Task: Universal Image Segmentation (Panoptic / Instance / Semantic)
Method: Masked Attention + Multi-scale Transformer Decoder
Venue: CVPR 2022
Year: 2022
Paper: https://arxiv.org/abs/2112.01527
Code: https://github.com/facebookresearch/Mask2Former
摘要
图像分割本质上是将像素按不同语义分组,不同的分组标准定义了不同的任务(全景、实例、语义分割)。尽管各任务仅语义不同,现有研究为每个任务设计专用架构。本文提出 Mask2Former,一种能够处理任意图像分割任务的通用架构。其核心创新是掩码注意力(masked attention)——将交叉注意力约束在预测掩码的前景区域内,使特征提取聚焦于局部信息,加速收敛并提升性能。此外,高效多尺度策略引入高分辨率特征改善小目标分割,优化改进(调换自注意力/交叉注意力顺序、可学习 query 特征、去除 dropout)进一步提升性能而不增加计算量。Mask2Former 在四个数据集上以相同架构首次全面超越所有专用架构:COCO 全景分割 57.8 PQ、实例分割 50.1 AP、ADE20K 语义分割 57.7 mIoU。
核心论点:将交叉注意力限制在掩码预测的前景区域(masked attention)是让通用分割架构首次超越所有专用架构的关键——它将 DETR 的全局注意力转化为局部聚焦,解决了收敛慢和特征分散的根本问题。
问题与动机
图像分割领域长期存在架构碎片化问题:
| 任务 | 主流架构范式 | 代表作 | 核心问题 |
|---|---|---|---|
| 语义分割 | 逐像素分类(FCN) | DeepLab, SegFormer | 无法区分实例 |
| 实例分割 | 掩码分类(检测+分割) | Mask R-CNN, HTC++ | 依赖检测框,无法做语义 |
| 全景分割 | 混合两种范式 | Panoptic-DeepLab | 设计复杂,各模块需独立优化 |
MaskFormer(2021)首次证明掩码分类范式可以统一所有分割任务,但性能落后于最佳专用架构(实例分割 AP 低 >9),且训练需 300 epochs。
核心痛点:通用分割架构虽然灵活,但交叉注意力的全局特性导致训练收敛慢、前景注意力分散(仅 20% 权重在前景),在实例分割上无法与专用架构竞争。
核心洞察
洞察 1:掩码注意力——将全局交叉注意力约束为局部关注
传统做法:标准 Transformer 交叉注意力对整张特征图做全局 softmax,导致注意力分散到大面积背景(实验证实仅 20% 权重在前景)。
本文做法:Masked attention 将注意力限制在预测掩码的前景区域内——在 softmax 前对背景位置设为 $-\infty$:
$$\mathcal{M}_{l-1}(x,y) = \begin{cases} 0 & \text{if } \mathbf{M}_{l-1}(x,y) = 1 \\ -\infty & \text{otherwise} \end{cases}$$其中 $\mathbf{M}_{l-1}$ 是上一层预测掩码二值化(阈值 0.5)后的结果。这使前景注意力从 20% 提升到 60%,单层 masked attention 即超越 9 层标准交叉注意力。
洞察 2:高效多尺度——轮询式特征金字塔输入
传统做法:使用单一分辨率特征图(如 1/32)或将多尺度特征拼接后输入每层解码器(计算量大)。
本文做法:从像素解码器的特征金字塔(1/32、1/16、1/8)中,按轮询方式逐层输入不同分辨率——第 1/4/7 层用 1/32,第 2/5/8 层用 1/16,第 3/6/9 层用 1/8。用 $L=3$ 组重复,共 9 层解码器。
这种策略在不增加计算量的前提下(226G vs 朴素多尺度 247G FLOPs)引入高分辨率特征,显著改善小目标分割。
洞察 3:三项优化改进——免费提升性能
传统做法(DETR/MaskFormer):自注意力→交叉注意力→FFN 顺序;query 特征零初始化;使用 dropout。
本文做法:
- 交叉注意力(masked attention)在前:让 query 先接触图像信息再做自注意力交互
- 可学习 query 特征 + 直接监督:query 在进入解码器前就生成掩码提案,相当于 region proposal
- 去除 dropout:在掩码注意力下 dropout 反而有害
三项改进合计提升 +1.4 AP / +1.1 PQ / +0.9 mIoU,且不增加任何 FLOPs。
三个关键数字:
- 57.8 PQ:COCO 全景分割 SOTA(Swin-L),超越 MaskFormer 5.1 PQ
- 50.1 AP:COCO 实例分割 SOTA(Swin-L),首次超越 HTC++
- 3×:采样点损失将训练显存从 18GB 降至 6GB/image
方法设计
4.1 整体架构
$$\text{Image} \rightarrow \text{Backbone} \rightarrow \text{Pixel Decoder (MSDeformAttn)} \rightarrow \text{Transformer Decoder (Masked Attn)} \rightarrow N \times (\text{class}, \text{mask})$$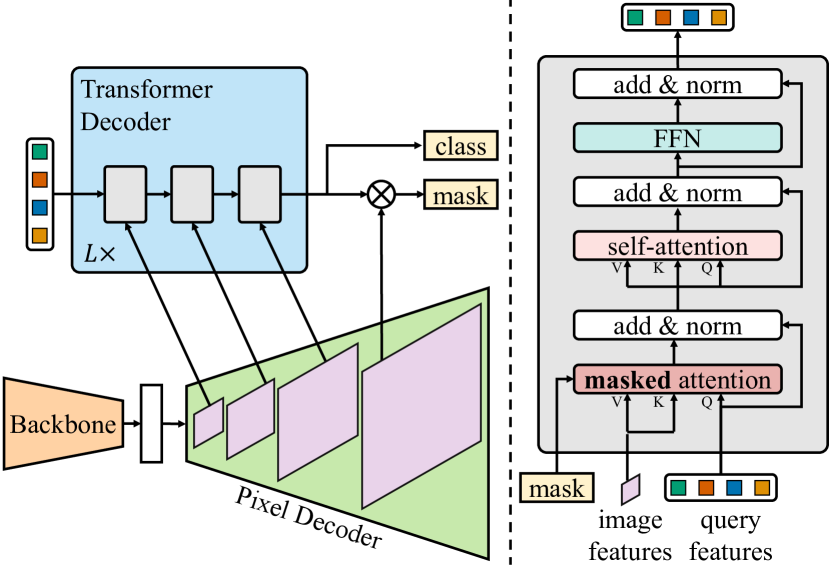
Image (H × W × 3)
│
▼
┌──────────────────────────┐
│ Backbone (R50/Swin-L) │
│ → 多尺度特征 C2-C5 │
└──────────┬───────────────┘
▼
┌──────────────────────────┐
│ Pixel Decoder │
│ 6 × MSDeformAttn │
│ → FPN: 1/32, 1/16, 1/8 │
│ → Upsample: 1/4 (mask) │
└──────────┬───────────────┘
▼
┌──────────────────────────────────┐
│ Transformer Decoder (9 layers) │
│ 每层: │
│ 1. Masked Cross-Attn │
│ (仅关注前景 mask 区域) │
│ 2. Self-Attn (query 交互) │
│ 3. FFN │
│ 特点: 轮询 1/32→1/16→1/8 × 3 组 │
│ 100 learnable queries │
└──────────┬───────────────────────┘
▼
N × (class_logits, binary_mask)
匈牙利匹配 + BCE Mask + Dice Loss
4.2 关键组件
| 组件 | 规格 | 功能 | 损失权重 |
|---|---|---|---|
| Pixel Decoder | 6 × MSDeformAttn, FPN 1/8-1/32 | 多尺度特征生成 | — |
| Transformer Decoder | 9 层, 100 queries | 掩码注意力解码 | — |
| 分类头 | Linear(256→K+1) | 类别预测 | $\lambda_{cls}=2.0$ |
| 掩码头 | MLP(256→256→256→mask_dim) | 掩码嵌入 | — |
| 掩码损失 | BCE + Dice | 二值掩码预测 | $\lambda_{ce}=5.0, \lambda_{dice}=5.0$ |
4.3 关键代码
Transformer 解码器的核心 forward 逻辑,展示了掩码注意力和轮询多尺度策略。
(来源:mask2former_transformer_decoder.py)
📄 点击展开 MultiScaleMaskedTransformerDecoder.forward 代码
def forward(self, x, mask_features, mask=None): |
掩码注意力的关键在 forward_prediction_heads 中生成 attn_mask:
(来源:mask2former_transformer_decoder.py)
def forward_prediction_heads(self, output, mask_features, attn_mask_target_size): |
实验与分析
5.1 主要结果
| 方法 | Backbone | 全景 PQ | 实例 AP | 语义 mIoU | 类型 |
|---|---|---|---|---|---|
| MaskFormer | R50 | 46.5 | 34.0 | 44.5 | 通用 |
| Mask R-CNN (LSJ) | R50 | — | 42.5 | — | 专用 |
| Mask2Former | R50 | 51.9 | 43.7 | 47.2 | 通用 |
| HTC++ | Swin-L | — | 49.5 | — | 专用 |
| Mask2Former | Swin-L | 57.8 | 50.1 | 57.7 | 通用 |
关键发现:
- Mask2Former 以 50 epochs 即可达到 MaskFormer 300 epochs 的性能(收敛快 6×)
- 首次让通用架构在所有三个任务上超越最佳专用架构
- 使用采样点损失,训练显存从 18GB 降至 6GB/image(3× 节省)
5.2 消融实验:验证三个洞察
| 配置 | AP (COCO) | PQ (COCO) | mIoU (ADE20K) | 验证洞察 |
|---|---|---|---|---|
| Mask2Former(完整) | 43.7 | 51.9 | 47.2 | — |
| − masked attention | 37.8 (−5.9) | 47.1 (−4.8) | 45.5 (−1.7) | 洞察 1 |
| − high-res features | 41.5 (−2.2) | 50.2 (−1.7) | 46.1 (−1.1) | 洞察 2 |
| − learnable queries | 42.9 (−0.8) | 51.2 (−0.7) | 45.4 (−1.8) | 洞察 3 |
| − cross-attn first | 43.2 (−0.5) | 51.6 (−0.3) | 46.3 (−0.9) | 洞察 3 |
| − remove dropout | 43.0 (−0.7) | 51.3 (−0.6) | 47.2 (−0.0) | 洞察 3 |
5.3 性能瓶颈分析
- 小目标检测:APS 仍然落后于部分专用方法,高分辨率特征使用可进一步改善
- 多任务联合训练:在全景标注上训练的模型比专门在实例/语义标注上训练的性能略低
5.4 失效场景分析
- 小物体密集场景:极小目标的掩码预测精度仍不足
- 多任务训练退化:仅用全景标注训练时,实例 AP 比专用训练低约 2 AP
- 高分辨率输入:多尺度推理对端到端模型非平凡,需要额外后处理(如 NMS)
工程实践
6.1 训练配置
Backbone: R50 / Swin-L (ImageNet-22K pretrained) |
6.2 复现要点
- 像素解码器选择:MSDeformAttn 在所有三个任务上一致最优;BiFPN 偏好实例分割,FaPN 偏好语义分割
- 采样点损失:在匹配损失和训练损失中均使用 12544 个采样点替代全掩码,节省 3× 显存且无性能损失
- 可学习 query 必须监督:不监督的可学习 query 效果等同于零初始化
- Backbone 学习率:对 backbone 施加 0.1× 的学习率乘数
- Query 数量:全景分割推荐 200 queries(segments 多),实例/语义推荐 100
6.3 性能优化方向
精度提升:
- 使用 dilated backbone 改善小目标检测(DETR 已验证有效)
- 探索多任务联合训练策略,减少任务间性能退化
速度优化:
- 减少解码器层数(从 9 层到 6 层),牺牲少量精度换取更快推理
- 使用更轻量的 pixel decoder 替代 MSDeformAttn
研究启示
7.1 可迁移的思想
- 掩码注意力 = 注意力聚焦:任何需要将全局注意力收缩到局部区域的任务(如 3D 占用预测、视频分割)都可以借鉴掩码注意力的思路
- 轮询多尺度 > 拼接多尺度:在 Transformer 解码器中逐层轮询不同分辨率特征,比暴力拼接更高效
- OccFormer 的 3D 适配:OccFormer 将 Mask2Former 的掩码分类范式推广到 3D 体素空间,提出 preserve-pooling 和 class-guided sampling 解决 3D 稀疏性问题
- 可学习 query 即 region proposal:无需显式 RPN,端到端可学习的 query 特征自动学会生成掩码提案
7.2 方法局限
- 仍需按任务分别训练,未实现真正的单模型多任务
- 多尺度推理对实例分割非平凡,端到端方案缺乏成熟的多尺度策略
- 小目标性能仍有提升空间
7.3 技术影响
- 统一分割架构的里程碑:首次证明通用架构可全面超越专用架构
- OccFormer 的直接上游:OccFormer 的 3D Mask Classification 解码器直接继承自 Mask2Former 的掩码分类范式
- OneFormer/SAM 的基础:Mask2Former 的概念影响了后续的 OneFormer(一模型多任务联合训练)和 SAM(基础分割模型)等工作
- 工业界广泛采用:Mask2Former 成为 Detectron2 生态中分割任务的默认基线