dev SOTA 对比:
| 方法 | Backbone | TTA | AP | AP$_{50}$ | AP$_{75}$ | AP$_S$ | AP$_M$ | AP$_L$ |
|---|---|---|---|---|---|---|---|---|
| FCOS | ResNeXt-101 | — | 44.7 | 64.1 | 48.4 | 27.6 | 47.5 | 55.6 |
| ATSS | ResNeXt-101+DCN | ✓ | 50.7 | 68.9 | 56.3 | 33.2 | 52.9 | 62.4 |
| EfficientDet-D7 | EfficientNet-B6 | — | 52.2 | 71.4 | 56.3 | — | — | — |
| Deformable DETR | R50 | — | 46.9 | 66.4 | 50.8 | 27.7 | 49.7 | 59.9 |
| Deformable DETR | R101 | — | 48.7 | 68.1 | 52.9 | 29.1 | 51.5 | 62.0 |
| Deformable DETR | ResNeXt-101 | — | 49.0 | — | — | — | — | — |
| Deformable DETR | ResNeXt-101+DCN | — | 50.1 | — | — | — | — | — |
| Deformable DETR | ResNeXt-101+DCN | ✓ | 52.3 | — | — | — | — | — |
消融实验:验证三个洞察
可变形注意力设计消融(COCO val):
| 多尺度输入 | 多尺度注意力 | $K$ | FPN | AP | AP$_S$ | AP$_M$ | AP$_L$ | 验证洞察 |
|---|---|---|---|---|---|---|---|---|
| ✗ | ✗ | 1 | ✗ | 39.7 | 21.2 | 44.3 | 56.0 | 洞察 #1 |
| ✓ | ✗ | 1 | ✗ | 41.4 | 24.1 | 44.6 | 56.1 | 洞察 #2 |
| ✓ | ✗ | 4 | ✗ | 42.3 | 24.8 | 45.1 | 56.3 | 洞察 #1 |
| ✓ | ✓ | 4 | ✗ | 43.8 | 26.4 | 47.1 | 58.0 | 洞察 #2 |
| ✓ | ✓ | 4 | FPN | 43.8 | 26.5 | 47.3 | 58.1 | 洞察 #2 |
| ✓ | ✓ | 4 | BiFPN | 43.9 | 25.6 | 47.4 | 57.7 | 洞察 #2 |
消融实验的关键结论:
- 洞察 #1 验证:单尺度 $K=1$(退化为可变形卷积)仅 39.7 AP;增加 $K$ 至 4 提升 +0.9 AP,证实多点采样的价值
- 洞察 #2 验证:从单尺度(42.3)到多尺度注意力(43.8)提升 +1.5 AP,$AP_S$ 提升 +1.6;加 FPN/BiFPN 不再带来提升,证实多尺度注意力已充分交换跨尺度信息
- 从单尺度 $K=1$ 到完整模型,$AP_S$ 累计提升 +5.2(21.2→26.4),验证多尺度特征对小物体的关键作用
性能瓶颈分析
Deformable DETR 大幅缓解了 DETR 的两大瓶颈,但仍存在一些限制:
| 指标 | Deformable DETR(R50) | Faster R-CNN+FPN(R50) | 差距 |
|---|---|---|---|
| AP$_S$ | 26.4 | 26.6 | -0.2(几乎持平) |
| AP$_L$ | 58.0 | 53.4 | +4.6 |
| 训练 epochs | 50 | 109 | 更少 |
- 编码器计算量:虽然注意力降为线性复杂度,但 4 个尺度的特征图总像素数仍较大,编码器 6 层仍有不小的开销
- CUDA 自定义算子依赖:
MSDeformAttnFunction需要编译 CUDA 扩展,跨平台部署不如纯 PyTorch 实现方便 - 两阶段方案的候选数量:两阶段版本中第一阶段每个像素都作为 query 预测候选框,增加了第一阶段的计算负担
失效场景分析
- 极端密集场景:300 个 object queries 虽比 DETR 的 100 个更多,但在极端密集场景(如数百个物体)下仍可能不足
- 采样点覆盖不足:每个 head 每个 level 仅 $K=4$ 个采样点,对极大尺度目标或复杂形状物体可能覆盖不够,需要更多层迭代来补偿
- 小物体仍有差距:虽然 $AP_S$ 大幅提升至 26.4,但与标准注意力模型相比最高分辨率仅为 stride 8(对比 FPN 可到 stride 4),对极小物体的分辨能力仍有限
工程实践
训练配置
Backbone: ResNet-50(ImageNet 预训练) |
复现要点
CUDA 扩展编译:
MSDeformAttn核心算子需要编译 CUDA 扩展(cd models/ops && python setup.py build install),这是性能的关键——纯 PyTorch 版本(ms_deform_attn_core_pytorch)仅用于调试,速度远慢于 CUDA 版本。采样偏移初始化至关重要:采样偏移 bias 初始化为围绕参考点的均匀网格模式(按极角 $2\pi/M$ 分布),不同采样点距离递增。随机初始化会显著降低性能。
参考点预测的学习率:预测采样偏移和参考点的线性层学习率需乘以 0.1(相对于基础 lr),防止训练初期参考点漂移过大。
迭代精化的梯度阻断:迭代边界框精化中,梯度不通过 $\sigma^{-1}(\hat{b}^{d-1})$ 反向传播,仅通过当前层的增量 $\Delta b^d$ 传播,这对训练稳定性至关重要。
scale-level embedding:为区分不同尺度的特征,添加了可学习的 scale-level embedding $\boldsymbol{e}_l$,与位置编码拼加后输入编码器。该嵌入随机初始化、端到端训练。
Focal Loss 替代交叉熵:分类损失从 DETR 的交叉熵改为 Focal Loss(loss weight=2),配合 300 个 queries(比 DETR 多 200 个),更好地处理正负样本不平衡。
性能优化方向
精度提升:
- 更好的 query 初始化策略:如 DAB-DETR 使用 anchor 坐标代替可学习嵌入,进一步加速收敛
- 去噪训练(DN-DETR/DINO):在训练时注入加噪 GT 作为额外 query,显著提升匹配质量和收敛速度
- 更强的 backbone:使用 Swin Transformer 等视觉 backbone 替代 ResNet,可显著提升检测性能
速度优化:
- 减少编码器层数:编码器参数跨尺度共享,实验表明可适当减少层数以节省计算
- 简化两阶段方案:两阶段中第一阶段候选生成可以用更轻量的方式实现
- 算子优化:将 CUDA 自定义算子替换为 PyTorch 2.0+ 原生的高效注意力实现,降低部署复杂度
研究启示
可迁移的思想
可变形注意力作为通用视觉特征聚合模块
多尺度可变形注意力提供了一种在视觉任务中替代标准 Transformer 注意力的高效范式。该模块已被广泛应用于 BEV 感知(BEVFormer)、视频理解、点云处理等领域,成为 3D 检测和自动驾驶感知的核心组件。稀疏注意力解决视觉 Transformer 的效率瓶颈
通过将注意力从 $O(N^2)$ 降至 $O(NK)$,Deformable DETR 证明了视觉 Transformer 不必在全局感受野和效率之间二选一。类似的稀疏注意力思想后续被 Swin Transformer 的 window attention、Neighborhood Attention 等工作各自发展。迭代精化是端到端检测的有效增强范式
每层解码器逐步精化预测的思想后续被 DINO、Co-DETR 等 SOTA 检测器广泛采用,成为 DETR 系列的标准组件。注意力机制可原生替代特征金字塔
Deformable DETR 证明通过合适的注意力设计可以让多尺度信息交换在注意力计算中自然发生,不再需要手工设计的 FPN 结构,简化了检测器的整体架构。
方法局限
- CUDA 自定义算子依赖:核心可变形注意力需要编译 CUDA 扩展,增加了部署和跨平台移植的复杂度
- 采样点数固定:$K$ 和 $L$ 为固定超参数,无法根据目标尺度自适应调整采样密度
- 解码器自注意力仍为标准注意力:object queries 之间的交互仍使用 $O(N^2)$ 的标准多头注意力,未充分利用可变形注意力的效率优势
技术影响
- DETR 系列实用化的关键一步:将端到端检测器从”学术新范式”推向”实用可训练”,后续 DAB-DETR、DN-DETR、DINO 均以此为基础
- BEV 感知的核心组件:多尺度可变形注意力被 BEVFormer 直接采用为 BEV → 图像特征的空间交叉注意力机制,成为自动驾驶 3D 感知的标准模块
- 开源影响力:代码被 MMDetection、Detectron2 等主流检测框架集成,推动了 Transformer 检测器在工业界的落地
- 学术引用量极高:作为 DETR 到现代 DETR 变体(DINO 等 COCO SOTA)之间的关键桥梁,在目标检测、实例分割、全景分割等方向产生了广泛的后续工作