Task: 3D Semantic Occupancy Prediction / Semantic Scene Completion
Method: Dual-path Transformer, Mask Classification, Preserve-Pooling
Venue: ICCV
Year: 2023
Paper: https://arxiv.org/abs/2304.05316
Code: https://github.com/zhangyp15/OccFormer
摘要
自动驾驶的视觉感知正从鸟瞰图(BEV)表示向 3D 语义占用预测演进。相比 BEV 平面,3D 语义占用在高度方向上提供了额外的结构信息。本文提出 OccFormer,一种双路径 Transformer 网络,用于高效处理相机生成的 3D 体素特征并进行语义占用预测。编码器方面,OccFormer 将沉重的 3D 处理分解为沿水平面的局部路径(逐 BEV 切片的窗口注意力)和全局路径(BEV 级场景理解),二者通过 sigmoid 加权融合,实现长距离、动态且高效的 3D 特征编码。解码器方面,OccFormer 首次将 Mask2Former 的掩码分类范式适配到 3D 占用预测,提出 preserve-pooling(最大池化替代三线性插值降采样注意力掩码)和 class-guided sampling(按类别频率倒数采样),分别缓解 3D 空间中的稀疏性和类别不平衡问题。在 SemanticKITTI 语义场景补全任务上,OccFormer 以 12.32 mIoU 超越 MonoScene 1.24 个点(相对提升 11%),在所有单目方法中排名第一;在 nuScenes LiDAR 语义分割任务上,以 70.8 mIoU 超越 TPVFormer 1.4 个点。
核心论点:3D 体素特征的高效编码关键在于将 3D 推理分解为 2D——OccFormer 通过双路径(局部逐切片 + 全局 BEV)将 3D 注意力的二次复杂度降至可控范围,结合 Mask2Former 的掩码分类范式,首次实现了基于 Transformer 的端到端 3D 语义占用预测。
问题与动机
3D 语义占用预测旨在以细粒度体素表示重建自车周围的 3D 环境,为自动驾驶提供比 BEV 更完整的场景理解。现有方案存在明显局限:
| 方法类型 | 代表作 | 核心问题 | SSC mIoU(KITTI) |
|---|---|---|---|
| 3D UNet | MonoScene | 3D 卷积感受野固定、参数量大、无法处理稀疏特征 | 11.08 |
| 三平面表示 | TPVFormer | 三平面压缩丢失细粒度语义信息 | 11.26 |
| 3D 卷积 + LiDAR | SSCNet, JS3C-Net | 依赖昂贵 LiDAR,非纯视觉方案 | — |
| BEV 语义分割 | BEVFormer, LSS | 高度方向信息被压缩,无法描述不规则 3D 物体 | — |
3D 卷积的三大局限:
- 感受野固定:不同语义类别分布模式差异大,固定卷积核无法自适应
- 空间不变性:无法很好处理 LSS 等方法产生的稀疏、不连续 3D 特征
- 参数量大:3D 卷积滤波器参数随体素分辨率立方增长
核心痛点:如何设计一种长距离、动态、高效的 3D 特征编码方法,替代传统 3D 卷积,同时处理 3D 占用预测中的稀疏性和类别不平衡问题。
核心洞察
洞察 1:双路径分解——将 3D 推理拆分为 2D 局部+全局
传统做法:直接在 3D 体素上应用 3D 卷积或 3D 注意力,计算量和参数量都随体素数立方增长。
OccFormer 做法:将 3D 特征沿高度维度分解为两条路径并行处理:
- 局部路径:将高度维度合并到 batch 维度,对每个 BEV 切片独立应用共享的窗口自注意力(Swin-like),捕获细粒度语义结构
- 全局路径:沿高度维度平均池化得到 BEV 特征,用窗口注意力 + ASPP(空洞空间金字塔池化)捕获场景级语义布局
融合公式:
$$\mathbf{F}_{\text{out}} = \mathbf{F}_{\text{local}} + \sigma(\mathbf{W} \cdot \mathbf{F}_{\text{local}}) \cdot \text{unsqueeze}(\mathbf{F}_{\text{global}}, -1)$$其中 $\sigma$ 为 sigmoid 函数,$\mathbf{W}$ 为生成沿高度方向聚合权重的 FFN。
为什么更好:双路径编码器比 3D ResNet-16 参数少 39%(81.4M vs. 132.5M),计算量少 38%(515.3 vs. 825.8 GFLOPs),mIoU 反而更高(13.46 vs. 12.89)。局部和全局路径分别贡献了细粒度结构和场景级布局信息,两者互补。
洞察 2:Preserve-Pooling——最大池化保护稀疏 3D 掩码
传统做法(Mask2Former):用双线性插值降采样注意力掩码,在 2D 图像分割中有效,因为 2D 掩码通常连续完整。
OccFormer 做法:将降采样方法替换为最大池化(max-pooling)。在 3D 占用空间中,LiDAR 生成的分割掩码通常是部分的、稀疏的,三线性插值会平滑掉细小结构甚至整个物体。最大池化能保留局部极值,避免稀疏掩码被”冲淡”。
效果:将掩码降采样从三线性改为最大池化,mIoU 提升 0.52(12.13→12.13+0.52),尤其对小型/稀疏类别(如 truck、bicycle)影响显著。
洞察 3:Class-Guided Sampling——按类别频率加权采样
传统做法(Mask2Former):在计算匹配代价和损失时,均匀采样 $K$ 个点。在 2D 图像中可行,但 3D 体素空间中前景区域极为稀疏,均匀采样难以覆盖小类别。
OccFormer 做法:根据训练集中各类别的出现频率 $\mathbf{n}_c$ 计算采样权重 $\mathbf{w}_c = (1/\mathbf{n}_c)^\beta$($\beta = 0.25$),训练时按该权重进行多项式分布采样。
效果:class-guided sampling 带来 +1.33 mIoU 提升(12.13→13.46),其中稀有类别(truck: 7.10→25.53, traffic-sign: 0.00→2.86)提升最为显著。
三个关键数字:
- 12.32 mIoU:SemanticKITTI test 上的 SSC 成绩,单目方法第一
- 70.8 mIoU:nuScenes test LiDAR 分割成绩,纯视觉方法首次超越 70%
- 81.4M:双路径编码器参数量,比 3D ResNet-16(132.5M)少 39%
方法设计
整体架构
OccFormer 的核心流程:
$$\text{多视图图像} \xrightarrow{\text{Image Encoder}} \text{2D 特征} \xrightarrow{\text{LSS}} \text{3D 体素} \xrightarrow{\text{双路径编码器}} \text{多尺度 3D 特征} \xrightarrow{\text{Mask2Former 解码器}} \text{3D 语义占用}$$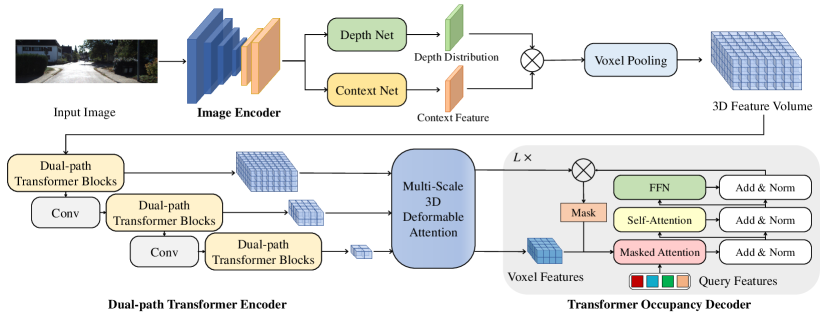
多视图 N cam
│
▼
┌──────────────┐
│ Image Encoder│ EfficientNetB7(KITTI) / ResNet-101(nuScenes)
│ + FPN Neck │ 输出:F_2d ∈ R^{N×C×H×W}
└─────┬────────┘
│
▼
┌─────────────┐
│ LSS │ 深度分布 × 上下文特征 → 体素池化
│ Image→3D │ 输出:F_3d ∈ R^{128×128×16×C}
└─────┬───────┘
│
▼
┌──────────────────────────────┐
│ 双路径 Transformer 编码器 │ 4 stage × 2 blocks
│ ┌────────┐ ┌──────────┐ │
│ │ 局部路径 │ │ 全局路径 │ │ 局部:逐 BEV 切片窗口注意力
│ │(逐切片) │ │(BEV+ASPP)│ │ 全局:BEV 池化 + 窗口注意力 + ASPP
│ └────┬───┘ └────┬─────┘ │
│ └──sigmoid融合──┘ │ 输出:多尺度 3D 特征
└─────┬────────────────────────┘
│
▼
┌───────────────────────┐
│ Mask2Former 占用解码器 │
│ ├─ Pixel Decoder │ 3D 多尺度可变形注意力 → 逐体素嵌入
│ └─ Transformer Dec. │ 掩码注意力 + 自注意力 → 查询→类别+掩码
│ + Preserve-Pooling │ max-pool 替代 trilinear
│ + Class-Guided Samp│ 频率加权采样
└─────┬─────────────────┘
│
▼
3D 语义占用 Y = Σ p_i · M_i
(256×256×32, 21类)
关键组件
| 模块 | 输入 | 输出 | 核心设计 |
|---|---|---|---|
| Image Encoder | $N$ 视图 RGB | $\mathbf{F}_{2d} \in \mathbb{R}^{N \times C \times H \times W}$ | Backbone + FPN Neck,1/16 分辨率 |
| Image-to-3D | $\mathbf{F}_{2d}$ | $\mathbf{F}_{3d} \in \mathbb{R}^{128 \times 128 \times 16 \times C}$ | LSS 深度分布 + 体素池化 |
| 双路径编码器 | $\mathbf{F}_{3d}$ | 多尺度 3D 特征 | 局部窗口注意力 + 全局 BEV+ASPP |
| Pixel Decoder | 多尺度 3D 特征 | 逐体素嵌入 $\mathcal{E}_{\text{voxel}}$ | 6 层 3D 多尺度可变形注意力 |
| Transformer Decoder | 查询 $\mathbf{Q}$ + 3D 特征 | 类别 $\mathbf{p}_i$ + 掩码 $\mathbf{M}_i$ | 掩码注意力 + 自注意力 + FFN |
损失函数:
$$\mathcal{L} = \mathcal{L}_{\text{mask-cls}} + \mathcal{L}_{\text{depth}}$$- 掩码分类损失 $\mathcal{L}_{\text{mask-cls}}$:匈牙利匹配后的分类 + 二值掩码损失(CE + Dice),仅在 class-guided 采样点上计算
- 深度损失 $\mathcal{L}_{\text{depth}}$:LiDAR 点云投影的 GT 深度图,BCE 损失监督深度分布(类似 BEVDepth)
最终 3D 语义占用预测:
$$\mathbf{Y} = \sum_{i=1}^{N_q} \mathbf{p}_i \cdot \mathbf{M}_i$$ 其中 $N_q$ 为查询数,$\mathbf{p}_i$ 为类别 logits,$\mathbf{M}_i = \sigma(\mathcal{E}_{\text{mask}}^i \cdot \mathcal{E}_{\text{voxel}})$ 为二值 3D 掩码。关键代码
双路径融合的核心逻辑(局部 + 全局路径的 sigmoid 加权):
(来源:projects/)
# 局部路径:将高度合入 batch,对每个 BEV 切片独立做窗口注意力 |
Preserve-Pooling 替代三线性插值降采样注意力掩码:
(来源:projects/)
# Mask2Former 原版:trilinear 降采样 |
实验与分析
主要结果
SemanticKITTI test(语义场景补全)
| 方法 | 输入 | SC IoU | SSC mIoU |
|---|---|---|---|
| LMSCNet* | Camera | 31.38 | 7.07 |
| AICNet* | Camera | 23.93 | 7.09 |
| JS3C-Net* | Camera | 34.00 | 8.97 |
| MonoScene | Camera | 34.16 | 11.08 |
| TPVFormer | Camera | 34.25 | 11.26 |
| OccFormer | Camera | 34.53 | 12.32 |
nuScenes test(LiDAR 语义分割)
| 方法 | 输入 | mIoU |
|---|---|---|
| TPVFormer | Camera | 69.4 |
| OccFormer | Camera | 70.8 |
| PolarStream | LiDAR | 73.4 |
| Cylinder3D++ | LiDAR | 77.9 |
关键发现:
- OccFormer 在 SemanticKITTI SSC 上比 MonoScene 高 +1.24 mIoU(相对提升 11%),单目方法第一
- 在 nuScenes 上首次以纯视觉方法达到 70%+ mIoU 的 LiDAR 分割精度,接近部分 LiDAR 方法水平
- 仅需一个模型同时完成 LiDAR 分割和语义占用预测,而 TPVFormer 需要分别训练两个模型
消融实验:验证三个洞察
双路径编码器消融(洞察 1)
| 配置 | 参数量 | GFLOPs | SC IoU | SSC mIoU | 验证洞察 |
|---|---|---|---|---|---|
| 仅局部路径 | 74.1M | 494.2 | 36.42 | 12.95 | 洞察 1 |
| 仅全局路径 | 81.4M | 407.4 | 36.37 | 12.93 | 洞察 1 |
| 双路径(完整) | 81.4M | 515.3 | 36.50 | 13.46 | 洞察 1 |
| 3D ResNet-16 | 132.5M | 825.8 | 36.12 | 12.89 | 洞察 1 |
| 3D Swin-T | 82.3M | 437.9 | 36.32 | 12.80 | 洞察 1 |
解码器消融(洞察 2+3)
| 掩码降采样 | 采样方法 | SC IoU | SSC mIoU | 验证洞察 |
|---|---|---|---|---|
| Tri-linear | Uniform | 35.04 | 11.61 | 基线 |
| Max-pool | Uniform | 35.41 | 12.13 | 洞察 2 |
| Tri-linear | Class-guided | 36.21 | 13.01 | 洞察 3 |
| Max-pool | Class-guided | 36.50 | 13.46 | 洞察 2+3 |
性能瓶颈分析
OccFormer 的主要计算瓶颈在于 3D 体素特征的分辨率:
- 体素分辨率为 $128 \times 128 \times 16$,经编码器 4 个 stage 后下采样
- Pixel Decoder 使用 6 层 3D 多尺度可变形注意力(4.07M 参数,379.2 GFLOPs),是解码器中最重的模块
- 最终预测需 2× 上采样至 $256 \times 256 \times 32$ 进行评估
失效场景分析
- 不可见区域:FOV 外的区域(如单目相机背后)依赖全局路径的 hallucination 能力,准确性有限
- 极稀疏类别:motorcyclist(0.05% 占比)即使使用 class-guided sampling 仍为 0.0 mIoU,训练样本过少
- 高度方向细节:双路径主要在水平面上推理,纯沿高度方向的细粒度结构(如电线杆上下分段)建模能力有限
- 远距离区域:单目深度估计误差随距离增大,远处体素特征质量下降
工程实践
训练配置
Backbone: EfficientNetB7 (KITTI) / ResNet-101-DCN (nuScenes) |
复现要点
- 3D 数据增强至关重要:去掉 3D flip 增强后模型在第 9 epoch 即过拟合(总训练 30 epoch),Transformer 的强容量需要充分正则化
- Pixel Decoder 层数:3 层 MsDeformAttn3D 比 6 层低 0.24 mIoU,6 层是精度饱和点
- Class-guided 采样的 β 值:$\beta = 0.25$ 控制类别权重的”尖锐度”,过大(如 1.0)会过度关注稀有类导致大类崩溃
- Preserve-pooling 只需改一行:将
F.interpolate(mode='trilinear')改为F.max_pool3d,但在 3D 稀疏场景中效果显著 - nuScenes 的稀疏监督:仅用 LiDAR 点做监督(非密集体素标注),采样时 LiDAR 点和随机坐标按 1:1 混合
性能优化方向
精度提升:
- 引入时序信息聚合多帧体素特征,减少单帧遮挡和深度估计噪声
- 使用更大 backbone(R101-DCN 比 R50 在 nuScenes 上高约 2 mIoU),代价是推理速度下降
速度优化:
- 降低体素分辨率(如 $64 \times 64 \times 8$)可大幅减少计算量,但会损失细粒度结构
- 双路径编码器已比 3D 卷积高效,进一步优化可考虑减少编码器 stage 数或 block 数
研究启示
可迁移的思想
- 3D 处理的 2D 分解策略:将 3D 注意力拆分为水平面 2D 推理 + 高度维度聚合,适用于任何需要高效处理大规模 3D 特征的任务(如 3D 医学图像分割、室内场景理解)
- Mask2Former 的 3D 适配:掩码分类范式从 2D 迁移到 3D 时,关键在于处理稀疏性(preserve-pooling)和类别不平衡(class-guided sampling)
- 频率倒数加权采样:对任何存在严重类别不平衡的稀疏预测任务(如点云分割、稀疏目标检测),按类别频率加权采样比均匀采样更有效
- sigmoid 加权融合:用可学习的 sigmoid 权重融合多路径特征,让网络自适应决定不同高度位置的全局/局部信息配比
方法局限
- 依赖 LSS 的深度估计质量,深度误差会直接传导到 3D 体素特征
- 双路径仅在水平面推理,对纯高度方向的细粒度语义区分能力有限
- 训练需要 LiDAR 点云或密集体素标注作为监督,纯图像自监督尚未探索
技术影响
- OccFormer 是首个将 Mask2Former 适配到 3D 占用预测的工作,为后续 Occ3D、SurroundOcc 等工作提供了解码器设计参考
- 双路径分解思路证明了 3D Transformer 处理不必采用昂贵的全 3D 注意力,影响了后续 3D 占用/场景补全方法的网络设计
- 在 nuScenes 上首次以纯视觉达到 70%+ LiDAR 分割 mIoU,证明了基于相机的 3D 占用表示可以逼近 LiDAR 精度
- 推动了自动驾驶感知从”BEV 2D 平面”到”3D 体素占用”的范式转变