Task: Object Detection
Method: DETR with Improved DeNoising Anchor Boxes
Venue: CVPR 2022 (DN-DETR) / ICLR 2022 (DAB-DETR) / ICLR 2023 (DINO)
Year: 2022–2023
Paper: https://arxiv.org/abs/2203.01305 (DN-DETR) | https://arxiv.org/abs/2201.12329 (DAB-DETR) | https://arxiv.org/abs/2203.03605 (DINO)
Code: https://github.com/IDEACVR/DINO
摘要
DETR(2020)开创了端到端目标检测范式,消除了 anchor 设计和 NMS,但受限于收敛速度慢和 query 语义不明确。IDEA Research 通过三项递进式改进彻底解决了这两个问题:
DAB-DETR(ICLR 2022)将 DETR 的 query 显式建模为 4D 动态锚框 $(x, y, w, h)$,建立了 DETR query 与传统 anchor 的桥梁,使 query 具有明确的空间含义并支持逐层精炼。
DN-DETR(CVPR 2022)发现 DETR 收敛慢的根源在于匈牙利匹配的不稳定性——相同目标在不同训练步可能被分配给不同 query。通过在 decoder 输入端注入带噪声的 GT 标签和框,增加去噪训练分支,DN-DETR 稳定了匹配过程,将 DETR 训练加速至 12 epochs 即可收敛。
DINO(ICLR 2023)在 DAB-DETR 和 DN-DETR 基础上引入三项改进:对比去噪训练(CDN,同时添加正负样本抑制重复预测)、混合查询选择(仅从编码器选择位置查询,内容查询保持可学习)、Look Forward Twice(利用后层梯度优化前层参数)。DINO 使用 ResNet-50 在 12 epochs 内达到 49.4 AP(比 DN-DETR +6.0),使用 SwinL + Objects365 预训练达到 63.3 AP(COCO test-dev SOTA),首次让端到端 Transformer 检测器超越所有传统检测器。
核心论点:DETR 的两大瓶颈——query 语义模糊和匹配不稳定——分别被 DAB(动态锚框)和 DN(去噪训练)系统性地解决;在此基础上的对比去噪、混合查询和前向传递优化(DINO)使 DETR 家族首次在性能和效率上全面超越传统检测器。
问题与动机
DETR(2020)的核心创新在于用集合预测替代 anchor+NMS 的传统流程,但两大问题阻碍了其实际应用:
| 问题 | 具体表现 | 影响 |
|---|---|---|
| Query 语义模糊 | 可学习 query 无明确空间含义 | decoder 需更多层学习位置编码 |
| 匹配不稳定 | 同一 GT 在不同步匹配到不同 query | 训练振荡,需 500 epochs 收敛 |
| 收敛速度慢 | DETR 需 500 epochs | Faster R-CNN 仅需 12-36 epochs |
| 小目标性能差 | 单尺度特征 + 全局注意力 | APs 远低于传统检测器 |
IDEA Research 的三篇工作按递进关系逐步解决这些问题:
- DAB-DETR:给 query 赋予明确的空间含义(4D 锚框)
- DN-DETR:通过去噪训练稳定匹配过程
- DINO:综合优化去噪、查询初始化和梯度传播
核心痛点:如何让 DETR-like 端到端检测器在训练效率和检测精度上全面超越经过多年优化的传统检测器?
核心洞察
洞察 1:Query = 动态锚框——让 DETR 的 query 有空间含义
传统做法(DETR):decoder 的 query 是可学习的嵌入向量,无明确的空间含义。模型需要从零学习每个 query 应关注图像的哪个位置,这是收敛慢的重要原因。
DAB-DETR 做法:将每个 query 显式建模为 4D 锚框 $(x, y, w, h)$,其中位置 $(x, y)$ 用于参考点,宽高 $(w, h)$ 用于调制注意力范围。每层 decoder 输出偏移量,逐层精炼锚框。
为什么更好:
- 建立了 DETR query 与传统 anchor 的明确对应,降低了学习难度
- 宽高信息使注意力范围自适应目标尺度——大物体关注更大范围
- 逐层精炼等价于 cascade 策略,使框越来越精确
洞察 2:去噪训练——用 GT 噪声注入稳定匈牙利匹配
传统做法(DETR):每个训练步通过匈牙利匹配将预测与 GT 配对。由于早期 query 未学好,匹配结果在步间波动,导致同一 GT 被不同 query 匹配,梯度信号矛盾。
DN-DETR 做法:在正常 query 之外,额外添加一组去噪 query——将 GT 框和标签加上可控噪声后送入 decoder,训练模型重建原始 GT。去噪分支的 GT 分配是确定的(不经过匹配),提供稳定的训练信号。
DINO 的改进——对比去噪(CDN):同时添加正样本(小噪声,需重建 GT)和负样本(大噪声,需预测”无物体”),教模型区分好锚框和坏锚框。在小目标上带来 +1.3 AP 的提升。
$$\text{CDN}: \text{noise} < \lambda_1 \to \text{正样本(重建GT)}$$ $$\lambda_1 \leq \text{noise} < \lambda_2 \to \text{负样本(预测背景)}$$洞察 3:混合查询 + Look Forward Twice——最后的精度提升
查询初始化对比:
| 方式 | 位置 query | 内容 query | 代表方法 |
|---|---|---|---|
| 静态 | 可学习 | 全零 | DETR, DN-DETR |
| 纯选择 | 编码器 top-K | 编码器 top-K | Deformable DETR |
| 混合选择 | 编码器 top-K | 可学习 | DINO |
DINO 发现:编码器选出的 top-K 特征虽然位置信息好,但内容信息可能有歧义(如覆盖多个物体),因此仅用其初始化位置 query,内容 query 保持可学习。
Look Forward Twice:Deformable DETR 的迭代框精炼在层间截断梯度(Look Forward Once)。DINO 允许后层的精炼框梯度回传到前层,使前层也受益于后层的监督信号。
三个关键数字:
- 49.4 AP:DINO (R50, 12 epochs, 5-scale) 在 COCO val2017 上的成绩,仅用 12 epochs 即超越 DN-Deformable-DETR 50 epochs 的 48.6 AP
- 63.3 AP:DINO (SwinL + Objects365) 在 COCO test-dev 上的成绩,首次让端到端检测器登顶 COCO 排行榜
- 32.3 APs:DINO-5scale 12ep 的小目标精度,对比去噪训练显著改善小目标检测
方法设计
整体架构
$$\text{DINO} = \text{Backbone + Encoder} + \text{Mixed Query Selection} + \text{CDN Decoder} + \text{Look Forward Twice}$$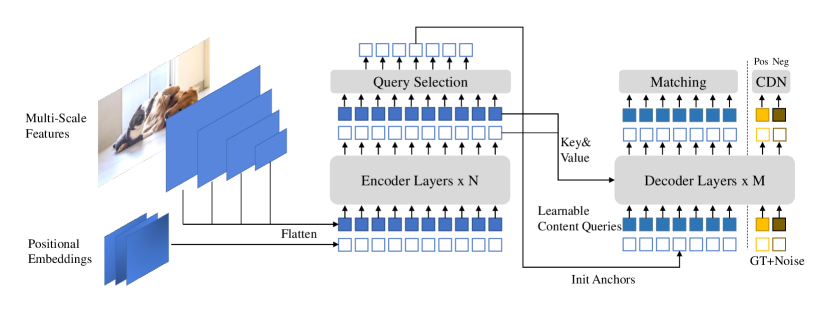
┌─────────────────────────────────────────────────────────────────┐ │ DINO 检测器架构 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ 输入图像 │ │ ↓ │ │ Backbone (ResNet-50 / SwinL) │ │ ↓ │ │ 多尺度特征 (4/5 scales) │ │ ↓ │ │ ┌───────────────────────────────────┐ │ │ │ 6-layer Transformer Encoder │ │ │ │ (可变形注意力, 多尺度特征增强) │ │ │ └───────────────┬───────────────────┘ │ │ ↓ │ │ ┌───────────────────────────────────┐ │ │ │ Mixed Query Selection │ │ │ │ 编码器 top-K → 位置 query 初始化 │ │ │ │ 内容 query → 保持可学习 │ │ │ └───────────────┬───────────────────┘ │ │ ↓ │ │ ┌───────────────────────────────────────────────┐ │ │ │ 6-layer Transformer Decoder │ │ │ │ ┌─────────────┐ ┌──────────────────────┐ │ │ │ │ │ 匹配部分 │ │ CDN 去噪部分 │ │ │ │ │ │ 900 queries │ │ 正样本 + 负样本 │ │ │ │ │ │ (正常检测) │ │ (GT + noise) │ │ │ │ │ └──────┬──────┘ └──────┬───────────────┘ │ │ │ │ ↓ ↓ │ │ │ │ 逐层锚框精炼 (Look Forward Twice) │ │ │ └───────────────────────────────────────────────┘ │ │ ↓ │ │ 预测头: 分类(Focal) + 回归(L1 + GIoU) │ │ 匹配: 匈牙利匹配 (匹配部分) / 确定分配 (CDN部分) │ │ │ └─────────────────────────────────────────────────────────────────┘
关键组件
三论文核心创新对比
| 维度 | DAB-DETR | DN-DETR | DINO |
|---|---|---|---|
| Query 设计 | 4D 锚框 $(x,y,w,h)$ | 沿用 DAB 锚框 | 混合查询选择 |
| 去噪训练 | 无 | 标准去噪(仅正样本) | 对比去噪(正+负样本) |
| 框精炼 | 逐层精炼 | 沿用 DAB + Look Forward Once | Look Forward Twice |
| 查询初始化 | 可学习 | 可学习 | 编码器 top-K 位置 + 可学习内容 |
| 注意力 | 标准注意力 | 可变形注意力 | 可变形注意力 |
| 多尺度 | DC5 (单尺度) | 4-scale | 4/5-scale |
关键代码
| 函数 | 功能 | 来源文件 |
|---|---|---|
prepare_for_cdn |
构造对比去噪正/负 query | dn_components.py |
dn_post_process |
分离去噪输出与匹配输出 | dn_components.py |
📄 点击展开 prepare_for_cdn 代码
(来源:models/dino/dn_components.py)
def prepare_for_cdn(dn_args, training, num_queries, num_classes, hidden_dim, label_enc): |
📄 点击展开 dn_post_process 代码
(来源:models/dino/dn_components.py)
def dn_post_process(outputs_class, outputs_coord, dn_meta, aux_loss, _set_aux_loss): |
损失函数
$$L = \lambda_{cls} L_{cls} + \lambda_{L1} L_{L1} + \lambda_{GIoU} L_{GIoU}$$其中 $\lambda_{cls} = 1.0$,$\lambda_{L1} = 5.0$,$\lambda_{GIoU} = 2.0$。分类使用 Focal Loss($\alpha=0.25, \gamma=2$)。CDN 部分负样本的分类损失同样为 Focal Loss(目标为背景类)。
CDN 超参数
- $\lambda_1 = 1.0$(正样本噪声上界)
- $\lambda_2 = 2.0$(负样本噪声上界)
- 100 CDN pairs(100 正 + 100 负 = 200 个去噪 query)
- 动态分组:根据图像中 GT 数量自动调整组数
实验与分析
主要结果
COCO val2017 (ResNet-50, 12 epochs)
| 方法 | Epochs | AP | AP50 | APs | APm | APl |
|---|---|---|---|---|---|---|
| Faster R-CNN | 36+ | ~42 | — | — | — | — |
| DETR (DC5) | 500 | ~43 | — | — | — | — |
| Deformable DETR (4-scale) | 50 | ~44 | — | — | — | — |
| DN-DETR (4-scale) | 50 | 48.6 | — | — | — | — |
| DINO-4scale | 12 | 49.0 | 66.6 | 32.0 | 52.3 | 63.0 |
| DINO-5scale | 12 | 49.4 | 66.9 | 32.3 | 52.5 | 63.9 |
COCO val2017 (ResNet-50, 更长训练)
| 方法 | Epochs | AP |
|---|---|---|
| DN-Deformable-DETR | 50 | 48.6 |
| DINO-4scale | 24 | 50.4 (+1.8) |
| DINO-5scale | 24 | 51.3 (+2.7) |
| DINO-4scale | 36 | 50.9 (+2.3) |
COCO SOTA 对比(SwinL + Objects365)
| 方法 | 参数 | Backbone 预训练 | 检测预训练 | 端到端 | val2017 | test-dev |
|---|---|---|---|---|---|---|
| SwinV2-G | 3B | IN-22K-ext-70M | O365 | — | — | — |
| Florence | —M | FLD-900M | FLD-9M | — | — | — |
| DINO-SwinL | 218M | IN-22K-14M | O365 | ✓ | 63.2 | 63.3 |
DINO 用 1/15 的参数(vs SwinV2-G)、1/60 的 backbone 预训练数据(vs Florence)即达到最佳结果。
关键发现:
- 12 epoch 即超越所有方法:DINO-5scale (49.4 AP) 在仅 12 epochs 训练下超越了 DN-DETR 50 epochs (48.6 AP),训练效率提升约 4 倍
- 小目标的巨大提升:DINO 12ep 的 APs = 32.3,比 DN-DETR 高约 +7.5,对比去噪训练对小目标尤为有效
- 首次端到端 SOTA:63.3 AP 是第一次端到端 Transformer 检测器在 COCO 排行榜上超越所有传统检测器
消融实验:验证三个洞察
组件渐进消融(Table 4, R50, 12ep, 4-scale)
| 配置 | QS | CDN | LFT | 效果 | 验证洞察 |
|---|---|---|---|---|---|
| 基线 (DN-DETR re-impl.) | — | — | — | 基线 | — |
| + Pure Query Selection | Pure | — | — | AP 提升 | 洞察 3 |
| + Mixed Query Selection | Mixed | — | — | 优于 Pure QS | 洞察 3 |
| + Look Forward Twice | Mixed | — | ✓ | AP 进一步提升 | 洞察 3 |
| + CDN | Mixed | ✓ | — | 小目标显著提升 | 洞察 2 |
| DINO-4scale (全部) | Mixed | ✓ | ✓ | 49.0 AP | 洞察 1+2+3 |
QS=Query Selection, CDN=Contrastive DeNoising, LFT=Look Forward Twice。各步骤的具体中间 AP 数值未在论文中统一列表给出,以上为定性描述;最终 DINO-4scale 12ep 的 49.0 AP 来自论文 Table 1。
CDN 正负样本的效果(Figure 4c)
对比去噪相比标准去噪在小目标上带来 +1.3 AP 的提升,因为 CDN 的负样本教会模型拒绝离 GT 较远的锚框,减少了重复预测。
性能瓶颈分析
| 瓶颈 | 影响 | 解决方向 |
|---|---|---|
| 可变形注意力的采样点固定 | 采样灵活性有限 | 后续 Sparse4D 等方法改进 |
| 900 query 的计算开销 | decoder 自注意力 $O(N^2)$ | 减少 query 数或稀疏注意力 |
| Objects365 预训练成本 | 64 A100, 26 epochs | 更高效的预训练策略 |
失效场景分析
- 训练数据受限时:DINO 的 12-epoch 效率依赖充分的 CDN 正负样本,GT 数量极少(如长尾小样本类)时去噪训练效果打折
- 极密集场景:900 query 对极端密集场景(如百上千个目标的遥感图像)可能不足
- 极小目标:尽管相比前作有大幅提升,5-scale 特征对极小目标仍有局限
工程实践
训练配置
Backbone: ResNet-50 (IN-1K) / SwinL (IN-22K) |
复现要点
- 动态去噪分组:不同图像 GT 数量差异大(COCO 1-80 个),固定组数浪费显存。DINO 固定去噪 query 总数(200),根据 GT 数动态调整组数
- 混合查询选择的关键:只用编码器 top-K 初始化位置 query(锚框),内容 query 保持可学习,避免用可能有歧义的编码器特征误导 decoder
- 共享预测头:DINO 发现共享 decoder 各层的预测头参数(而非 unshared)反而更好,同时减少约 1M 参数
- SwinL 微调的尺度放大:微调时将图像尺寸放大 1.5 倍(shorter side 720-1200, longer side 2000),带来约 +0.5 AP
- CDN 噪声尺度:$\lambda_1=1.0, \lambda_2=2.0$ 是验证过的最优设定,较小的 $\lambda_2$ 更好——靠近 GT 的困难负样本更有信息量
性能优化方向
精度提升:
- 更强 backbone(SwinV2、InternImage)可进一步提升精度,但计算开销也增大
- 增加去噪 query 数量在一定范围内有效(100→200 有提升,200→1000 饱和)
速度优化:
- 减少 decoder 层数(6→2)仅损失约 3 AP,因为混合查询选择已提供了良好的初始化
- query 数从 900 减少到 300 在大多数场景下精度损失可接受
研究启示
可迁移的思想
- **”去噪训练 = 额外的确定性监督”**:DN/CDN 的核心思想是通过注入已知答案(GT + noise)提供不依赖匹配结果的稳定梯度信号,这一策略可应用于任何需要匈牙利匹配的 set prediction 任务(分割、跟踪等)
- **”Query 锚框化”**:将抽象 query 显式绑定到空间位置,降低了学习难度。Sparse4D、PETR 等后续方法均采用了类似的 query 位置先验
- **”对比负样本抑制重复”**:CDN 中的负样本教模型对”差一点”的候选说 No,这一思路适用于任何需要 NMS 替代方案的场景
- **”混合初始化 > 全动态初始化”**:仅初始化位置、保留内容可学习,避免了粗糙编码器特征对 decoder 的误导
方法局限
- 仍需预设 query 数量(900),对不同密度的场景不够自适应
- CDN 训练增加了约 20% 的显存开销(额外 200 个去噪 query 需过 decoder)
- COCO 上的 12-epoch 结果依赖较多工程优化(混合精度、梯度裁剪等),纯净的算法贡献和工程贡献难以完全分离
技术影响
- DETR 家族的拐点:DINO 是第一个在 COCO 上超越传统检测器的端到端 Transformer 检测器,证明了 DETR 范式的上限不低于甚至超越了传统方法
- 去噪训练成为标配:DN/CDN 被 Co-DETR、RT-DETR、Grounding DINO 等后续工作广泛采用
- 推动了 Grounding DINO:DINO 的检测能力与 Grounded Pre-Training 结合,产生了强大的开放集检测器 Grounding DINO
- 影响工业部署:DINO 的高精度和无 NMS 特性使其成为工业级检测方案的有力候选