Task: End-to-End Autonomous Driving (Detection, Tracking, Mapping, Motion, Occupancy, Planning)
Method: Unified Query-based Multi-task Framework, Planning-oriented Design
Venue: CVPR 2023 Best Paper
Year: 2022
Paper: https://arxiv.org/abs/2212.10156
Code: https://github.com/OpenDriveLab/UniAD
摘要
现代自动驾驶系统采用模块化设计,按顺序执行感知、预测和规划任务。现有方案要么部署独立模型(信息损失+误差累积),要么简单多任务学习(负迁移)。本文提出 UniAD(Unified Autonomous Driving),首个涵盖检测、跟踪、建图、运动预测、占用预测与规划的全栈端到端框架。核心设计是以 query 作为统一接口连接所有模块——TrackFormer 用 track query 编码智能体、MapFormer 用 map query 编码道路元素、MotionFormer 用 motion query 联合预测多智能体轨迹、OccFormer 用 BEV 特征与智能体特征交互预测未来占用、Planner 利用 ego query 在 BEV 上做注意力后预测规划轨迹并用占用图做碰撞优化。在 nuScenes 上,UniAD 在所有任务上显著超越前人方法,规划 L2 误差降低 51.2%、碰撞率降低 56.3%(相比 ST-P3)。
核心论点:端到端自动驾驶的关键不是简单堆叠任务,而是以规划为导向、通过 query 接口协调各模块的信息流——每个前置任务都应为最终规划服务。
问题与动机
自动驾驶系统需要同时完成检测、跟踪、建图、运动预测、占用预测和规划。现有方案存在明显局限:
| 方案设计 | 代表作 | 核心问题 |
|---|---|---|
| 独立模型 | Mobileye, NVIDIA DRIVE | 模块间信息损失、误差累积、特征不对齐 |
| 多任务学习 | BEVerse, NMP | 共享 backbone + 独立 head,任务间负迁移 |
| 端到端(直接规划) | 行为克隆方法 | 无中间表示,缺乏安全保障和可解释性 |
| 端到端(部分组件) | PnPNet, ST-P3, MP3 | 缺少部分关键任务(如跟踪或建图),任务协调不充分 |
核心痛点:如何设计一个端到端框架,让感知和预测的所有任务都为规划服务,同时避免独立模型的误差累积和多任务学习的负迁移?关键挑战在于模块间的信息传递——如何让检测 → 跟踪 → 运动预测 → 占用预测 → 规划形成协调一致的信息流。
核心洞察
洞察 1:Query 作为统一接口——连接全栈任务的信息管道
传统做法:独立模型间通过 bounding box 等结构化输出传递信息,信息压缩严重(box 无法编码丰富的上下文特征);多任务学习共享 backbone 但 head 独立,任务间无交互。
UniAD 做法:所有模块统一使用 Transformer decoder 结构,以 query 作为连接接口:
- Track query $Q_A$:编码智能体信息,从 TrackFormer → MotionFormer → OccFormer
- Map query $Q_M$:编码道路语义,从 MapFormer → MotionFormer
- Ego query:特殊的 track query,从 TrackFormer → MotionFormer → Planner
- 匹配结果在 TrackFormer 中确定后,被下游 MotionFormer 和 OccFormer 共享复用
为什么更好:query 拥有全局感受野,能编码比 bounding box 更丰富的特征信息。当某个模块预测不准时(如检测漏了目标),下游模块仍可通过 BEV 特征和注意力机制部分恢复。消融实验(Table 2)显示,完整 UniAD(Exp.12)相比朴素多任务学习(Exp.0)在运动预测上提升 15.2% minADE,规划碰撞率降低 0.51 个百分点。
洞察 2:双类型预测互补——运动预测 + 占用预测联合提升规划安全
传统做法:运动预测(稀疏、智能体级)和占用预测(稠密、场景级)分别独立使用,前者保留身份但非可微,后者可微但缺身份。
UniAD 做法:同时引入运动预测和占用预测两种互补的预测任务。运动预测提供智能体个体的多模态未来轨迹(6 个模式 × 12 步),占用预测提供场景级的稠密未来占用图(5 步)。规划模块利用 ego query 的运动信息做初始轨迹预测,再用占用图做碰撞优化。
为什么更好:消融实验(Table 2, Exp.10-12)显示,单独使用运动预测或占用预测做规划均不如二者联合:完整模型(Exp.12)的碰撞率为 0.430%,仅用 Planner(Exp.10)为 0.773%,仅用运动+感知(Exp.9)为无法评估。两类预测分别提供了智能体级动态(谁会怎么动)和场景级约束(哪里会被占据),共同保障规划安全。
洞察 3:感知为预测服务——跟踪和建图对运动预测的关键作用
传统做法:检测、跟踪和建图作为独立感知任务,其输出直接提供给下游使用,不关注对后续任务的贡献。
UniAD 做法:将跟踪和建图嵌入端到端管线,其输出 query 直接供 MotionFormer 使用——Track query 提供历史轨迹和身份信息(agent-agent 交互),Map query 提供道路结构(agent-map 交互),两者合力使运动预测精度大幅提升。
为什么更好:Table 2 Exp.4-6 显示,纯 MotionFormer 的 minADE 为 0.815,加入 TrackFormer 后降至 0.751(-7.9%),再加入 MapFormer 后降至 0.736(-9.7%),建图和跟踪共同为运动预测带来了 -12.9% minFDE 的提升。且感知模块在共同训练中 不出现显著性能下降。
三个关键数字:
- 1.03m avg L2:UniAD-B 的规划平均 L2 误差,比 ST-P3(2.11m)降低 51.2%
- 0.31% avg Col:UniAD-B 的规划平均碰撞率,比 ST-P3(0.71%)降低 56.3%
- 0.71 minADE:UniAD 的运动预测精度,比 PnPNet-vision(1.15)降低 38.3%
方法设计
整体架构
UniAD 的全栈管线:
$$\text{多视图图像} \xrightarrow{\text{BEVFormer}} \text{BEV 特征}\ B \xrightarrow{\text{TrackFormer}} Q_A \xrightarrow{\text{MapFormer}} Q_M \xrightarrow[\text{OccFormer}]{\text{MotionFormer}} \xrightarrow{\text{Planner}} \tau^*$$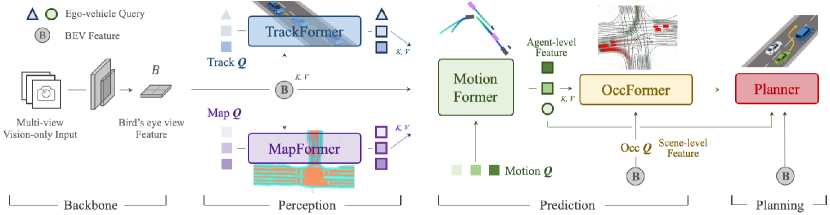
多视图 6 cam
│
▼
┌─────────────────┐
│ BEVFormer │ ResNet-101 + FPN + 时空注意力
│ (BEV Encoder) │ 输出:B ∈ R^{200×200×256}
└─────┬───────────┘
│
├──────────────────────┐
▼ ▼
┌─────────────┐ ┌─────────────┐
│ TrackFormer │ │ MapFormer │
│ 6 layers │ │ 6+4 layers │
│ Det+Track Q │ │ 300 Thing │
│ → Q_A, ego Q│ │ → Q_M │
└──┬──────────┘ └──┬──────────┘
│ │
├─► agent-agent ◄─────┘
├─► agent-map ◄─────┘
▼
┌─────────────────────────┐
│ MotionFormer (3 layers) │ agent-agent + agent-map + agent-goal
│ 输入:Q_A, Q_M, B │ 输出:K=6 模态 × T=12 步轨迹
│ + ego query 特殊处理 │ + ego-vehicle query 更新
└──┬─────────────┬────────┘
│ │
▼ ▼
┌──────────┐ ┌──────────────────┐
│OccFormer │ │ Planner(3 layers)│
│ 5 blocks │ │ ego Q + cmd emb │
│ pixel- │ │ → BEV 注意力 │
│ agent │ │ → 轨迹 τ^ │
│ interact │ │ + 占用碰撞优化 │
└──┬───────┘ └──┬───────────────┘
│ │
└──► 占用图 O^ ──► 碰撞优化 → τ*
关键组件
| 模块 | 输入 | 输出 | 层数 | 核心设计 |
|---|---|---|---|---|
| BEVFormer | 多视图图像 | BEV 特征 $B$ | — | BEVFormer 编码器(空间/时序注意力) |
| TrackFormer | $B$ | $Q_A$(智能体 query) | 6 | 检测 query + track query 时序传播 |
| MapFormer | $B$ | $Q_M$(地图 query) | 6+4 | Panoptic SegFormer,thing + stuff query |
| MotionFormer | $Q_A, Q_M, B$ | $K \times T$ 轨迹 | 3 | agent-agent / agent-map / agent-goal 交互 |
| OccFormer | $B, Q_A$, motion query | 实例级占用图 | 5 | pixel-agent 交互 + 注意力掩码 |
| Planner | ego query, $B$, 命令嵌入 | 规划轨迹 $\tau^*$ | 3 | BEV 注意力 + 占用碰撞优化 |
MotionFormer 三类交互:
$$Q_a = \text{MHCA}(\text{MHSA}(Q), Q_A), \quad Q_m = \text{MHCA}(\text{MHSA}(Q), Q_M)$$ $$Q_g = \text{DeformAttn}(Q, \hat{\mathbf{x}}_T^{l-1}, B)$$三路输出拼接后通过 MLP 融合。其中 agent-goal 交互使用可变形注意力在预测终点附近采样 BEV 特征,实现逐层 coarse-to-fine 的轨迹精化。
Motion Query 的位置编码(四重先验):
$$Q_{\text{pos}} = \text{MLP}(\text{PE}(I_s)) + \text{MLP}(\text{PE}(I_a)) + \text{MLP}(\text{PE}(\hat{\mathbf{x}}_0)) + \text{MLP}(\text{PE}(\hat{\mathbf{x}}_T^{l-1}))$$其中 $I_s$ 为场景级 anchor、$I_a$ 为智能体级 anchor(均由 k-means 聚类得到)、$\hat{\mathbf{x}}_0$ 为当前位置、$\hat{\mathbf{x}}_T^{l-1}$ 为上一层预测的终点。
OccFormer 的 pixel-agent 交互:
$$D_{\text{ds}}^t = \text{MHCA}(\text{MHSA}(F_{\text{ds}}^t), G^t, \text{attn\_mask} = O_m^t)$$使用占用引导的注意力掩码约束每个像素仅关注占据它的智能体,保持稀疏且高效。实例级占用直接通过矩阵乘 $\hat{O}_A^t = U^t \cdot F_{\text{dec}}^t$ 得到。
Planner 碰撞优化:
$$\tau^* = \arg\min_{\tau} \lambda_{\text{coord}} \|\tau, \hat{\tau}\|_2 + \lambda_{\text{obs}} \sum_t \mathcal{D}(\tau_t, \hat{O}^t)$$其中 $\mathcal{D}$ 为高斯距离场,将轨迹推离已占用区域。仅在推理时使用 Newton 法优化。
损失函数:
训练分两阶段:
$$\mathcal{L}_1 = \mathcal{L}_{\text{track}} + \mathcal{L}_{\text{map}} \quad \text{(Stage 1, 6 epochs)}$$ $$\mathcal{L}_2 = \mathcal{L}_{\text{track}} + \mathcal{L}_{\text{map}} + \mathcal{L}_{\text{motion}} + \mathcal{L}_{\text{occ}} + \mathcal{L}_{\text{plan}} \quad \text{(Stage 2, 20 epochs)}$$- $\mathcal{L}_{\text{track}}$: Focal Loss + L1 Loss(匈牙利匹配)
- $\mathcal{L}_{\text{map}}$: Focal + L1 + GIoU + Dice(Panoptic 分割)
- $\mathcal{L}_{\text{motion}}$: 分类损失 + NLL 损失(GMM 多模态轨迹)
- $\mathcal{L}_{\text{occ}}$: BCE + Dice(实例级二值占用)
- $\mathcal{L}_{\text{plan}}$: 模仿 L2 + 碰撞 IoU 损失
实验与分析
主要结果
nuScenes val(各任务对比)
跟踪(Table 3):
| 方法 | AMOTA↑ | AMOTP↓ | Recall↑ | IDS↓ |
|---|---|---|---|---|
| ViP3D | 0.217 | 1.625 | 0.363 | — |
| MUTR3D | 0.294 | 1.498 | 0.427 | 3822 |
| UniAD | 0.359 | 1.320 | 0.467 | 906 |
运动预测(Table 5):
| 方法 | minADE↓ | minFDE↓ | MR↓ | EPA↑ |
|---|---|---|---|---|
| PnPNet | 1.15 | 1.95 | 0.226 | 0.222 |
| ViP3D | 2.05 | 2.84 | 0.246 | 0.226 |
| UniAD | 0.71 | 1.02 | 0.151 | 0.456 |
规划(Table 7):
| 方法 | L2 1s↓ | L2 2s↓ | L2 3s↓ | avg L2↓ | Col 1s↓ | Col 2s↓ | Col 3s↓ | avg Col↓ |
|---|---|---|---|---|---|---|---|---|
| FF | 0.55 | 1.20 | 2.54 | 1.43 | 0.06 | 0.17 | 1.07 | 0.43 |
| ST-P3 | 1.33 | 2.11 | 2.90 | 2.11 | 0.23 | 0.62 | 1.27 | 0.71 |
| UniAD | 0.48 | 0.96 | 1.65 | 1.03 | 0.05 | 0.17 | 0.71 | 0.31 |
三种模型规模对比(Table 12)
| 变体 | Backbone | AMOTA↑ | minADE↓ | IoU-n↑ | avg L2↓ | avg Col↓ |
|---|---|---|---|---|---|---|
| UniAD-S | R50 | 0.241 | 0.788 | 59.4 | 1.04 | 0.32 |
| UniAD-B | R101 | 0.359 | 0.708 | 63.4 | 1.03 | 0.31 |
| UniAD-L | V2-99 | 0.409 | 0.723 | 64.1 | 1.03 | 0.29 |
消融实验:验证三个洞察
全栈任务的必要性(Table 2,洞察 1+2+3)
| ID | Track | Map | Motion | Occ | Plan | minADE↓ | avg L2↓ | avg Col↓ |
|---|---|---|---|---|---|---|---|---|
| 0 (MTL) | ✓ | ✓ | ✓ | ✓ | ✓ | 0.858 | 1.15 | 0.93 |
| 4 | — | — | ✓ | — | — | 0.815 | — | — |
| 6 | ✓ | ✓ | ✓ | — | — | 0.736 | — | — |
| 10 | — | — | — | — | ✓ | — | 1.131 | 0.773 |
| 12 | ✓ | ✓ | ✓ | ✓ | ✓ | 0.728 | 1.004 | 0.430 |
关键发现:
- 完整 UniAD(Exp.12)比朴素 MTL(Exp.0)在 minADE 上提升 15.2%、碰撞率降低 0.51 个百分点
- Track + Map 使 MotionFormer 的 minADE 从 0.815 降至 0.736(**-9.7%**),minFDE 降低 12.9%
- 同时引入 Motion + Occ 做规划(Exp.12)比仅 Planner(Exp.10)碰撞率降低 44%(0.773→0.430)
MotionFormer 设计消融(Table 8)
| 场景 anchor | goal 交互 | ego Query | NLO | minADE↓ | MR↓ |
|---|---|---|---|---|---|
| — | — | — | — | 0.844 | 0.177 |
| ✓ | — | — | — | 0.768 | 0.164 |
| ✓ | ✓ | — | — | 0.755 | 0.168 |
| ✓ | ✓ | ✓ | — | 0.747 | 0.156 |
| ✓ | ✓ | ✓ | ✓ | 0.710 | 0.146 |
计算复杂度(Table 13)
| 模块组合 | 参数量 | FLOPs | FPS (A100) |
|---|---|---|---|
| BEVFormer Only | 65.9M | 1324G | 4.2 |
| + Track | 68.2M | 1326G | 2.7 |
| + Map | 95.8M | 1520G | 2.2 |
| + Motion | 108.6M | 1535G | 2.1 |
| + Occ | 122.5M | 1701G | 2.0 |
| + Plan (Full) | 125.0M | 1709G | 1.8 |
失效场景分析
- 长尾场景:大型拖挂车、施工区域等训练数据稀少的场景,所有模块精度均下降
- 暗光环境:夜间场景下,Planner 因碰撞 loss 可能过于保守
- 远距离目标:BEV 范围 51.2m,超出范围的目标无法感知
- 遮挡恢复:track query 有生命周期管理(2s 容忍期),但长时间遮挡后 ID 仍可能切换
工程实践
训练配置
Backbone: ResNet-50 (S) / ResNet-101 (B) / VoVNetV2-99 (L) |
复现要点
- 两阶段训练至关重要:直接端到端训练不收敛,需先预训练感知模块(Stage 1),再联合训练全任务(Stage 2)。Stage 2 额外冻结 BEV encoder 以节省显存
- Track query 生命周期管理:训练时用 3D IoU > 0.5 过滤配对结果;推理时用分类分数 > 0.4(det)/ > 0.35(track)过滤,2s 容忍期避免短时遮挡中断
- 匹配结果共享:TrackFormer 的匈牙利匹配结果被 MotionFormer 和 OccFormer 复用,保证从历史跟踪到未来预测的身份一致性
- 非线性优化(NLO):训练时对 GT 轨迹做运动学约束(多重射击法),使其在检测位置不精确时仍物理可行;仅训练阶段使用
- 碰撞优化:推理时用 Newton 法在占用图上优化规划轨迹,设定 $\lambda_{\text{coord}}=1.0, \lambda_{\text{obs}}=5.0, d=5, \sigma=1.0$
- 显存管理:OccFormer 在 BEV 1/4 分辨率上做交互,再降至 1/8 做 pixel-agent 注意力
性能优化方向
精度提升:
- 更大 backbone(V2-99)可提升感知精度,进而改善预测和规划(UniAD-L 碰撞率降至 0.29%)
- 更长训练序列(从 3 帧增至 5 帧)有助于时序建模,但显存倍增
速度优化:
- BEVFormer + TrackFormer 占约 70% 计算量,轻量化 BEV encoder 是首选方向
- MotionFormer + OccFormer + Planner 总参数仅约 56M(不含 backbone),计算量可控
研究启示
可迁移的思想
- Query 作为跨任务接口:将不同任务的输出编码为 query,通过注意力机制传递信息,适用于任何多阶段管线(如机器人操控的感知→规划、医学图像的检测→分割→诊断)
- Planning-oriented 任务编排:以最终目标(规划)为导向反向审视前置任务的必要性,而非简单堆叠所有可能的任务
- 双类型预测互补:稀疏(智能体级)+ 稠密(场景级)的预测组合,前者保留身份做交互建模,后者提供全局约束做碰撞避免
- 非线性优化适配端到端:在端到端系统中,上游感知不精确会导致不合理的 GT 轨迹,NLO 通过运动学约束修正 GT 使训练更稳定
方法局限
- 推理速度 1.8 FPS(A100),远未达到实时部署要求
- 依赖 nuScenes 的开环评估,闭环(如 CARLA、nuPlan)性能未验证
- 两阶段训练复杂,且需要大量 GPU 显存(因时序序列+多模块)
- OccFormer 的预测时域(2.5s)远小于 MotionFormer(6s),时域不一致
技术影响
- UniAD 是首个涵盖全栈驾驶任务的端到端框架,获得 CVPR 2023 最佳论文奖,奠定了”planning-oriented”端到端自动驾驶的范式
- 后续 VAD、SparseDrive、GenAD 等方法均以 UniAD 为基线或在其基础上简化/改进
- 证明了端到端训练中各任务的渐进式协调优于独立多任务学习,影响了自动驾驶工业界的系统设计思路
- 开放代码和模型,成为社区广泛使用的端到端自动驾驶基准