Task: End-to-End Autonomous Driving (Multi-Mode Planning)
Method: Truncated Diffusion Policy, Cascade Diffusion Decoder
Venue: CVPR 2025 Highlight
Year: 2025
Paper: https://arxiv.org/abs/2411.15139
Code: https://github.com/hustvl/DiffusionDrive
摘要
扩散模型(Diffusion Model)因其强大的多模态分布建模能力,在机器人策略学习中展现了巨大潜力。然而,将其直接应用于端到端自动驾驶面临两大挑战:去噪步数过多(20 步,仅 7 FPS)和模式坍塌(不同随机噪声收敛至相似轨迹,多样性仅 11%)。本文提出 DiffusionDrive,核心创新是截断扩散策略(Truncated Diffusion Policy)——将扩散起点从随机高斯噪声替换为围绕 K-Means 聚类锚点的锚定高斯分布,仅需 2 步去噪(10× 加速)即可生成高质量多模态轨迹(多样性 74%)。配合高效的级联扩散解码器(Cascade Diffusion Decoder),DiffusionDrive 在 NAVSIM navtest 上达到 88.1 PDMS,以 45 FPS 实时运行于 4090 GPU。
核心论点:端到端自动驾驶规划本质上是多模态问题——扩散模型天然适合建模多种合理驾驶行为,但需要截断扩散调度以利用驾驶先验(锚点轨迹),将去噪步数从 20 降至 2,同时用 Transformer 级联解码器替代 UNet 以增强场景交互。
问题与动机
现有端到端规划方法在多模态建模上的探索可分为三类,各有局限:
| 范式 | 代表方法 | 局限 |
|---|---|---|
| 单模态回归 | UniAD, VAD, Transfuser | 无法表达多种合理行为(如直行 or 变道) |
| 固定词汇表采样 | VADv2 (4096), Hydra-MDP (8192) | 受限于锚点数量和质量,OOV 场景失败 |
| 标准扩散策略 | TransfuserDP (20 steps) | 20 步去噪拖慢至 7 FPS + 模式坍塌 |
DiffusionDrive 的洞察来源于人类驾驶行为的规律性:人类并非从”随机噪声”中做决策,而是在有限的驾驶模式中根据实时路况动态调整。因此可以:
- 用 K-Means 聚类提取少量驾驶模式锚点(仅 20 个)
- 在锚点附近加小噪声,而非从纯高斯噪声出发
- 截断扩散调度,大幅减少去噪步数
核心洞察
洞察 1:截断扩散——用驾驶先验替代随机噪声
传统做法(Diffusion Policy):从纯高斯噪声 $\tau^T \sim \mathcal{N}(0, \mathbf{I})$ 出发,经 20 步 DDIM 去噪生成轨迹。每步都需运行完整的 UNet 前向传播。
DiffusionDrive 做法:
- 从训练集用 K-Means 聚类 20 条锚点轨迹 $\{\mathbf{a}_k\}_{k=1}^{20}$
- 训练时截断扩散调度($T_{\text{trunc}}=50$,而非 $T=1000$),仅在锚点上加少量噪声:$\tau_k^i = \sqrt{\bar{\alpha}_i} \mathbf{a}_k + \sqrt{1-\bar{\alpha}_i} \epsilon$
- 推理时从锚定高斯分布采样,仅需 2 步去噪
为什么更好:Tab. 2 的 Roadmap 清晰展示了收益:
- TransfuserDP(标准扩散):84.6 PDMS,20 步,7 FPS,多样性 11%
- TransfuserTD(截断扩散):85.7 PDMS,2 步,27 FPS,多样性 70%
- DiffusionDrive(+级联解码器):88.1 PDMS,2 步,45 FPS,多样性 74%
截断扩散通过合理的起点大幅压缩了去噪路径——不需要从纯噪声”摸索”到合理轨迹,而是从”接近答案的位置”微调。
洞察 2:级联 Transformer 解码器——替代笨重的 UNet
传统做法:机器人扩散策略统一使用 UNet 作为去噪网络,参数量大(102M)、每步耗时长(6.5ms)。
DiffusionDrive 做法:设计轻量级 Transformer 扩散解码器,包含四个关键交互:
- 可变形空间交叉注意力:用轨迹坐标从 BEV/PV 特征中提取局部场景信息
- Agent/Map 交叉注意力:利用感知模块的结构化查询(检测框、地图元素)
- 时间步调制层:编码当前去噪步数信息
- 级联机制:堆叠 2 层解码器,在每个去噪步内迭代精炼轨迹
为什么更好:消融实验(Tab. 3)显示:
- 仅用 Ego Query(无空间/Agent 交互):PDMS 暴跌至 55.1(ID-2)
- 加入空间交叉注意力:PDMS 跃升至 87.1(ID-3,+32.0)
- 再加 Agent 交叉注意力:87.4(ID-5)
- 再加级联机制:88.1(ID-6)
- 参数量从 UNet 的 102M 降至 60M(-39%),每步耗时从 6.5ms 降至 3.8ms
洞察 3:锚点实现真正的多模态——20 个锚点 > 8192 个
传统做法(VADv2/Hydra-MDP):用 4096~8192 个固定锚点离散化动作空间,按分数采样。锚点越多越好?实际上 VADv2 仅达 80.9 PDMS。
DiffusionDrive 做法:仅用 20 个 K-Means 锚点作为扩散起点。扩散模型的连续生成能力允许每个锚点”演化”出一族连续轨迹,而非固定在离散位置。推理时可灵活采样 $N_{\text{infer}}$ 条轨迹(默认 20,可动态调整到 40+)。
为什么更好:
- DiffusionDrive(20 锚点)88.1 PDMS > Hydra-MDP(8192 锚点)83.0 PDMS
- 模式多样性 74% 远超标准扩散的 11%
- 定性可视化显示 top-10 轨迹涵盖直行、变道等多种合理行为
三个关键数字:
- 88.1 PDMS:NAVSIM navtest 新 SOTA,超越 Hydra-MDP-W-EP 1.6 分
- 2 步去噪:比标准扩散策略加速 10×,比 Transfuser MLP 仅慢 38×(7.6ms vs 0.2ms)
- 45 FPS:4090 满足实时要求,标准扩散策略仅 7 FPS
方法设计
整体架构
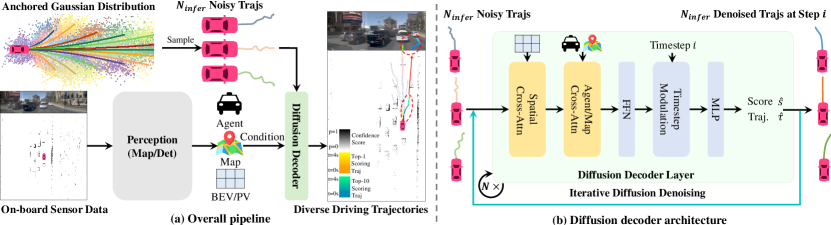
传感器输入 (Camera + LiDAR)
│
▼
┌────────────────────────┐
│ 感知编码器(可替换) │
│ • NAVSIM: Transfuser │
│ • nuScenes: SparseDrive│
└─────┬────────┬─────────┘
│ │
BEV/PV Agent/Map
Feature Queries
│ │
▼ ▼
┌──────────────────────────────────────────────┐
│ 截断扩散策略 │
│ │
│ K-Means 锚点 {a_k} ──加少量噪声──→ τ_k^i │
│ (20 条) T_trunc=50 │
│ │
│ ┌─────────── 级联扩散解码器 ────────────┐ │
│ │ Layer 1: │ │
│ │ Deformable Spatial Cross-Attn │ │
│ │ → Agent/Map Cross-Attn │ │
│ │ → FFN → Timestep Modulation │ │
│ │ → MLP (score + offset) │ │
│ ├─────────────────────────────────────┤ │
│ │ Layer 2 (cascade): │ │
│ │ 同上结构,输入为 Layer1 输出 │ │
│ └─────────────────────────────────────┘ │
│ │
│ 重复 2 个 DDIM 去噪步(共享参数) │
│ → 输出 {s_k, τ_k} → Top-1 scoring 轨迹 │
└──────────────────────────────────────────────┘
关键组件
| 模块 | 输入 | 输出 | 核心设计 |
|---|---|---|---|
| 感知编码器 | 多视图图像 + LiDAR | BEV/PV 特征 + Agent/Map 查询 | 可替换(Transfuser / SparseDrive) |
| 锚点初始化 | 训练集全部 GT 轨迹 | 20 条聚类锚点$\{\mathbf{a}_k\}$ | K-Means 聚类 + 截断噪声调度 |
| 级联扩散解码器 | 含噪轨迹 + 场景特征 | 分数 + 去噪轨迹 | 可变形注意力 + Agent 交互 + 级联精炼 |
| DDIM 去噪 | 解码器输出 | 下一步输入 | 2 步,参数共享 |
损失函数:
$$\mathcal{L} = \sum_{k=1}^{N_{\text{anchor}}} \left[ y_k \mathcal{L}_{\text{rec}}(\hat{\tau}_k, \tau_{\text{gt}}) + \lambda \cdot \text{BCE}(\hat{s}_k, y_k) \right]$$正样本分配:距离 GT 最近的锚点为正($y_k=1$),其余为负。$\mathcal{L}_{\text{rec}}$ 为 L1 重建损失。
截断扩散的数学原理
标准扩散前向过程:$q(\tau^i | \tau^0) = \mathcal{N}(\tau^i; \sqrt{\bar{\alpha}_i} \tau^0, (1-\bar{\alpha}_i)\mathbf{I})$
截断后:仅扩散 $i \in [1, T_{\text{trunc}}]$,其中 $T_{\text{trunc}} = 50 \ll T = 1000$。这意味着噪声量级极小——锚点基本保持原始形状,仅添加微小扰动。模型只需学习”从接近正确的位置微调到精确位置”,而非”从纯噪声中重建”。
实验与分析
主要结果
NAVSIM navtest 闭环评估(Table 1)
| 方法 | 输入 | 锚点数 | NC↑ | DAC↑ | TTC↑ | Comf.↑ | EP↑ | PDMS↑ |
|---|---|---|---|---|---|---|---|---|
| Transfuser | C&L | 0 | 97.7 | 92.8 | 92.8 | 100 | 79.2 | 84.0 |
| VADv2 | C&L | 8192 | 97.2 | 89.1 | 91.6 | 100 | 76.0 | 80.9 |
| Hydra-MDP | C&L | 8192 | 97.9 | 91.7 | 92.9 | 100 | 77.6 | 83.0 |
| Hydra-MDP-W-EP | C&L | 8192 | 98.3 | 96.0 | 94.6 | 100 | 78.7 | 86.5 |
| DiffusionDrive | C&L | 20 | 98.2 | 96.2 | 94.7 | 100 | 82.2 | 88.1 |
DiffusionDrive 用 20 个锚点(400× 少于 VADv2)达到最优 PDMS,且无需后处理。
nuScenes 开环规划(Table 7)
| 方法 | Backbone | L2 1s↓ | L2 2s↓ | L2 3s↓ | avg L2↓ | Col 1s↓ | Col 2s↓ | Col 3s↓ | avg Col↓ | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| VAD | R50 | 0.41 | 0.70 | 1.05 | 0.72 | 0.07 | 0.17 | 0.41 | 0.22 | 4.5 |
| SparseDrive | R50 | 0.29 | 0.58 | 0.96 | 0.61 | 0.01 | 0.05 | 0.18 | 0.08 | 9.0 |
| DiffusionDrive | R50 | 0.27 | 0.54 | 0.90 | 0.57 | 0.03 | 0.05 | 0.16 | 0.08 | 8.2 |
在 SparseDrive 基础上集成 DiffusionDrive 的截断扩散规划头,avg L2 从 0.61 降至 0.57(-6.6%),碰撞率持平。
效率对比(Table 2 Roadmap)
| 方法 | 去噪网络 | 步时间 | 步数 | 总耗时 | 多样性 D↑ | 参数 | FPS |
|---|---|---|---|---|---|---|---|
| Transfuser | MLP | 0.2ms | 1 | 0.2ms | 0% | 56M | 60 |
| TransfuserDP | UNet | 6.5ms | 20 | 130.0ms | 11% | 101M | 7 |
| TransfuserTD | UNet | 6.9ms | 2 | 13.8ms | 70% | 102M | 27 |
| DiffusionDrive | Dec. | 3.8ms | 2 | 7.6ms | 74% | 60M | 45 |
消融实验
解码器设计消融(Table 3)
| ID | UNet | 空间交叉注意力 | Agent 交叉注意力 | 级联 | 参数 | PDMS↑ |
|---|---|---|---|---|---|---|
| 1 | ✓ | — | — | — | 102M | 85.7 |
| 2 | — | — | — | — | 57M | 55.1 |
| 3 | — | ✓ | — | — | 58M | 87.1 |
| 5 | — | ✓ | ✓ | — | 59M | 87.4 |
| 6 | — | ✓ | ✓ | ✓ | 60M | 88.1 |
关键发现:
- 空间交叉注意力是最关键组件(+32.0 PDMS,ID-2→ID-3)
- 级联机制贡献明显(+0.7 PDMS,ID-5→ID-6)
- Transformer 解码器比 UNet 小 39%(60M vs 102M)但性能更优(88.1 vs 85.7)
去噪步数(Table 4)
| 去噪步数 | PDMS↑ |
|---|---|
| 1 | 87.9 |
| 2 | 88.1 |
| 3 | 88.1 |
采样数(Table 6)
| 采样数 $N_{\text{infer}}$ | PDMS↑ |
|---|---|
| 10 | 84.9 |
| 20 | 88.1 |
| 40 | 88.2 |
2 步去噪已接近饱和;20 条采样轨迹足以覆盖动作空间。
失效场景分析
- NAVSIM 数据集以简单场景为主:88.1 PDMS 在真实复杂城市环境中是否保持有待验证
- 闭环评估为非反应式仿真:其他交通参与者不对 ego 行为做出反应,与真实驾驶有差距
- LiDAR 依赖:NAVSIM 实验使用 Camera+LiDAR,纯视觉方案未充分验证
- 感知模块固定:DiffusionDrive 仅替换规划头,感知误差传导到规划的影响需要更多研究
工程实践
训练配置
[NAVSIM] |
复现要点
- 锚点聚类质量至关重要:K-Means 在训练集全部 GT 轨迹上聚类,20 个中心即可覆盖主要驾驶模式(直行、左转、右转、变道等)
- 截断比例 50/1000:这是一个关键超参数。过大(如 100/1000)噪声太多,2 步难以去噪;过小(如 10/1000)锚点附近多样性不足
- 级联解码器参数共享:不同去噪步复用同一个解码器参数,避免参数膨胀
- 正样本分配:训练时为每个 GT 轨迹找最近锚点作正样本,类似 DETR 的匈牙利匹配但更简单
- 推理灵活性:$N_{\text{infer}}$ 可动态调整——简单场景用 10 条节省算力,复杂场景用 40 条提升覆盖率
性能优化方向
精度提升:
- 增加级联层数(2→4 可提升至 88.2,但参数和延迟增加)
- 增加采样数(20→40 可微提升至 88.2)
- 接入更强感知模块(如 SparseDrive-B 替代 Transfuser)
速度优化:
- 1 步去噪仍有 87.9 PDMS,可在延迟敏感场景使用
- 减少采样数到 10(PDMS 84.9)换取更低延迟
研究启示
可迁移的思想
- 截断扩散 = 先验 + 生成:当动作空间有结构化先验(如驾驶模式、抓取姿态)时,用锚点初始化扩散起点可大幅减少去噪步数,适用于机器人操控、导航等所有需要实时决策的场景
- Transformer 替代 UNet 做去噪:在条件信息丰富(BEV 特征、结构化查询)的场景中,Transformer 解码器比 UNet 更高效且表达力更强
- 少量锚点 > 大量锚点:扩散模型的连续生成能力使 20 个锚点覆盖的动作空间 > 8192 个固定锚点,因为每个锚点可”演化”出一族连续变体
方法局限
- 依赖感知模块提供的 BEV/PV 特征和结构化查询——感知误差会传导到规划
- 非反应式仿真(NAVSIM)的评估结果在闭环真实驾驶中可能大幅下降
- 截断扩散依赖锚点质量——如果训练集不包含某些罕见驾驶模式,推理时也无法生成
技术影响与后续发展
DiffusionDrive 首次将扩散模型成功应用于实时端到端自动驾驶,证明了生成式规划的可行性。截断扩散策略作为通用加速技巧,可推广到其他需要实时生成的应用场景。
DiffusionDrive 发表后,端到端规划的两大路线竞争日趋激烈。生成派方面,DiffusionDriveV2 和基于 Flow Matching 的 GoalFlow 继续在去噪稳定性和 mode collapse 等问题上推进。但出人意料的是,地平线的 SparseDriveV2(arXiv 2026)从评分派的角度发起了反击——通过将轨迹分解为路径×速度的 26 万候选组合,配合粗到细层级评分,以 92.0 PDMS 反超了所有生成式方法,证明静态词表的天花板远高于此前的认知。这场”生成 vs 评分”的路线之争,连同正在兴起的 VLA 路线(DriveVLA-W0、AutoVLA 等),共同构成了端到端自动驾驶最前沿的技术版图。