Task: Sequence Modeling / Visual Representation Learning
Method: Selective State Space Model (S6), 2D Selective Scan
Venue: arXiv 2023 (Mamba) / NeurIPS 2024 Spotlight (VMamba)
Year: 2023–2024
Paper: https://arxiv.org/abs/2312.00752 (Mamba) | https://arxiv.org/abs/2401.10166 (VMamba)
Code: https://github.com/state-spaces/mamba (Mamba) | https://github.com/MzeroMiko/VMamba (VMamba)
摘要
Transformer 凭借注意力机制在序列建模中占据统治地位,但其 $O(N^2)$ 的计算复杂度在长序列上成为瓶颈。Mamba(arXiv 2023,Gu & Dao)提出选择性状态空间模型(Selective State Space Model, S6),通过让 SSM 的参数依赖于输入(input-dependent),解决了传统 SSM 无法进行基于内容推理的根本缺陷。结合硬件感知的并行扫描算法,Mamba 以线性复杂度 $O(N)$ 实现了比 Transformer 快 5 倍的吞吐量。Mamba-3B 在语言建模上媲美两倍参数量的 Transformer,同时在音频和基因组学上也达到 SOTA。
VMamba(NeurIPS 2024 Spotlight,Liu et al.)将 Mamba 引入视觉领域。核心挑战是:1D 选择性扫描如何处理 2D 图像的非序列结构?VMamba 提出 2D 选择性扫描(SS2D)——通过四个方向(左上→右下、右下→左上、左下→右上、右上→左下)遍历特征图,使每个位置能聚合全局信息。基于此构建 Visual State Space(VSS)模块,VMamba-B 在 ImageNet-1K 上达到 83.9% top-1 精度,同时在 COCO 检测(MaskRCNN 49.2 AP)和 ADE20K 分割(UperNet 51.0 mIoU)上超越同量级 Swin Transformer。
核心论点:Transformer 的注意力机制并非序列建模的唯一解——选择性状态空间模型通过输入依赖的参数化实现了内容感知推理,同时保持线性计算复杂度。VMamba 的 2D 扫描策略证明了 SSM 架构在视觉任务中的可行性和竞争力。
问题与动机
序列建模架构在效率和表达能力之间长期存在权衡:
| 架构类型 | 代表作 | 时间复杂度 | 长序列性能 | 内容推理能力 |
|---|---|---|---|---|
| Transformer | GPT, ViT | $O(N^2)$ | 优 (但慢) | 强 |
| 线性注意力 | Linear Transformer | $O(N)$ | 中 | 弱 |
| 传统 SSM | S4, H3 | $O(N)$ | 优 (连续信号) | 弱 (LTI) |
| CNN (门控) | RWKV, Hyena | $O(N)$ | 中 | 中 |
传统 SSM(如 S4)在连续信号(音频、时序)上表现优异,但在语言等离散模态上明显弱于 Transformer。Mamba 的作者 Albert Gu 和 Tri Dao 发现,问题的根源在于 SSM 的 LTI(线性时不变)性质——参数不依赖输入内容,因此无法根据当前 token 决定保留还是遗忘历史信息。
在视觉领域,虽然 ViT 已确立主导地位,但 $O(N^2)$ 的全局注意力在高分辨率输入(如 1024×1024)下计算量激增。Swin Transformer 通过窗口注意力缓解但牺牲了全局感受野。需要一种线性复杂度且具全局感受野的视觉 backbone。
核心痛点:(1)如何让 SSM 具备 Transformer 的内容推理能力而保持线性复杂度?(2)如何将 1D 扫描机制适配 2D 视觉数据?
核心洞察
洞察 1:选择性机制——让 SSM 参数依赖输入
传统 SSM(S4):状态空间方程为 LTI(线性时不变)系统:
$$h'(t) = Ah(t) + Bx(t), \quad y(t) = Ch(t)$$离散化后 $\bar{A}, \bar{B}$ 与输入 $x$ 无关,因此对所有 token 使用相同的状态转移矩阵。这等价于一个全局卷积,无法区分哪些 token 重要、哪些应遗忘。
Mamba 做法(S6):让离散化步长 $\Delta$、投影矩阵 $B$ 和 $C$ 成为输入的函数:
$$B = S_B(x), \quad C = S_C(x), \quad \Delta = \text{softplus}(S_\Delta(x))$$其中 $S_B, S_C, S_\Delta$ 为线性投影。这使得:
- **大 $\Delta$**:忽略当前输入,更多依赖历史状态(类似 “跳过”)
- **小 $\Delta$**:重视当前输入,选择性记忆
代价与解决:参数输入依赖(即 time-varying)破坏了 SSM 的卷积表示,无法用 FFT 加速。Mamba 设计了硬件感知的并行扫描算法——在 GPU SRAM 中完成扫描运算,避免 HBM 的 I/O 瓶颈:
- 不将 $(\bar{A}, \bar{B})$ 展开为完整矩阵(节省 HBM 读写)
- 用并行前缀扫描(parallel prefix scan)实现 $O(N)$ 递推
- 反向传播时重新计算中间状态(避免存储 $O(N)$ 状态)
洞察 2:极简架构——去掉注意力和 MLP
Transformer block:Self-Attention + MLP,两个子模块各自占约一半计算量。
Mamba block:将选择性 SSM 嵌入一个类似 H3/门控 MLP 的简化架构:
- 输入线性投影 → 两路(expand ratio = 2)
- 一路:1D 卷积(kernel=4)→ SiLU → 选择性 SSM
- 另一路:SiLU(门控)
- 两路逐元素相乘 → 线性投影输出
没有注意力层、没有独立的 MLP block。整个网络是均匀堆叠的 Mamba block(类似 ResNet 堆叠残差块),参数效率极高。
洞察 3:2D 选择性扫描——从 1D 序列到 2D 视觉
Mamba 的局限:选择性扫描沿单一方向处理序列,天然适合 1D(文本、音频)。但 2D 图像不存在天然的扫描顺序——简单的行优先展开(如 ViT 的 patch 序列化)会丢失空间局部性。
VMamba 做法(SS2D):在 $H \times W$ 特征图上设计四个扫描方向:
- 左上 → 右下(行优先)
- 右下 → 左上(反向)
- 左下 → 右上
- 右上 → 左下
每个方向独立运行选择性扫描,最后将四路输出合并。这样每个位置都能通过至少一个方向与所有其他位置建立信息通路——等效于全局感受野。
VSS block 结构:
- 输入线性投影 → 两路
- 一路:DWConv 3×3 → SiLU → SS2D(四方向扫描)
- 另一路:SiLU(门控)
- 逐元素相乘 → 线性投影输出
VMamba 按层级设计(类似 Swin Transformer),每个 stage 下采样 2 倍。
效果:VMamba 具有全局有效感受野(ERF),类似 ViT 但计算量对序列长度线性增长。
三个关键数字:
- 5×:Mamba 相比 Transformer 的推理吞吐量提升倍数,得益于线性复杂度和硬件感知算法
- **83.9%**:VMamba-B 在 ImageNet-1K 上的 top-1 精度,以 89M 参数超越同量级 Swin-B (83.5%)
- 49.2 AP:VMamba-B 使用 Mask R-CNN@1x 在 COCO 上的检测精度,比 Swin-B (46.9) 高 +2.3
方法设计
整体架构
$$\text{Mamba} = \text{Linear Projection} + \text{1D Conv} + \text{Selective SSM (S6)} + \text{Gating}$$ $$\text{VMamba} = \text{Patch Embedding} + \text{VSS Blocks (SS2D)} + \text{Hierarchical Downsampling}$$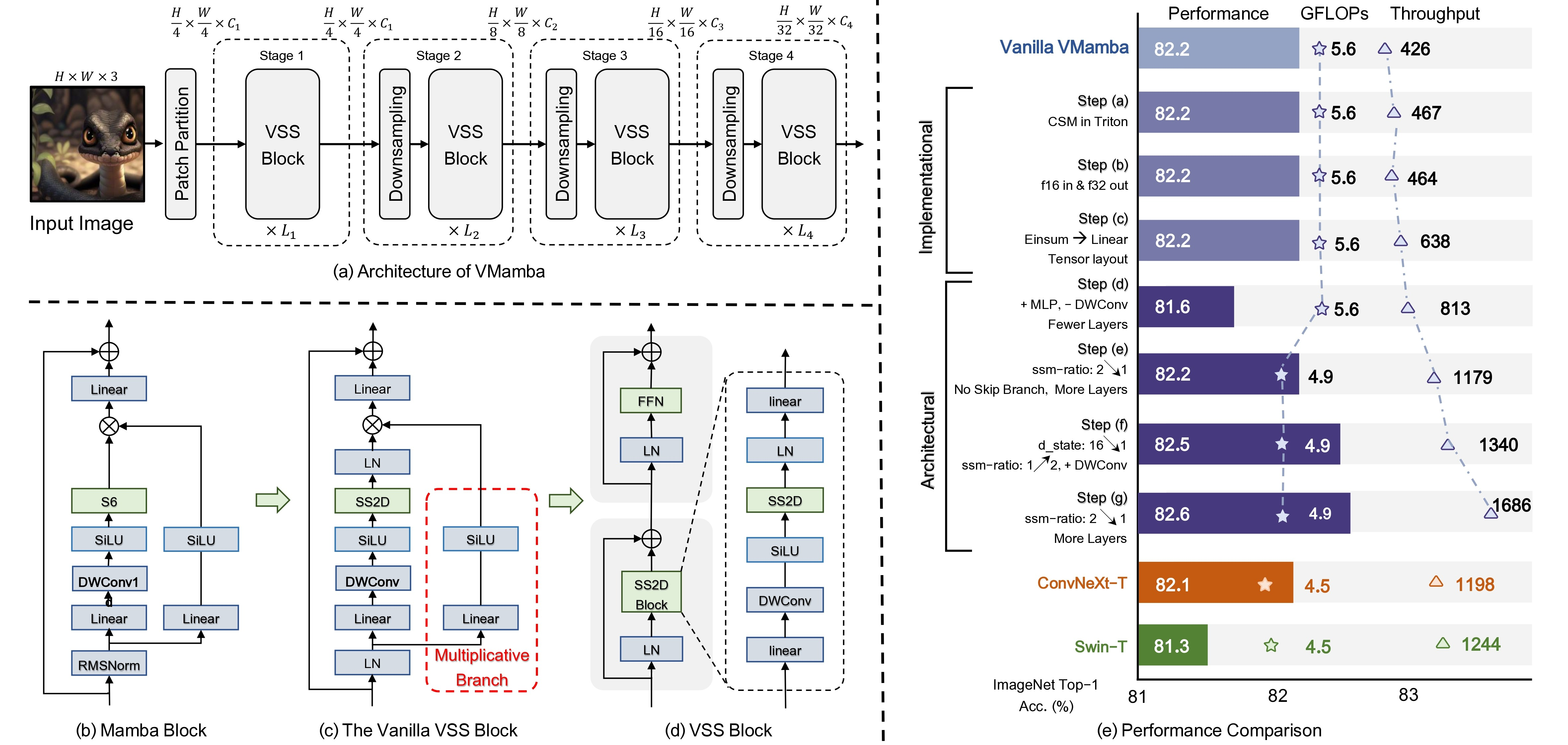
┌─────────────────────────────────────────────────────────────────┐ │ Mamba Block (1D) │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ 输入 x ──→ Linear ──┬──→ Conv1D(k=4) → SiLU → SSM (S6) ─────┐ │ │ │ │ │ │ └──→ SiLU (gate) ──────────────────→ ⊗ │ │ │ │ │ Linear ←─┘ │ │ ↓ │ │ 输出 │ └─────────────────────────────────────────────────────────────────┘┌─────────────────────────────────────────────────────────────────┐
│ VMamba / VSS Block (2D) │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 输入 (H×W×C) │
│ ↓ │
│ LayerNorm │
│ ↓ │
│ Linear ──→ 两路分支 │
│ ┌────────────────┐ ┌────────────────────────────┐ │
│ │ DWConv 3×3 │ │ SiLU (gate) │ │
│ │ SiLU │ │ │ │
│ │ SS2D: │ │ │ │
│ │ ┌→ 左上→右下 │ │ │ │
│ │ ├→ 右下→左上 │ │ │ │
│ │ ├→ 左下→右上 │ │ │ │
│ │ └→ 右上→左下 │ │ │ │
│ │ 合并四路输出 │ │ │ │
│ └───────┬────────┘ └──────────┬─────────────────┘ │
│ └────────── ⊗ ───────────┘ │
│ │ │
│ Linear → 输出 + 残差 │
└─────────────────────────────────────────────────────────────────┘┌─────────────────────────────────────────────────────────────────┐
│ VMamba 层级结构 │
├─────────────────────────────────────────────────────────────────┤
│ Stage 1: Patch Embed (4×4, stride 4) → VSS blocks │
│ Stage 2: Downsample (2×) → VSS blocks │
│ Stage 3: Downsample (2×) → VSS blocks │
│ Stage 4: Downsample (2×) → VSS blocks │
│ │
│ VMamba-T[s1l8]: layers = [2,2,8,2], dims = […], 30M │
│ VMamba-S[s2l15]: layers = [2,2,15,2], dims = […], 50M │
│ VMamba-B[s2l15]: layers = [2,2,15,2], dims = […], 89M │
└─────────────────────────────────────────────────────────────────┘
关键组件
Mamba vs VMamba 对比
| 维度 | Mamba | VMamba |
|---|---|---|
| 目标任务 | 语言、音频、基因组 | 图像分类、检测、分割 |
| 扫描方式 | 单向 1D 扫描 | 四方向 2D 扫描 (SS2D) |
| 架构风格 | 均匀堆叠(类 GPT) | 层级下采样(类 Swin) |
| 输入处理 | Token 嵌入 | Patch Embedding + Downsample |
| 计算复杂度 | $O(N)$ | $O(HW)$ = $O(N)$ |
| 参数量 | 130M–2.8B (语言模型) | 30M–89M (视觉 backbone) |
选择性 SSM 的数学形式
连续系统:
$$h'(t) = Ah(t) + Bx(t), \quad y(t) = Ch(t)$$离散化(零阶保持):
$$\bar{A} = \exp(\Delta A), \quad \bar{B} = (\Delta A)^{-1}(\exp(\Delta A) - I) \cdot \Delta B$$选择性参数化(Mamba S6):
$$\Delta = \text{softplus}(W_\Delta x + b_\Delta), \quad B = W_B x, \quad C = W_C x$$其中 $W_\Delta, W_B, W_C$ 为可学习线性投影。A 保持固定(对角矩阵),仅通过 $\Delta$ 的变化间接改变 $\bar{A}$。
关键代码
| 函数/类 | 功能 | 来源文件 |
|---|---|---|
cross_scan_fwd |
四方向 2D 扫描展开 | vmamba.py |
SS2Dv0.forwardv0 |
SS2D 核心前向传播 | vmamba.py |
VSSBlock._forward |
VSS block 结构 | vmamba.py |
📄 点击展开 cross_scan_fwd(四方向扫描)代码
(来源:vmamba.py)
def cross_scan_fwd(x: torch.Tensor, in_channel_first=True, out_channel_first=True, scans=0): |
📄 点击展开 SS2Dv0.forwardv0(SS2D 前向传播)代码
(来源:vmamba.py)
def forwardv0(self, x: torch.Tensor, seq=False, force_fp32=True, **kwargs): |
实验与分析
主要结果
Mamba 语言建模(从论文摘要和已知结果)
Mamba-3B 在预训练和下游评估中匹配两倍参数量的 Transformer,推理吞吐量提升 5 倍。在音频(SC10 和 SpeechCommands)和基因组学(Species DNA)上达到 SOTA。
注:Mamba 论文的具体 perplexity 和下游数值较多,此处列出核心结论,详细数据请参阅原文 Table 3-5。
VMamba ImageNet-1K 分类
| 方法 | 参数 | FLOPs | Top-1 | 吞吐量 (im/s) |
|---|---|---|---|---|
| Swin-T | 28M | 4.5G | 81.2 | 1244 |
| VMamba-T | 30M | 4.9G | 82.6 | 1686 |
| Swin-S | 50M | 8.7G | 83.2 | 718 |
| VMamba-S | 50M | 8.7G | 83.6 | 877 |
| Swin-B | 88M | 15.4G | 83.5 | 458 |
| VMamba-B | 89M | 15.4G | 83.9 | 646 |
VMamba COCO 检测(Mask R-CNN)
| Backbone | 参数 | FLOPs | Schedule | bbox AP | segm AP |
|---|---|---|---|---|---|
| Swin-T | 48M | 267G | 1x | 42.7 | 39.3 |
| VMamba-T | 50M | 271G | 1x | 47.3 | 42.7 |
| Swin-S | 69M | 354G | 1x | 44.8 | 40.9 |
| VMamba-S | 70M | 384G | 1x | 48.7 | 43.7 |
| Swin-B | 107M | 496G | 1x | 46.9 | 42.3 |
| VMamba-B | 108M | 485G | 1x | 49.2 | 44.1 |
VMamba ADE20K 分割(UperNet@160k)
| Backbone | 参数 | FLOPs | mIoU (SS) | mIoU (MS) |
|---|---|---|---|---|
| Swin-T | 60M | 945G | 44.4 | 45.8 |
| VMamba-T | 62M | 949G | 47.9 | 48.8 |
| Swin-S | 81M | 1039G | 47.6 | 49.5 |
| VMamba-S | 82M | 1028G | 50.6 | 51.2 |
| Swin-B | 121M | 1188G | 48.1 | 49.7 |
| VMamba-B | 122M | 1170G | 51.0 | 51.6 |
关键发现:
- VMamba 全面超越同量级 Swin:在分类、检测、分割三项任务上,VMamba-T/S/B 均超越对应的 Swin-T/S/B,且在分类上吞吐量更高(VMamba-T 1686 vs Swin-T 1244 im/s)
- 检测和分割的提升更显著:VMamba-B 在 COCO 检测上比 Swin-B 高 +2.3 AP,在 ADE20K 分割上高 +2.9 mIoU——全局感受野对密集预测任务的增益大于分类
- 线性复杂度的实际优势:VMamba 的吞吐量随分辨率增大优势更明显——当序列长度增加时,Transformer 的 $O(N^2)$ 使延迟急剧增长,而 VMamba 保持线性增长
消融实验:验证三个洞察
洞察 1 验证:选择性 vs 非选择性(来自 Mamba 论文)
Mamba 论文通过合成任务验证了选择性机制的必要性。在 Selective Copying 和 Induction Heads 任务上,标准 S4(LTI)完全失败,而 Mamba(S6)完美解决,因为这些任务本质上需要根据内容决定何时记忆和何时遗忘。
洞察 2 验证:Mamba block vs Transformer block
在相同参数量下,Mamba block 因取消了独立 MLP 和注意力机制,序列处理效率更高。Mamba-3B 匹配 Transformer-6.7B(2× 参数)验证了架构效率。
洞察 3 验证:四方向扫描的必要性
VMamba 通过有效感受野(ERF)分析验证了 SS2D 的效果——四方向扫描后每个位置的 ERF 覆盖整个特征图,类似 ViT 的全局注意力,但 Swin 的 ERF 仅覆盖局部窗口。
性能瓶颈分析
| 瓶颈 | 影响 | 解决方向 |
|---|---|---|
| 四方向扫描的序列化开销 | 四条 1D 路径各自独立扫描 | Mamba2 的更高效实现 |
| 自定义 CUDA 核的维护成本 | 依赖特定 CUDA 版本和驱动 | 框架级集成 (PyTorch 原生) |
| causal 性质限制 | 每条扫描路径仅看单向上下文 | 双向变体(如 Vim 的 bidirectional) |
失效场景分析
- 需要精确 token 间交互的任务:SSM 通过压缩状态传递信息,不如注意力机制能精确地在任意两个位置间建立直接连接
- 极端长序列的训练稳定性:虽然推理时线性,但训练时并行扫描在极长序列上的数值稳定性需要仔细工程
- 硬件兼容性:Mamba 的 CUDA 实现依赖特定硬件特性(如 SRAM 大小),在非 NVIDIA 硬件上的移植和优化需额外工作
- 2D 扫描的顺序假设:SS2D 的四方向遍历仍是人为设定的——对于某些具有特殊空间结构的数据(如环形全景图),可能需要不同的扫描策略
工程实践
训练配置
**VMamba (NeurIPS 2024)**:
Backbone: VMamba-T/S/B |
**检测 (COCO)**:
Detector: Mask R-CNN (1x / 3x schedule) |
**分割 (ADE20K)**:
Segmentor: UperNet@160k |
复现要点
- CUDA 环境严格要求:Mamba/VMamba 依赖自定义 CUDA 核(selective_scan_cuda),需 PyTorch≥2.0 + CUDA≥11.8,不兼容的版本会导致编译失败或数值错误
- cudnn.enabled 的影响:在下游任务中使用
torch.backends.cudnn.enabled=True可能导致 VMamba 显著变慢,需在 vmamba.py 中禁用 - FLOPs 计算注意:VMamba 的 FLOPs 使用了 Mamba 作者提供的硬件感知算法计算,比基于 selective_scan_ref 的朴素计算更大(后者忽略了 IO 部分)
- SS2D 的实现:四方向扫描通过展开 2D 特征图为四条 1D 序列实现,可利用 Mamba2 的更高效扫描原语加速
- 下游任务的初始化:检测和分割模型从分类预训练初始化——与 Swin 的做法一致,预训练质量直接影响下游精度
性能优化方向
精度提升:
- 更大模型(VMamba-L/XL)有望进一步提升精度,但需更多训练资源
- 结合自监督预训练(如 DINOv2 式蒸馏)可能释放 VMamba 在大规模数据上的潜力
速度优化:
- Mamba2 提供了 2-8× 更快的 SSM 实现,VMamba 已支持 Mamba2 后端
- 减少扫描方向数(4→2)可加速但可能损失精度,需权衡
- 量化(INT8/FP16)对 SSM 的适配已有初步探索
研究启示
可迁移的思想
- **”输入依赖的参数 = 选择性记忆”**:Mamba 的核心洞察——让模型参数依赖输入以实现选择性信息保留——适用于任何需要长距离依赖建模的场景,如时序预测、强化学习中的状态压缩
- **”线性复杂度不意味着弱表达力”**:Mamba 证明了线性模型通过选择性机制可匹敌二次复杂度的注意力,这对高分辨率视觉、长视频理解等序列长度敏感的任务有重要启示
- **”多方向扫描 = 2D 全局感受野”**:VMamba 的 SS2D 策略可推广到 3D(体素、点云)甚至图结构数据——关键是设计覆盖全空间的扫描路径
- **”简化架构设计”**:Mamba 去掉了注意力和独立 MLP,仅用门控 SSM 一种模块统一序列建模——这种极简设计理念(fewer types of blocks, more uniform stacking)值得借鉴
方法局限
- 选择性扫描的 causal 性质(每条路径只看单向)使得全局信息聚合依赖多路合并,不如注意力的直接全对全交互精确
- 自定义 CUDA 核的工程维护成本高,限制了社区的快速迭代和跨平台部署
- VMamba 的四方向扫描在序列极长时(如 4K 图像),四倍的扫描开销使实际速度优势减弱
技术影响
- 开辟 SSM 在视觉中的应用:VMamba 和同期的 Vision Mamba (Vim) 证明了 SSM 架构在视觉任务中的可行性,引发了 MambaOut、LocalMamba、PlainMamba 等大量后续工作
- 推动高效架构研究:Mamba 重新点燃了学术界对亚二次复杂度架构的兴趣,与 RWKV、xLSTM 等工作共同挑战 Transformer 的统治地位
- 影响自动驾驶感知:VMamba 的线性复杂度和全局感受野对高分辨率多摄像头 BEV 感知有潜在优势,已有 MambaAD 等方法探索将 Mamba 用于自动驾驶
- Mamba2 的后续演进:Mamba 作者发布的 Mamba2 通过建立 SSM 与注意力的理论联系(State Space Duality),实现了 2-8× 的进一步加速