Task: Image Classification / Object Detection / Semantic Segmentation
Method: Shifted Window Self-Attention / Hierarchical Feature Maps
Venue: ICCV 2021 (V1) / CVPR 2022 (V2)
Year: 2021 / 2022
Paper: https://arxiv.org/abs/2103.14030 / https://arxiv.org/abs/2111.09883
Code: https://github.com/microsoft/Swin-Transformer
摘要
Swin Transformer 提出了一种基于移位窗口的层级视觉 Transformer 架构,首次让 Transformer 在图像分类、目标检测和语义分割三个任务上全面超越 CNN 和先前的 ViT 方案。核心设计包括:(1) 将自注意力限制在不重叠的局部窗口内,使计算复杂度从全局二次降到图像尺寸的线性;(2) 通过窗口移位在相邻层之间建立跨窗口连接;(3) 通过 patch merging 构建 4 阶段层级特征图,天然兼容 FPN、UperNet 等密集预测框架。
Swin Transformer V2 在此基础上解决了大规模训练的三个关键问题:(1) residual-post-norm + scaled cosine attention 稳定深层激活值,使模型可扩展到 30 亿参数;(2) log-spaced continuous position bias (Log-CPB) 实现窗口分辨率的平滑迁移;(3) 结合 SimMIM 自监督预训练,用 1/40 的标注数据和 1/40 的训练时间达到 SOTA。
核心论点:将局部性(窗口注意力)和层级结构(patch merging)这两个 CNN 归纳偏置引入 Transformer,在保留强建模能力的同时获得线性复杂度和多尺度特征,使 Transformer 真正成为视觉通用骨干网络。
问题与动机
ViT 将 Transformer 引入视觉领域取得了令人瞩目的分类结果,但在密集预测任务上存在根本性限制:
| 方案类型 | 代表作 | 核心问题 |
|---|---|---|
| 全局 ViT | ViT, DeiT | 单一分辨率特征图,复杂度 $O(n^2)$,无法直接用于检测/分割 |
| 局部注意力 CNN | Local Relation Net | 滑动窗口导致每个 query 对应不同 key set,硬件内存访问效率低 |
| CNN 骨干 | ResNet, EfficientNet | 准确度接近饱和,缺少长距离建模能力 |
核心痛点:ViT 的全局自注意力在高分辨率图像上计算量无法承受($O(n^2)$),且其单尺度特征图无法直接服务目标检测和语义分割等需要多尺度特征的密集预测任务。
核心洞察
洞察 1:窗口注意力 + 移位策略 = 线性复杂度 + 跨窗口连接
传统做法:ViT 对所有 token 计算全局自注意力,复杂度为 $\Omega(\text{MSA}) = 4hwC^2 + 2(hw)^2C$,在高分辨率图像上不可行。
本文做法:将自注意力限制在 $M \times M$(默认 $M=7$)的不重叠局部窗口内:
$$\Omega(\text{W-MSA}) = 4hwC^2 + 2M^2 hwC$$复杂度从 $(hw)^2$ 降为 $M^2 \cdot hw$,当 $M$ 固定时关于图像尺寸线性。为解决窗口间信息隔离问题,相邻两层交替使用常规窗口(W-MSA)和移位窗口(SW-MSA),移位偏移量为 $(\lfloor M/2 \rfloor, \lfloor M/2 \rfloor)$:
$$\hat{\mathbf{z}}^l = \text{W-MSA}(\text{LN}(\mathbf{z}^{l-1})) + \mathbf{z}^{l-1}, \quad \mathbf{z}^l = \text{MLP}(\text{LN}(\hat{\mathbf{z}}^l)) + \hat{\mathbf{z}}^l$$ $$\hat{\mathbf{z}}^{l+1} = \text{SW-MSA}(\text{LN}(\mathbf{z}^l)) + \mathbf{z}^l, \quad \mathbf{z}^{l+1} = \text{MLP}(\text{LN}(\hat{\mathbf{z}}^{l+1})) + \hat{\mathbf{z}}^{l+1}$$通过循环移位 + mask(cyclic shift)实现高效 batch 计算,比 naive padding 快 13%−18%,比滑动窗口快 4× 以上。
洞察 2:Patch Merging 构建层级特征 — Transformer 的 “FPN 兼容性”
传统做法:ViT 全程保持 $\frac{H}{16} \times \frac{W}{16}$ 的单一分辨率特征图,无法直接接 FPN 或 UperNet。
本文做法:设计 4 阶段层级架构,每个阶段通过 patch merging 降采样 2×:将 $2 \times 2$ 邻近 patch 的特征拼接($4C$ 维),再经线性层投影到 $2C$ 维。四个阶段分辨率分别为 $\frac{H}{4}, \frac{H}{8}, \frac{H}{16}, \frac{H}{32}$,与 ResNet 的 C2-C5 完全对齐。
| 变体 | $C$ | 层数 {S1,S2,S3,S4} | 参数量 | FLOPs | ImageNet top-1 |
|---|---|---|---|---|---|
| Swin-T | 96 | {2,2,6,2} | 29M | 4.5G | 81.3% |
| Swin-S | 96 | {2,2,18,2} | 50M | 8.7G | 83.0% |
| Swin-B | 128 | {2,2,18,2} | 88M | 15.4G | 83.5% |
| Swin-L | 192 | {2,2,18,2} | 197M | 103.9G | 87.3%(22K) |
这一层级设计使 Swin Transformer 可以无缝替换 ResNet 骨干,接入 Cascade Mask R-CNN、HTC++、UperNet 等框架。
洞察 3:V2 — Post-Norm + Cosine Attention + Log-CPB 解决大规模训练的三大障碍
障碍 1 — 训练不稳定:原始 pre-norm 配置中残差输出直接回加主干,激活值逐层累积,在 Large 模型上最高/最低层振幅差达 $10^4$,Huge 模型直接崩溃。
解决 — Residual-post-norm + Scaled cosine attention:将 LayerNorm 移至残差分支末尾(post-norm),激活值不再累积;将 dot-product attention 替换为基于余弦相似度的 scaled cosine attention:
$$\text{Sim}(\mathbf{q}_i, \mathbf{k}_j) = \frac{\cos(\mathbf{q}_i, \mathbf{k}_j)}{\tau} + B_{ij}$$其中 $\tau$ 为可学习标量($\tau > 0.01$),每头每层独立。余弦函数天然归一化,不受输入振幅影响。
障碍 2 — 跨分辨率迁移困难:原始参数化位置偏置在窗口尺寸变化时用双三次插值,效果差。
**解决 — Log-spaced Continuous Position Bias (Log-CPB)**:用小型 MLP $\mathcal{G}$(2 层 + ReLU)从相对坐标生成偏置值 $B(\Delta x, \Delta y) = \mathcal{G}(\widehat{\Delta x}, \widehat{\Delta y})$,并对坐标取对数:
$$\widehat{\Delta x} = \text{sign}(\Delta x) \cdot \log(1 + |\Delta x|)$$窗口从 $8 \times 8$ 迁移到 $16 \times 16$ 时,外推比从原始 1.14× 降至 0.33×(约 4× 更小的外推范围),显著改善迁移准确率。
障碍 3 — 标注数据需求大:V2 结合 SimMIM 自监督预训练,仅用 7000 万张图像(JFT-3B 的 1/40)。
三个关键数字:
- 58.7 / 51.1 AP:Swin-L 在 COCO test-dev 上的 box / mask AP,分别超越前 SOTA +2.7 / +2.6
- 87.3% top-1:Swin-L(ImageNet-22K 预训练)在 ImageNet-1K 上的分类准确率
- 63.1 / 54.4 AP:SwinV2-G(3B 参数)在 COCO test-dev 上的 box / mask AP,超越前 SOTA +1.8 / +1.4
方法设计
4.1 整体架构
核心流程:
$$\text{Image} \xrightarrow{\text{Patch Partition}} \text{Tokens}_{H/4 \times W/4} \xrightarrow{\text{Stage 1-4}} \text{Multi-scale Features} \xrightarrow{\text{Task Head}} \text{Output}$$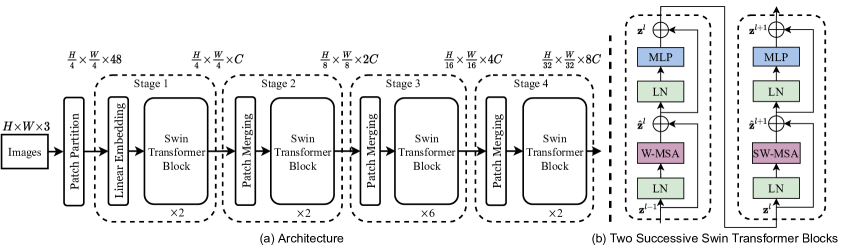
Input Image (H×W×3)
│
▼
┌─────────────────┐
│ Patch Partition│ 4×4 patch → 拼接 RGB → 48 维
│ Linear Embed │ 48 → C 维
└─────────────────┘
│ H/4 × W/4 × C
▼
┌─────────────────┐
│ Stage 1 │ ×L1 Swin Blocks (W-MSA / SW-MSA 交替)
└─────────────────┘
│ H/4 × W/4 × C
▼
┌─────────────────┐
│ Patch Merging │ 2×2 拼接 → 4C → Linear → 2C
└─────────────────┘
│ H/8 × W/8 × 2C
▼
┌─────────────────┐
│ Stage 2 │ ×L2 Swin Blocks
└─────────────────┘
│ H/8 × W/8 × 2C
▼
┌─────────────────┐
│ Patch Merging │ → 4C → 2C (same)
└─────────────────┘
│ H/16 × W/16 × 4C
▼
┌─────────────────┐
│ Stage 3 │ ×L3 Swin Blocks (主计算量)
└─────────────────┘
│ H/16 × W/16 × 4C
▼
┌─────────────────┐
│ Patch Merging │
└─────────────────┘
│ H/32 × W/32 × 8C
▼
┌─────────────────┐
│ Stage 4 │ ×L4 Swin Blocks
└─────────────────┘
│
├──→ Global AvgPool → Linear → [分类]
└──→ FPN / UperNet → [检测/分割]
4.2 关键组件
窗口注意力与相对位置偏置:
$$\text{Attention}(Q, K, V) = \text{SoftMax}\left(\frac{QK^T}{\sqrt{d}} + B\right) V$$其中 $B \in \mathbb{R}^{M^2 \times M^2}$ 从可学习偏置矩阵 $\hat{B} \in \mathbb{R}^{(2M-1) \times (2M-1)}$ 中索引获取。
V2 Scaled Cosine Attention:
$$\text{Sim}(\mathbf{q}_i, \mathbf{k}_j) = \frac{\cos(\mathbf{q}_i, \mathbf{k}_j)}{\tau} + B_{ij}$$V2 Log-CPB:
$$B(\Delta x, \Delta y) = \mathcal{G}\left(\text{sign}(\Delta x) \cdot \log(1+|\Delta x|),\; \text{sign}(\Delta y) \cdot \log(1+|\Delta y|)\right)$$其中 $\mathcal{G}$ 为 2 层 MLP(512 隐藏维度 + ReLU)。
| V1 → V2 关键改动 | V1 配置 | V2 配置 | 解决问题 |
|---|---|---|---|
| 归一化位置 | Pre-norm(LN 在残差前) | Res-post-norm(LN 在残差后) | 激活值逐层累积导致训练不稳定 |
| 注意力计算 | Dot-product / √d | Cosine / τ(可学习) | 注意力值被少数 token 主导 |
| 位置偏置 | 参数化 $\hat{B}$ + 双三次插值 | MLP 生成 + 对数坐标 | 跨窗口分辨率迁移效果差 |
4.3 关键代码
代码来源:microsoft/Swin-Transformer (MIT License)
| 函数/类 | 功能 |
|---|---|
window_partition |
将特征图切分为不重叠窗口 |
window_reverse |
将窗口合并恢复为特征图 |
WindowAttention |
窗口内多头自注意力(含相对位置偏置) |
SwinTransformerBlock.forward |
完整的移位窗口注意力前向传播 |
📄 点击展开 WindowAttention.forward 代码
(来源:models/swin_transformer.py)
def forward(self, x, mask=None): |
📄 点击展开 SwinTransformerBlock.forward 代码
(来源:models/swin_transformer.py)
def forward(self, x): |
📄 点击展开 window_partition / window_reverse 代码
(来源:models/swin_transformer.py)
def window_partition(x, window_size): |
实验与分析
5.1 主要结果
ImageNet-1K 图像分类(Regular Training, 224²):
| 方法 | 参数量 | FLOPs | top-1 acc |
|---|---|---|---|
| DeiT-S | 22M | 4.6G | 79.8% |
| RegNetY-8G | 39M | 8.0G | 81.7% |
| Swin-T | 29M | 4.5G | 81.3% |
| DeiT-B | 86M | 17.5G | 81.8% |
| Swin-S | 50M | 8.7G | 83.0% |
| Swin-B (384²) | 88M | 47.0G | 84.5% |
| Swin-L (384², 22K) | 197M | 103.9G | 87.3% |
COCO 目标检测(test-dev, HTC++ framework):
| 方法 | Backbone | box AP | mask AP |
|---|---|---|---|
| Copy-paste | — | 56.0 | 48.5 |
| DetectoRS | — | — | 48.5 |
| Swin-L (22K) | HTC++ | 58.7 | 51.1 |
| SwinV2-G (3B) | HTC++ | 63.1 | 54.4 |
ADE20K 语义分割(val, UperNet):
| 方法 | Backbone | mIoU |
|---|---|---|
| SETR | ViT-L | 50.3 |
| Swin-L (22K) | UperNet | 53.5 |
| BEiT | — | 58.4 |
| SwinV2-G (3B) | UperNet | 59.9 |
关键发现:
- Swin-T 在所有四个检测框架(Cascade Mask R-CNN, ATSS, RepPoints v2, Sparse RCNN)上一致性超越 ResNet-50 +3.4∼4.2 box AP
- 相比 DeiT-S,Swin-T 同等参数规模下推理速度快 47%(15.3 FPS vs 10.4 FPS),box AP 高 +2.5
- SwinV2-G 仅用 1/40 标注数据和 1/40 训练时间即达到 COCO 63.1 AP,超越 Google 十亿参数级模型
5.2 消融实验:验证三个洞察
V1 消融(基于 Swin-T):
| 配置 | ImageNet top-1 | COCO box AP | ADE20K mIoU | 验证洞察 |
|---|---|---|---|---|
| 无移位窗口 | 80.2% | 47.7 | 43.3 | — |
| 移位窗口 | 81.3% (+1.1) | 50.5 (+2.8) | 46.1 (+2.8) | 洞察 1 |
| 无位置编码 | 80.1% | 49.2 | 43.8 | — |
| 绝对位置 | 80.5% | 49.0 | 43.2 | — |
| 相对位置偏置 | 81.3% (+1.2) | 50.5 (+1.3) | 46.1 (+2.3) | 洞察 2 (位置编码) |
注:绝对位置编码在分类上有 +0.4% 提升,但在检测和分割上均出现精度下降,说明翻译不变性归纳偏置对密集预测更重要。
V2 消融 — res-post-norm + cosine attention:
| Backbone | 无改进 | +post-norm | +post-norm+cosine | 验证洞察 |
|---|---|---|---|---|
| Swin-T | 81.5% | 81.6% | 81.7% (+0.2) | 洞察 3 |
| Swin-S | 83.2% | 83.3% | 83.6% (+0.4) | 洞察 3 |
| Swin-B | 83.6% | 83.8% | 84.1% (+0.5) | 洞察 3 |
改进幅度随规模增大而增长(+0.2 → +0.4 → +0.5),说明这些技术对大模型更重要。
V2 消融 — 跨分辨率迁移(预训练 W8/I256,直接测试不同窗口大小, Swin-T):
| 方法 | W8 (预训练) | W12 (w/o ft) | W16 (w/o ft) | W24 (w/o ft) | 验证洞察 |
|---|---|---|---|---|---|
| 参数化偏置 | 81.7% | 79.4% | 77.2% | 68.7% | — |
| Log-CPB | 81.8% | 82.4% | 81.7% | 79.1% | 洞察 3 |
Log-CPB 在 W8→W24 的极端外推下仍保持 79.1%,而参数化偏置暴跌至 68.7%(差距 10.4%)。
5.3 性能瓶颈分析
- 推理延迟:Swin Transformer 使用 PyTorch 内置算子实现,未经深度内核优化,与高度优化的 CuDNN ResNet 相比延迟略高
- 窗口大小限制:固定 $7 \times 7$ 窗口大小限制了单次注意力的感受野,需要多层累积才能覆盖全图
- 大模型内存:V2 的 3B 参数模型需要 ZeRO optimizer + activation checkpointing + 顺序自注意力计算三项技术才能在 A100-40G 上训练
5.4 失效场景分析
- 小窗口 vs 大目标:当目标跨越多个窗口时,需要足够多的层才能通过移位传播信息,对超大目标的全局关系建模能力不如全局注意力
- 跨窗口分辨率极端外推(V1):V1 使用双三次插值,窗口从 8→24 时 top-1 从 81.7% 降至 68.7%,V2 的 Log-CPB 显著缓解但仍有 2.7% 降幅
- Huge 模型训练崩溃(V1 配置):原始 pre-norm 在 658M 参数的 Huge 模型上无法完成训练,激活值爆炸导致发散
工程实践
6.1 训练配置
**V1 ImageNet-1K (224²)**:
Backbone: Swin-T/S/B |
**V1 COCO Detection (Cascade Mask R-CNN, 3× schedule)**:
Framework: mmdetection |
6.2 复现要点
- 不使用 Repeated Augmentation 和 EMA:与 DeiT 不同,这两项在 Swin 上不提升性能
- Stochastic depth 随模型增大:T/S/B 分别使用 0.2/0.3/0.5 的 drop rate
- 检测用 AdamW 而非 SGD:ResNet 骨干换用 AdamW 后也能提升 0.5−1.3 AP,确保公平对比
- 窗口大小可整除性:输入分辨率必须被窗口大小整除,否则需 padding
- V2 大模型额外 LN:SwinV2-H/G 在主干每 6 个 Transformer block 后加一层额外 LayerNorm
6.3 性能优化方向
精度提升:
- 使用 ImageNet-22K 预训练可为 Swin-B 带来 +1.8∼1.9% top-1 提升,推荐在下游密集任务中使用 22K 预训练权重
- V2 的 Log-CPB 支持在测试时使用更大窗口,无需额外微调即可获得精度提升
速度优化:
- 循环移位(cyclic shift)比 naive padding 快 13%−18%,是默认实现
- Fused window process 内核可在单个 CUDA kernel 中完成移位+分窗+逆操作,进一步减少kernel launch 开销
- V2 的 sequential self-attention 计算在前两个阶段对速度影响较小,但能大幅降低大分辨率下的内存消耗
研究启示
7.1 可迁移的思想
- 局部注意力 + 跨窗口连接是通用模式:可应用于视频理解(Video Swin)、点云处理、3D 医学图像等高分辨率场景,在保持线性复杂度的同时获得全局建模能力
- 层级特征对齐 CNN 设计范式:使 Transformer 骨干可以无缝接入已有的检测/分割框架(FPN, UperNet),降低迁移成本
- Post-norm + cosine attention 稳定训练:不仅适用于视觉 Transformer,也适用于 MLP-Mixer 等非注意力架构(Swin-Mixer 验证了这一点),可推广至任意需要深层残差训练的场景
- 对数坐标外推:Log-CPB 的对数坐标思想可迁移到任何需要跨分辨率/跨尺度迁移位置编码的场景
7.2 方法局限
- 固定窗口大小的局部注意力在需要全局上下文的任务上不如全局注意力(如 ImageNet 分类只有 +1.5% over DeiT)
- V2 的 3B 模型训练仍需大规模 GPU 集群(A100-40G),ZeRO + checkpointing 带来额外工程复杂度
- V1 相对位置偏置的参数化方案无法处理可变窗口大小,V2 用 Log-CPB 解决但引入了额外的 MLP 参数
7.3 技术影响
- 确立了 Transformer 作为视觉通用骨干 的地位:Swin 是第一个在分类、检测、分割三任务上同时达到 SOTA 的 Transformer
- 推动了 BEVDet、BEVFormer、Mask2Former 等后续工作采用 Swin 作为默认骨干
- 层级设计 + 局部注意力的范式被 Focal Transformer、CSWin、Twins 等后续工作广泛采用
- V2 的大模型训练技术(post-norm, cosine attention, Log-CPB)成为后续大规模视觉模型的标准实践