Task: Online Vectorized HD Map Construction
Method: Permutation-Equivalent Modeling, Hierarchical Query, Hierarchical Bipartite Matching
Venue: ICLR Spotlight
Year: 2023
Paper: https://arxiv.org/abs/2208.14437
Code: https://github.com/hustvl/MapTR
1. 摘要
MapTR(Map TRansformer)提出了一个结构化、端到端的 Transformer 框架,用于高效的在线矢量化高精地图构建。HDMapNet 走”BEV 分割 + 后处理”路线,VectorMapNet 走”DETR + 自回归 polyline 生成”两阶段路线,二者各有瓶颈:前者依赖 DBSCAN 启发式向量化,后者推理只能逐点串行(2.9 FPS)。MapTR 的核心创新是置换等价建模(Permutation-Equivalent Modeling)——把每个地图元素建模为带有一组等价置换的点集,精确描述几何形状的同时消除点序歧义;配合分层查询(实例查询 + 点查询的加性组合)与分层二部匹配(先匹配实例、再从置换组中选最优点序),首次实现了”一次前向并行预测 polyline”,把推理速度从 VectorMapNet 的 2.9 FPS 抬到 25.1 FPS(+8×)。MapTR-tiny 在 nuScenes 24-epoch 训练即达 50.3 mAP,比当时多模态最优方法高 13.5 mAP;MapTR-nano 在 RTX 3090 上达到实时(25.1 FPS)。
核心论点:矢量化高精地图构建的关键瓶颈是”形状歧义”——多线/多边形的同一几何形状对应多种等价点序,固定一种作为监督会与其他等价排列产生矛盾。把固定序换成”置换组 + 最优匹配”,配合分层查询与分层匹配,可以同时拿下精度(+5.9 mAP)和速度(+8× FPS)。
2. 问题与动机
| 方法类型 | 代表作 | 核心问题 | mAP / FPS |
|---|---|---|---|
| BEV 语义分割 | HDMapNet | 栅格化 + DBSCAN 启发式向量化,缺乏实例级矢量信息 | 23.0 / 0.8 |
| 自回归序列预测 | VectorMapNet | 逐点串行推理(2.9 FPS)、点序歧义未解决 | 40.9 / 2.9 |
| 前视图车道检测 | PersFormer / LSTR | 仅单视图、单类型元素,无法处理全景多类地图 | – |
| SLAM 离线建图 | LOAM / LIO-SAM | 流程复杂、维护成本高、自车定位误差敏感 | – |
核心痛点:地图元素(车道线、人行横道、道路边界)具有动态形状,无法像目标检测那样用 bbox 简单抽象;同一形状存在多种等价点序排列,将其中一种作为监督信号会带来梯度矛盾;现有方法要么慢(VectorMapNet 自回归),要么需要大量后处理(HDMapNet 启发式聚类)。
3. 核心洞察
洞察 1:置换等价建模——消除形状表示的点序歧义
传统做法:把地图元素表示为固定顺序的有序点列 $V_F = [v_0, v_1, \ldots, v_{N_v-1}]$,隐含规定了唯一的遍历方向和起点。
MapTR 做法:把每个地图元素建模为 $\mathcal{V} = (V, \Gamma)$,其中 $V$ 是点集、$\Gamma$ 是一组等价置换(覆盖所有产生相同几何形状的排列方式)。
对于多线(polyline,如车道线,2 个端点都可作为起点):
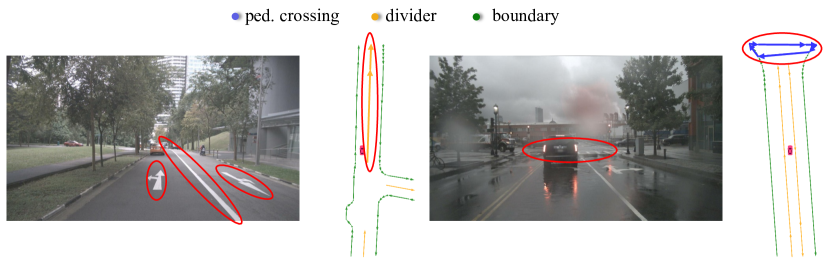
$$\Gamma_{\text{polyline}} = \{\gamma_0, \gamma_1\}, \quad \gamma_0(j) = j \bmod N_v, \quad \gamma_1(j) = (N_v - 1 - j) \bmod N_v$$对于多边形(polygon,如人行横道,任意顶点起、顺/逆时针 2 个方向,共 $2N_v$ 种等价排列):
$$\Gamma_{\text{polygon}} = \{\gamma_0, \gamma_1, \ldots, \gamma_{2N_v - 1}\}$$为什么更好:固定序标签在 nuScenes 上仅 44.4 mAP,引入置换等价建模后提升至 50.3 mAP(+5.9 mAP),其中人行横道提升最大(+11.9 AP)——polygon 的等价置换数最多($2 \times 20 = 40$ 种),消除歧义带来的收益最显著。
洞察 2:分层查询——结构化编码地图元素
传统做法(DETR 式):每个 query 对应一个实例的整体信息,难以编码”实例 + 多个内部点”的两层结构。
MapTR 做法:分别定义 $N$ 个实例级查询 $\{q_i^{\text{ins}}\}$ 和 $N_v$ 个点级查询 $\{q_j^{\text{pt}}\}$(所有实例共享),通过加法组合得到每个点的分层查询:
$$q_{ij}^{\text{hie}} = q_i^{\text{ins}} + q_j^{\text{pt}}$$总查询数为 $N \times N_v$(如 50 × 20 = 1000),但参数量只是 $N + N_v$(70)。这种”实例 × 部件”的因子分解让每个点 query 自适应地分布在实例的不同位置,天然适配不规则形状,又避免了组合爆炸。
洞察 3:分层二部匹配——把”哪个实例”和”哪个点序”解耦
匹配也分两层:
Step 1:实例级匈牙利匹配——找到预测实例 → GT 实例的最优全局对应 $\hat{\pi}$;
Step 2:点级匹配——对每个正样本实例,从置换组 $\Gamma$ 中选出 Manhattan 距离最小的点序 $\hat{\gamma}$:
$$\hat{\gamma} = \arg\min_{\gamma \in \Gamma} \sum_{j=0}^{N_v - 1} D_{\text{Manhattan}}(\hat{v}_j, v_{\gamma(j)})$$为什么更好:把”哪个实例”和”哪个点序”两个组合优化解耦——前者是经典 DETR 的全局二部匹配,后者只在置换组里枚举(多线 2 种、多边形 $2N_v$ 种),二者都可以在 GPU 上高效求解,避免了联合优化的指数爆炸。
三个洞察的递进关系
- 表示:用置换组消除几何形状的点序歧义;
- 查询:分层查询把实例 × 部件因子分解;
- 匹配:分层匹配让”实例对应”和”点序对齐”解耦求解。
三个关键数字:
- 50.3 mAP(24 ep, R50, tiny)vs 固定序 44.4 mAP:置换等价建模带来的纯增益 +5.9 mAP;
- 25.1 FPS(nano, R18)vs VectorMapNet 2.9 FPS:实时矢量化建图的奠基速度,+8×;
- +11.9 AP on ped_crossing:消歧收益与等价置换数正相关的最强证据(polygon 的 $2N_v$ 远多于 polyline 的 2)。
4. 方法设计
4.1 整体架构
$$\text{6 cams} \xrightarrow{\text{Backbone}} \text{PV feat} \xrightarrow{\text{PV2BEV (GKT)}} \text{BEV feat} \xrightarrow{\text{Map Decoder}} {(\text{class}, \text{polyline}_{N_v\times 2})}$$
PV(Perspective View)特征:Backbone 在相机原始透视视角下提取的 2D 特征,保留了相机投影空间关系。PV2BEV 模块(MapTR 默认 GKT,也兼容 BEVFormer 的可变形注意力)负责把 PV 特征投影到 BEV 平面坐标系。
ASCII 架构图:
6 cam (1600×900)
│
▼
┌──────────────┐
│ Backbone │ ResNet-18 / ResNet-50
│ (PV feat) │ 输出: 6 × C × H × W
└──────┬───────┘
│
▼
┌──────────────┐
│ PV → BEV │ GKT (Geometry Kernel Transformer)
│ Transform │ 输出: BEV 特征 H_bev × W_bev × C
└──────┬───────┘
│ ┌────────────────────────┐
▼ │ 分层查询嵌入 │
┌──────────────┐ │ q_ij = q_i^ins │
│ Map Decoder │ ◄─── │ + q_j^pt │
│ (6 层) │ │ N=50 实例, Nv=20 点 │
└──────┬───────┘ └────────────────────────┘
│
├──► 分类头 ─→ 实例类别分数
│
└──► 回归头 ─→ 点集坐标 (N × Nv × 2)
4.2 关键组件
| 模块 | 选型 | 作用 |
|---|---|---|
| Backbone | ResNet-18 (nano) / ResNet-50 (tiny) | PV 图像特征提取 |
| PV2BEV | GKT(默认)/ Deformable Attn | 2D → BEV 特征变换 |
| Map Decoder | 6 层 Transformer | 分层查询解码 |
| Self-Attn | 全局 self-attention($N \cdot N_v$ tokens) | 查询间交互 |
| Cross-Attn | BEV-based Deformable Attention | 查询与 BEV 特征交互 |
| 匹配 | 分层匈牙利 + 置换组枚举 | 标签分配 |
| 分类头 | 同实例 $N_v$ 个点特征取均值 → FC | 实例类别 |
| 回归头 | 每个点 query 独立预测 (x, y) 残差 | 点集坐标 |
损失函数:
$$\mathcal{L} = \lambda_c \mathcal{L}_{\text{cls}} + \lambda_p \mathcal{L}_{\text{p2p}} + \lambda_d \mathcal{L}_{\text{dir}}, \qquad \lambda_c = 2,\ \lambda_p = 5,\ \lambda_d = 5\times 10^{-3}$$- 分类损失 $\mathcal{L}_{\text{cls}}$:Focal Loss;
- Point-to-Point 损失:在最优置换 $\hat{\gamma}$ 下逐点 Manhattan 距离
- 边方向损失:相邻点构成的边的余弦相似度
4.3 关键代码
分层查询通过实例嵌入 + 点级嵌入相加构成:
# 来源:projects/mmdet3d_plugin/maptr/dense_heads/maptr_head.py |
分类头对同一实例的 $N_v$ 个点特征取均值,回归头每个 query 独立预测 2D 坐标残差:
# 同一实例的 Nv 个点特征取均值 → 实例类别 |
📄 点击展开:置换等价匹配(最优点序选择)核心代码
匹配阶段,对每个 GT 实例预先生成所有等价置换的点序 gt_shifts_pts,assigner 返回的 order_index 指向当前预测下的最优置换:
# 在 _get_target_single 中 |
5. 实验与分析
5.1 主要结果
nuScenes val(论文 Tab. 1,AP 阈值 {0.5, 1.0, 1.5} m):
| 方法 | 模态 | Backbone | Epoch | AP_ped | AP_div | AP_bou | mAP | FPS |
|---|---|---|---|---|---|---|---|---|
| HDMapNet | C | Effi-B0 | 30 | 14.4 | 21.7 | 33.0 | 23.0 | 0.8 |
| VectorMapNet | C | R50 | 110 | 36.1 | 47.3 | 39.3 | 40.9 | 2.9 |
| VectorMapNet | C+L | R50+PP | 110 | 37.6 | 50.5 | 47.5 | 45.2 | – |
| MapTR-nano | C | R18 | 110 | 39.6 | 49.9 | 48.2 | 45.9 | 25.1 |
| MapTR-tiny | C | R50 | 24 | 46.3 | 51.5 | 53.1 | 50.3 | 11.2 |
| MapTR-tiny | C | R50 | 110 | 56.2 | 59.8 | 60.1 | 58.7 | 15.1 |
关键发现:
- MapTR-nano 首次实现实时矢量化建图(25.1 FPS),比 VectorMapNet 快 8× 且 mAP 高 5.0;
- MapTR-tiny 24-ep 即超过 VectorMapNet 110-ep 多模态成绩(50.3 vs 45.2 mAP),仅靠纯视觉 + 端到端范式;
- 110-ep 时三类元素全面超过 60 AP,证明并行 polyline 预测在精度上完全不输自回归生成。
5.2 消融实验:验证三个洞察
| 配置 | 关键现象 | 验证洞察 |
|---|---|---|
| 固定序 vs 置换等价 | 44.4 → 50.3 mAP(+5.9) | 洞察 1 |
| ped_crossing(polygon)增益 | +11.9 AP(vs polyline 仅 +3.4 AP) | 洞察 1(置换数越多收益越大) |
| 分层查询 vs 单层查询 | 分层显著优于把所有点拼成一个长 query | 洞察 2 |
| 分层匹配 vs 联合匹配 | 解耦显著降低匹配求解时间,且收敛更稳 | 洞察 3 |
| Decoder 层数:6 → 2 | nano 用 2 层换速度,精度下降约 8 mAP | 工程权衡 |
| BEV 网格:0.3 m / 0.75 m | tiny 0.3 m / nano 0.75 m,精度 vs 速度 | 工程权衡 |
5.3 性能瓶颈分析
MapTR-tiny 推理时间分布(RTX 3090):
| 组件 | 耗时 (ms) | 占比 |
|---|---|---|
| Backbone | 55.5 | 62.1% |
| PV2BEV (GKT) | 12.3 | 13.8% |
| Map Decoder | 21.5 | 24.1% |
| 总计 | 89.3 | 100% |
Backbone 占 60%,是主要瓶颈;Map Decoder(含 6 层 Transformer 与置换匹配)仅 24%,说明分层查询机制本身计算开销可控。
5.4 失效场景分析
- 远距离地图元素:感知范围 $[-15, 15],\text{m} \times [-30, 30],\text{m}$,远端 BEV 分辨率低,细节丢失;
- 严重遮挡场景:多车拥堵或施工区路面标线被大量遮挡,BEV 特征缺失;
- 相机外参偏差:平移噪声 $\sigma > 0.5,\text{m}$ 或旋转 $\sigma > 0.02,\text{rad}$ 时 mAP 显著下降(50.3 → 34.0);
- 夜间 / 雨天:定性结果稳定但碎片化预测增多。
6. 工程实践
6.1 训练配置
Backbone: ResNet-18 (nano) / ResNet-50 (tiny) |
6.2 复现要点
- 置换等价 GT 预生成:每个 GT 元素需生成所有等价置换的点集(
shift_fixed_num_sampled_points);多线 2 种、多边形 $2N_v$ 种;polygon 的循环移位 + 方向翻转的组合顺序要严格一致; - BEV 网格大小:nano 0.75 m / tiny 0.3 m,感知范围与分辨率必须同步配置匹配损失计算;
- 边方向损失权重 $\lambda_d = 5 \times 10^{-3}$ 是精心调优的结果,过大($10^{-2}$)反而降低 ~2 mAP——点级损失尚未收敛时强制约束边方向会引入矛盾梯度;
- PV2BEV 选择 GKT:相比 LSS 或 BEVFormer 的 deformable attention,GKT 在精度 / 速度 / 部署友好度上较平衡;
- 分类头取均值:同实例 $N_v$ 个点特征 mean-pool 后再分类,避免每个点都打分带来的不一致。
6.3 性能优化方向
精度提升
- 引入时序信息(多帧 BEV 聚合可加 1–3 mAP);
- 替换更强 backbone(V2-99 / SwinT),代价是速度下降;
- 加入辅助密集监督(深度 / PV 分割 / BEV 分割)——这正是 MapTRv2 的核心改进。
速度优化
- Backbone 是首要瓶颈,可换 EfficientNet-B0 或蒸馏小模型;
- 减少 Decoder 层数(6 → 2,nano 即采用此策略,精度 −8 mAP / 速度 +2×);
- 降低 BEV 分辨率到 0.75 m(nano 路线)。
7. 研究启示
7.1 可迁移的思想
- 置换等价建模处理几何歧义:任何涉及有序点集表示的任务(轮廓 / 路径 / 骨架)都会面临点序模糊问题,MapTR 的”置换组 + 最优匹配选择”是通用模板;
- 分层查询分解实例-部件关系:实例 × 部件的因子化查询设计,参数量从 $N \cdot N_v$ 降到 $N + N_v$,可推广至人体姿态关节点、场景图节点-关系等任务;
- 分层匹配解耦组合优化:先实例匹配再部件匹配的 two-step 策略,是处理”集合的集合”类问题的工程化标配;
- DETR-style 端到端 + 一次性并行预测:彻底取代”自回归生成形状”的范式,是 VectorMapNet → MapTR 这次跃迁的本质。
7.2 方法局限
- 单帧推理,缺乏时序一致性保证;
- 感知范围受限于 BEV 网格($60 \times 30,\text{m}$),无法处理远距离 HD 地图;
- 不支持动态地图元素(临时施工标线、可变车道);
- 收敛仍偏慢(24 ep 50.3 → 110 ep 58.7),稀疏 query 范式天然正样本不足——这是 MapTRv2 用一对多匹配 + 密集监督要解决的问题。
7.3 技术影响
- 开创了在线矢量化建图的 DETR-like 范式,BeMapNet、MachMap、PolyDiffuse、MapVR 等后续工作均以 MapTR 为基线;
- 首次让在线高精地图构建具备上车部署可行性(25+ FPS 实时);
- 置换等价建模直接被多个后续工作沿用(PivotNet、MapNeXt 等);
- VAD / SparseDrive 等端到端规划工作直接消费 MapTR 的矢量化输出,打通了感知 → 规划的数据闭环;
- 直接催生 MapTRv2,从精度(73.4 mAP)和功能(centerline / 3D)两个维度做全面增强。