Task: Image Classification / Feature Backbone
Method: Vision Transformer, Patch Embedding
Venue: ICLR
Year: 2021
Paper: https://arxiv.org/abs/2010.11929
Code: https://github.com/google-research/vision_transformer
摘要
Transformer 架构已成为自然语言处理的事实标准,但在计算机视觉中仍受限于与卷积网络结合或替换卷积的局部组件。本文表明这种对 CNN 的依赖并非必要:将纯 Transformer 直接应用于图像 patch 序列即可在分类任务上取得优异性能。在大规模数据上预训练后迁移到多个中小规模基准(ImageNet, CIFAR-100, VTAB 等),Vision Transformer (ViT) 达到了与 SOTA 卷积网络相当甚至更好的结果,同时所需预训练计算资源大幅减少。最佳模型 ViT-H/14 在 ImageNet 上达到 88.55% top-1 准确率,CIFAR-100 上达到 94.55%。
核心论点:视觉识别不需要卷积——将图像切割为 16×16 的 patch 序列,直接输入标准 NLP Transformer,在足够大的数据集(14M-300M 图像)预训练下即可超越 CNN,证明了”大数据 + 大模型”的 scaling law 在视觉领域同样成立。
问题与动机
2020 年前,计算机视觉中 Transformer 的应用面临根本性矛盾:
| 方案 | 代表作 | 核心问题 |
|---|---|---|
| 局部注意力 | Image Transformer (Parmar 2018) | 仅在局部邻域计算注意力,丧失全局建模能力 |
| 稀疏注意力 | Sparse Transformer (Child 2019) | 需要特殊注意力模式,硬件效率低 |
| CNN + Self-Attention | Non-local Nets / DETR | 仍依赖 CNN 特征提取,Transformer 仅做后处理 |
| 像素级全注意力 | 理论方案 | 针对像素的二次复杂度 $O(n^2)$,224×224 图像就有 50176 个 token,完全不可行 |
当时的认知是:视觉任务需要 CNN 的归纳偏置(locality、translation equivariance、2D 结构),纯 Transformer 在视觉上无法工作。
核心痛点:能否像 NLP 一样,用最简单的标准 Transformer 直接处理视觉数据?CNN 的归纳偏置在大规模预训练下是否真的必要?
核心洞察
洞察 1:图像 = Patch 序列,无需卷积
传统做法:图像 → CNN 提取特征 → 可能用 Transformer 做后处理。
本文做法:将图像 $\mathbf{x} \in \mathbb{R}^{H \times W \times C}$ 切割为 $N$ 个固定大小的 patch $\mathbf{x}_p \in \mathbb{R}^{N \times (P^2 \cdot C)}$,其中 $N = HW/P^2$,每个 patch 通过一个线性投影映射为 token embedding:
$$\mathbf{z}_0 = [\mathbf{x}_{\text{class}};\, \mathbf{x}_p^1 \mathbf{E};\, \mathbf{x}_p^2 \mathbf{E};\, \cdots;\, \mathbf{x}_p^N \mathbf{E}] + \mathbf{E}_{pos}$$其中 $\mathbf{E} \in \mathbb{R}^{(P^2 \cdot C) \times D}$ 是可学习的线性投影,$\mathbf{E}_{pos} \in \mathbb{R}^{(N+1) \times D}$ 是可学习的 1D 位置嵌入。对于 $P=16$, $224 \times 224$ 图像仅产生 $14 \times 14 = 196$ 个 token,计算完全可行。
洞察 2:大数据弥补归纳偏置缺失
传统认知:CNN 的局部性(locality)和平移等变性(translation equivariance)是视觉任务不可或缺的归纳偏置。
本文发现:ViT 几乎不含视觉归纳偏置——仅在 patch 切割时使用了 2D 结构信息。在小数据集(ImageNet-1k)上,ViT 确实不如同等规模的 ResNet。但在大数据集上预训练后,情况逆转:
- ImageNet-1k 预训练:ViT-B/16 仅 77.91%,不如 ResNet
- ImageNet-21k 预训练(14M):ViT-L/16 达到 85.15%
- JFT-300M 预训练(303M):ViT-H/14 达到 88.55%,超越所有 CNN
数据量越大,ViT 的优势越明显。论文在 JFT 子集实验(9M/30M/90M)中证明:CNN 在小数据集上更好但很快饱和,ViT 随数据量增长持续提升。
洞察 3:Transformer 在视觉上的 Scaling 更高效
传统做法:增大 CNN(ResNet-200x3 等)可以提升性能,但计算代价急剧增长。
本文做法:ViT 在 performance/compute trade-off 上显著优于 ResNet。相同精度下,ViT 使用约 2-4× 更少的计算:
| 模型 | 预训练 exaFLOPs | ImageNet top-1 |
|---|---|---|
| ResNet152x2 (14ep) | 1126 | 85.56% |
| ViT-L/16 (14ep) | 1567 | 87.12% |
| ResNet200x3 (14ep) | 3306 | 87.22% |
| ViT-H/14 (14ep) | 4262 | 88.08% |
ViT-L/16 用不到 ResNet200x3 一半的计算就接近其精度。且 ViT 在测试范围内未出现饱和趋势,暗示继续 scaling 还能获益。
三个关键数字:
- **88.55%**:ViT-H/14 在 ImageNet 上的 top-1 准确率(JFT-300M 预训练),刷新 SOTA
- 16×16:标准 patch 大小,将 224×224 图像转化为 196 个 token
- 2-4×:ViT 相比 ResNet 达到相同精度所需的更少计算量
方法设计
4.1 整体架构
核心流程:输入图像 → Patch 切割 + 线性投影 → 加位置嵌入 + class token → Transformer Encoder → class token 输出 → MLP 分类头
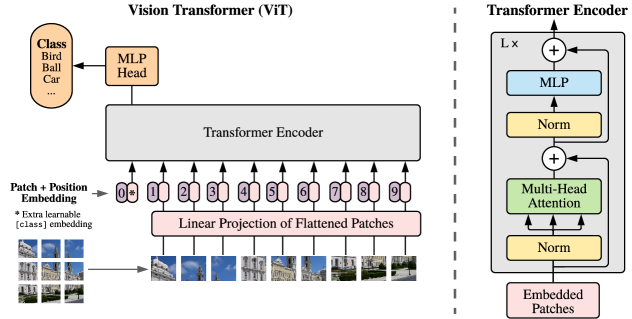
输入 (224×224×3)
│
┌────┴─────────┐
│ Patch 切割 │ P=16 → 14×14 = 196 个 patch
│ + 线性投影 │ (P²·C) × D 映射
└────┬─────────┘
│ (196 × D)
┌────┴─────────┐
│ [CLS] token │ 前置可学习分类 token
│ + Pos Embed │ (N+1) × D 可学习位置嵌入
└────┬─────────┘
│ (197 × D)
┌────┴─────────────────┐
│ Transformer Encoder │ L 层
│ ┌─────────────────┐ │
│ │ LN → MSA → +res │ │ 多头自注意力
│ │ LN → MLP → +res │ │ 2 层 MLP (GELU)
│ └─────────────────┘ │
│ × L 层 │
└────┬─────────────────┘
│
┌────┴────┐
│ LN │ 取 [CLS] token 输出
│ MLP Head│ → 分类概率
└─────────┘
4.2 关键组件
ViT 模型变体:
| 变体 | 层数 L | 隐藏维度 D | MLP 维度 | 注意力头数 | 参数量 |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
Transformer Encoder 各层组件:
| 组件 | 功能 | 公式 |
|---|---|---|
| Layer Norm | 每个子层前归一化 | LN(x) |
| Multi-Head Self-Attention | 全局 token 交互 | $\text{MSA}(\text{LN}(\mathbf{z}{\ell-1})) + \mathbf{z}{\ell-1}$ |
| MLP | 逐 token 非线性变换 | $\text{MLP}(\text{LN}(\mathbf{z}’{\ell})) + \mathbf{z}’{\ell}$ |
| [CLS] token | 聚合全局信息用于分类 | $\mathbf{y} = \text{LN}(\mathbf{z}_L^0)$ |
4.3 关键代码
以下为 Google 官方 JAX/Flax 实现中的核心组件。
Transformer Encoder Block(来源:vit_jax/models_vit.py)
📄 点击展开 Encoder1DBlock 代码
class Encoder1DBlock(nn.Module): |
VisionTransformer 主体(来源:vit_jax/models_vit.py)
📄 点击展开 VisionTransformer 代码
class VisionTransformer(nn.Module): |
实验与分析
5.1 主要结果
与 SOTA 对比(JFT-300M 预训练,多数据集迁移):
| 模型 | ImageNet | ImageNet ReaL | CIFAR-100 | VTAB (19 tasks) | 预训练计算 (TPUv3-core-days) |
|---|---|---|---|---|---|
| BiT-L (ResNet152x4) | 87.54 | 90.54 | 93.51 | 76.3 | 9.9k |
| Noisy Student (EfficientNet-L2) | 88.4 | 90.55 | - | - | 12.3k |
| ViT-L/16 | 87.76 | 90.54 | 93.90 | 76.28 | 0.68k |
| ViT-H/14 | 88.55 | 90.72 | 94.55 | 77.63 | 2.5k |
关键发现:
- ViT-H/14 以 2.5k TPUv3-core-days 的预训练成本超越了 BiT-L 的 9.9k 和 Noisy Student 的 12.3k,计算效率优势显著
- 即使用开源 ImageNet-21k 预训练的 ViT-L/16 也表现出色,仅需 8 个 TPU 核约 30 天即可训练
- ViT 在 VTAB 的 Natural 和 Structured 任务组上优于 BiT,在 Specialized 上持平
5.2 消融实验:验证三个洞察
数据规模实验(验证洞察 2:大数据弥补归纳偏置):
| 预训练数据 | ViT-B/16 | ViT-L/16 | 趋势 | 验证洞察 |
|---|---|---|---|---|
| ImageNet-1k | 77.91 | 76.53 | ViT-L 不如 ViT-B(过拟合) | 洞察 2 |
| ImageNet-21k | 83.97 | 85.15 | ViT-L 开始超越 ViT-B | 洞察 2 |
| JFT-300M | 84.15 | 87.12 | ViT-L 大幅领先 | 洞察 2 |
位置嵌入消融(验证洞察 1:序列化足够):
| 位置编码方式 | ImageNet 5-shot linear |
|---|---|
| 无位置嵌入 | 0.61382 |
| 1D 位置嵌入 | 0.64206 |
| 2D 位置嵌入 | 0.64001 |
| 相对位置嵌入 | 0.64032 |
注:有无位置嵌入差距大,但 1D/2D/相对之间差异极小,说明 patch 级别输入的空间分辨率已经足够低(14×14),不同编码方式同样容易学习。
Scaling 实验(验证洞察 3:计算效率优势):
| 模型 | 预训练 exaFLOPs | ImageNet top-1 | 验证洞察 |
|---|---|---|---|
| ResNet50x1 | 50 | 77.54 | 洞察 3 |
| ViT-B/32 | 55 | 80.73 | 洞察 3 |
| ResNet152x2 | 563 | 84.97 | 洞察 3 |
| ViT-L/16 | 783 | 86.30 | 洞察 3 |
| R50+ViT-B/16 (混合) | 274 | 85.58 | 洞察 3 |
- 洞察 1 验证:仅用简单 1D 位置嵌入即可有效编码空间信息,2D 感知编码无额外收益
- 洞察 2 验证:ViT-L 在 ImageNet-1k 上不如 ViT-B,但在 JFT-300M 上大幅领先——数据越多,ViT 越强
- 洞察 3 验证:相同 exaFLOPs 预算下,ViT 系统性地优于 ResNet;混合模型在小规模时有优势,大规模时差距消失
5.3 性能瓶颈分析
- 在 ImageNet-1k(无额外数据)上训练 ViT-B/16,即使加入 dropout 和 label smoothing,也不如 ResNet-50(归纳偏置在小数据下仍重要)
- 自监督预训练(masked patch prediction)的 ViT-B/16 达到 79.9%,虽然比从头训练好 2%,但仍落后有监督预训练 4%
- 注意力距离分析表明:低层部分 head 已有全局注意力(替代了 CNN 早期的局部接收域),但也有 head 保持局部关注,说明网络自适应地学习了局部和全局模式
5.4 失效场景分析
- 数据不足场景:在 ImageNet-1k(1.3M 图像)上从头训练,ViT 显著不如同计算量的 ResNet,缺乏归纳偏置导致需要更大数据量
- 小 patch 计算爆炸:patch 从 16 减小到 8 时,序列长度增长 4 倍,计算量显著上升
- 自监督预训练差距:masked patch prediction 仍比有监督预训练落后 4%(当时 MAE 等方案尚未提出)
工程实践
6.1 训练配置
Backbone: ViT-B/16, ViT-L/16, ViT-H/14 |
6.2 复现要点
- 预训练数据必须足够大:ViT 在 ImageNet-1k 上从头训练效果差,至少需 ImageNet-21k(14M)预训练才能发挥优势
- Adam 优于 SGD 做预训练:论文发现 Adam 在大规模预训练中优于 SGD,即使对 ResNet 也是如此
- 高分辨率微调:预训练用 224×224,微调时用 384 或更高分辨率,位置嵌入通过 2D 插值适配
- Weight Decay 设为 0.1:远高于 CNN 常用的 0.0001,对 ViT 的迁移性能至关重要
- 微调时替换分类头:移除预训练的 MLP 头,替换为零初始化的单层线性层
- [CLS] 与 GAP 效果相同:论文发现二者区别仅在于最佳学习率不同,性能无实质差异
6.3 性能优化方向
精度提升:
- DeiT(Touvron et al., 2021)引入知识蒸馏和更强数据增强,使 ViT 在 ImageNet-1k 上无需大规模预训练也能达到竞争力
- MAE(He et al., 2022)引入 masked autoencoder 自监督预训练,大幅缩小自监督与有监督预训练的差距
速度优化:
- 使用窗口注意力(Swin Transformer)将 $O(n^2)$ 降为 $O(n)$,适配高分辨率密集预测任务
- FlashAttention 等硬件友好的注意力实现可在不改变模型的前提下加速 2-3 倍
- 轻量级变体(MobileViT 等)面向移动端部署
研究启示
7.1 可迁移的思想
- “图像 = 序列”的统一表示:这一洞察使视觉模型可以直接复用 NLP Transformer 的架构、训练技巧和工程基础设施,催生了多模态统一模型(CLIP, GPT-4V 等)
- Scaling Law 从 NLP 到 Vision 的验证:证明了”大数据 + 大模型”在视觉中同样适用,归纳偏置并非不可替代,而是数据不足时的一种补偿
- Patch Embedding 是一种通用序列化手段:不仅适用于图像,也被扩展到视频(ViViT)、点云(PCT)、音频(AST)等模态
- 预训练-微调范式的视觉扩展:借鉴 BERT 的训练范式,大模型预训练 + 下游任务微调成为视觉领域的标准流程
7.2 方法局限
- 在小数据集上需要大量正则化才能避免过拟合,丧失了 CNN 天然的局部归纳偏置优势
- 标准 ViT 无法高效处理高分辨率图像($O(n^2)$ 注意力),不适合密集预测任务(检测/分割)
- 依赖大规模私有数据集(JFT-300M)预训练,公开可用数据下的复现存在差距
7.3 技术影响
- 开启了 Vision Transformer 时代:直接催生了 DeiT、Swin Transformer、BEiT、MAE 等一系列后续工作,Transformer 迅速取代 CNN 成为视觉主流架构
- 统一了 NLP 和 Vision 的技术栈:使得 CLIP、Flamingo、GPT-4V 等多模态大模型成为可能
- 推动了自动驾驶感知架构变革:BEVFormer、PETR 等 BEV 感知方法的 backbone 从 ResNet 切换为 Swin/ViT,获得显著性能提升
- 改变了学术界对归纳偏置的认知:从”必须精心设计任务特定的归纳偏置”转向”让模型从数据中学习”,推动了 foundation model 范式