Task: End-to-End Autonomous Driving (Detection, Tracking, Mapping, Motion Prediction, Planning)
Method: Sparse Scene Representation, Factorized Trajectory Vocabulary, Coarse-to-Fine Scoring
Venue: arXiv 2024 / arXiv 2026
Year: 2024 → 2026
Paper: SparseDrive / SparseDriveV2
Code: SparseDrive
摘要
现有端到端自动驾驶方法依赖计算昂贵的 BEV 特征,且预测和规划的设计过于简单,安全性不足。本文提出 SparseDrive,一种以稀疏表示为核心的端到端自动驾驶范式。SparseDrive 包含两大核心模块:对称稀疏感知(Symmetric Sparse Perception)用对称的模型结构统一检测、跟踪和在线建图,学习全稀疏的场景表示;并行运动规划器(Parallel Motion Planner)同时预测周围智能体和自车的多模态轨迹,并通过分层规划选择策略(命令过滤 + 碰撞感知重评分)选出安全轨迹。SparseDrive-S 仅用 ResNet-50,在所有任务上超越 UniAD,同时训练快 7.2×、推理快 5.0×(9.0 FPS);SparseDrive-B 以 0.58m avg L2 和 0.06% avg Col 将规划性能推至新高。
核心论点:端到端自动驾驶不需要昂贵的 BEV 特征——稀疏实例表示(特征+锚框/折线)足以编码驾驶场景,而运动预测与规划的高度相似性允许并行设计,将规划建模为多模态问题并通过碰撞感知重评分保障安全。
问题与动机
UniAD 等 BEV-Centric 端到端方法取得了突破性进展,但存在两大瓶颈:
| 问题 | 影响 | UniAD 具体表现 |
|---|---|---|
| BEV 特征计算昂贵 | 训练慢、推理慢、显存大 | 1709 GFLOPs,1.8 FPS,50G 显存 |
| 预测/规划设计简单 | 规划安全性不足 | 碰撞后处理反而增加碰撞率 |
| 预测和规划串行 | 忽略自车对周围智能体的影响 | 单向信息流 |
| 规划单模态 | 无法表达多种合理行为 | 只预测一条确定性轨迹 |
SparseDrive 观察到运动预测和规划有三个被忽视的相似性:
- 两者都需要建模高阶双向交互(自车影响他车,他车影响自车)
- 两者都需要语义+几何信息(但前人仅为周围智能体提取这些信息,忽略了自车)
- 两者都是多模态问题(但前人规划只输出单条确定性轨迹)
核心洞察
洞察 1:全稀疏表示——不需要 BEV 特征的端到端驾驶
传统做法:BEVFormer/LSS 构建稠密 BEV 特征图(200×200×256),然后在 BEV 上做检测、分割和规划。
SparseDrive 做法:用稀疏实例(特征向量 + 锚框/折线)表示场景。检测分支用 900 个锚框(位置+尺寸+朝向+速度 11 维),建图分支用 100 个锚折线(20 点 × 2 维)。两者共享对称的解码器结构:可变形聚合 → FFN → 输出层 → 时序交叉注意力 → 自注意力。
为什么更好:去掉 BEV 特征后,FLOPs 从 1709G(UniAD)降至 192G(SparseDrive-S),FPS 从 1.8 提升至 9.0(5.0× 加速),训练时间从 144h 降至 20h(7.2× 加速),GPU 显存从 50G 降至 15.2G。更关键的是,稀疏表示的性能不降反升——SparseDrive-S 比 UniAD 在检测 mAP、跟踪 AMOTA、运动 minADE 上均更优。
洞察 2:并行预测+规划——自车也是一个智能体
传统做法(UniAD/VAD):先做运动预测(预测周围智能体未来轨迹),再用预测结果辅助规划。信息单向流动,自车对周围智能体的影响被忽略。
SparseDrive 做法:用前视摄像头最小特征图的全局池化初始化 ego 实例(提供语义信息),将 ego 与周围智能体实例拼接,在同一个 Transformer 中做 agent-temporal、agent-agent、agent-map 交互,然后同时解码所有智能体(含自车)的多模态轨迹。
为什么更好:消融实验(Table 4)显示,去掉并行设计(改为串行)后运动预测 minADE 从 0.623 上升至 0.641,碰撞率从 0.08% 上升至 0.10%。去掉 ego 实例初始化后 avg L2 从 0.61 升至 0.63,碰撞率从 0.08% 升至 0.11%。
洞察 3:碰撞感知重评分——后处理优化反而有害
传统做法(UniAD):推理时用 Newton 法基于占用图优化规划轨迹。看似合理,但 SparseDrive 发现这种后处理不仅未降低碰撞率,反而使碰撞率从 0.25% 上升至 0.61%(重新实现的碰撞率指标下),L2 从 0.61 上升至 0.73。
SparseDrive 做法:规划输出 6 条多模态轨迹。先按导航命令(左转/右转/直行)筛选子集,再用碰撞感知重评分——利用运动预测的 top-2 轨迹检查自车各规划方案是否碰撞,将碰撞方案的分数置零,最后选最高分轨迹。
为什么更好:碰撞感知重评分将碰撞率从 0.12% 降至 0.08%(Table 5),几乎不增加 L2 误差(0.61→0.61),且保持端到端范式一致性(不破坏梯度流)。
三个关键数字:
- 0.06% avg Col
:SparseDrive-B 的碰撞率,比 VAD(0.21%)降低 71.4% - 9.0 FPS
:SparseDrive-S 的推理速度,比 UniAD(1.8)快 5.0× - 192 GFLOPs
:SparseDrive-S 的计算量,仅为 UniAD(1709)的 11%
方法设计
整体架构
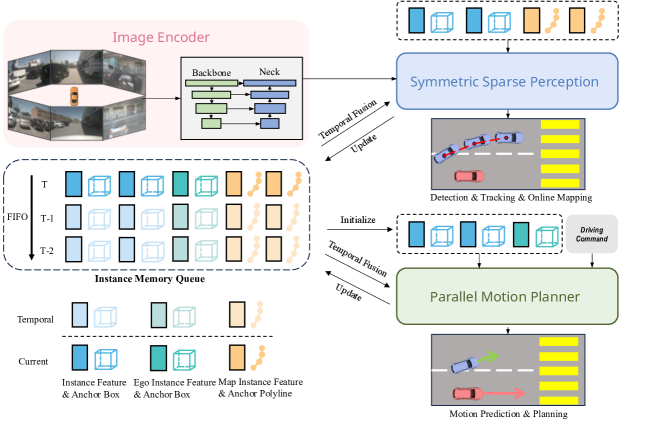
多视图 6 cam |
关键组件
| 模块 | 输入 | 输出 | 核心设计 |
|---|---|---|---|
| 对称稀疏感知(检测) | 多尺度图像特征 $I$ | 实例特征 $F_d$ + 锚框 $B_d$ | 可变形聚合 + 时序交叉注意力 + 自注意力 |
| 对称稀疏感知(建图) | 同上 | 实例特征 $F_m$ + 锚折线 $L_m$ | 与检测分支结构对称,折线用 20 点表示 |
| 稀疏跟踪 | 时序传播实例 | 带 ID 的跟踪结果 | Sparse4Dv3 式 ID 分配,无跟踪损失 |
| Ego 实例初始化 | 前视最小特征图 | $F_e, B_e$ | 全局平均池化 + 辅助 ego status 预测 |
| 并行运动规划器 | $F_d, F_e, F_m$ | 多模态轨迹 + 分数 | agent-temporal/agent-agent/agent-map 交互 |
| 碰撞感知重评分 | 多模态规划方案 + 运动预测 | 最终安全轨迹 | top-2 预测轨迹碰撞检测,碰撞方案分数置零 |
损失函数:
$$\mathcal{L} = \mathcal{L}_{\text{det}} + \mathcal{L}_{\text{map}} + \mathcal{L}_{\text{motion}} + \mathcal{L}_{\text{plan}} + \mathcal{L}_{\text{depth}}$$各项均包含分类(Focal)+ 回归(L1)损失。运动和规划采用 Winner-Takes-All 策略(ADE 最小的模态为正样本)。规划额外预测当前 ego status(速度、加速度、角速度、转角)。
实验与分析
主要结果
nuScenes val 规划(Table 2b)
| 方法 | L2 1s↓ | L2 2s↓ | L2 3s↓ | avg L2↓ | Col 1s↓ | Col 2s↓ | Col 3s↓ | avg Col↓ |
|---|---|---|---|---|---|---|---|---|
| UniAD† | 0.45 | 0.70 | 1.04 | 0.73 | 0.62 | 0.58 | 0.63 | 0.61 |
| VAD† | 0.41 | 0.70 | 1.05 | 0.72 | 0.03 | 0.19 | 0.43 | 0.21 |
| SparseDrive-S | 0.29 | 0.58 | 0.96 | 0.61 | 0.01 | 0.05 | 0.18 | 0.08 |
| SparseDrive-B | 0.29 | 0.55 | 0.91 | 0.58 | 0.01 | 0.02 | 0.13 | 0.06 |
注:UniAD/VAD 结果为 SparseDrive 重新实现的碰撞率指标(考虑 ego heading 变化,使用 BBox 重叠而非占用图)。
感知与运动预测
| 指标 | UniAD | SparseDrive-S | SparseDrive-B |
|---|---|---|---|
| det mAP↑ | 0.380 | 0.418 | 0.496 |
| det NDS↑ | 0.498 | 0.525 | 0.588 |
| AMOTA↑ | 0.359 | 0.386 | 0.501 |
| IDS↓ | 906 | 886 | 632 |
| map mAP↑ | — | 55.1 | 56.2 |
| minADE↓ | 0.71 | 0.62 | 0.60 |
| minFDE↓ | 1.02 | 0.99 | 0.96 |
效率对比(Table 3)
| 方法 | 训练显存 | 训练时间 | FLOPs | 参数量 | FPS |
|---|---|---|---|---|---|
| UniAD | 50.0G | 144h | 1709G | 125.0M | 1.8 |
| SparseDrive-S | 15.2G | 20h | 192G | 85.9M | 9.0 |
| SparseDrive-B | 17.6G | 30h | 787G | 104.7M | 7.3 |
消融实验:验证三个洞察
运动规划器设计消融(Table 4)
| ID | PAL | EII | MTM | ATA | CAR | minADE↓ | avg L2↓ | avg Col↓ |
|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | ✓ | ✓ | ✓ | ✓ | 0.623 | 0.61 | 0.08 |
| 2 | — | ✓ | ✓ | ✓ | ✓ | 0.641 | 0.61 | 0.10 |
| 3 | ✓ | — | ✓ | ✓ | ✓ | 0.621 | 0.63 | 0.11 |
| 4 | ✓ | ✓ | — | ✓ | ✓ | 0.626 | 0.69 | 0.25 |
| 5 | ✓ | ✓ | ✓ | — | ✓ | 0.634 | 0.77 | 0.16 |
PAL=并行设计, EII=Ego 初始化, MTM=多模态规划, ATA=Agent-temporal attention, CAR=碰撞感知重评分。
关键发现:
- 去掉多模态规划(ID-4)碰撞率暴增至 0.25%(3.1×)
- 去掉 agent-temporal attention(ID-5)L2 误差升至 0.77m(+26%)
- 碰撞感知重评分(ID-1 vs ID-6=无 CAR)将碰撞率从 0.12% 降至 0.08%
失效场景分析
- 在线建图
:单任务方法 MapTR 的 mAP(58.7)仍高于 SparseDrive-B(56.2),端到端优化未能充分释放建图性能 - 开环评估局限
:nuScenes 开环评估无法全面衡量安全性和交互能力 - 数据规模
:nuScenes 仅 1000 场景,不足以发挥端到端学习的全部潜力
工程实践
训练配置
Backbone: ResNet-50 (S) / ResNet-101 (B) |
复现要点
- 对称感知的关键是锚框初始化
:检测和建图的锚框位置均由训练集 K-Means 聚类得到,直接影响收敛速度 - Ego 速度不能用 GT
:直接用 GT 速度初始化 ego 锚框会导致 ego status 信息泄露,需通过辅助任务预测速度并用上一帧预测值初始化 - 碰撞检测用 BBox 重叠
:不同于 UniAD 用 0.5m 占用图(会产生假碰撞),SparseDrive 用 ego BBox 和障碍物 BBox 的实际重叠判断碰撞,并考虑 ego heading 变化 - 跟踪无需额外损失
:Sparse4Dv3 式 ID 分配——检测置信度超过 0.2 即锁定 ID,时序传播自然保持身份一致性 - Flash Attention 显存优化
:在 self-attention 和 cross-attention 中使用 Flash Attention,显存从约 25G 降至 15.2G(SparseDrive-S)
性能优化方向
精度提升:
- 更大 backbone(R101,512×1408)从 S→B 提升检测 mAP +7.8,碰撞率降低 25%(0.08→0.06)
- 更长时序记忆(当前仅 3 帧),可引入更长历史提升运动预测精度
速度优化:
- SparseDrive-S 已达 9.0 FPS(4090),进一步轻量化可考虑减少锚框数量或解码器层数
- 去掉深度辅助损失可减少训练开销,但可能影响感知精度
研究启示
可迁移的思想
- 稀疏表示替代 BEV
:对于不需要稠密空间推理的任务,稀疏实例表示可大幅降低计算成本,适用于端到端机器人操控、无人机导航等资源受限场景 - 并行预测+规划
:将自车视为”又一个智能体”参与联合预测,通过共享 Transformer 天然建模双向交互 - 碰撞感知重评分 > 后处理优化
:基于预测结果的碰撞检测比基于占用图的后处理优化更安全、更高效 - 对称模型设计
:检测和建图用相同的解码器结构(仅锚框定义不同),简化了代码实现和调参
方法局限
- 开环评估(nuScenes)不足以证明闭环安全性
- 无 BEV 特征意味着缺少稠密空间信息,对 OccFormer 式的占用预测不友好
- 碰撞重评分依赖运动预测精度——如果预测不准,碰撞检测也不可靠
技术影响
- SparseDrive 证明了 BEV 特征不是端到端自动驾驶的必需品,稀疏表示在性能和效率上均可超越 BEV-Centric 方案
- 并行预测+规划的范式被后续 DiffusionDrive 等方法采纳,成为新的设计趋势
- 提出的碰撞率评估修正(考虑 ego heading + BBox 重叠)被社区采用为更公平的规划评估标准
SparseDrive 解决了端到端自动驾驶的表示效率问题——证明稀疏表示足以替代 BEV。但自动驾驶的核心挑战还有另一面:规划质量。当 DiffusionDrive 等生成式方法将多模态规划推向新高度时,SparseDriveV2 从评分范式出发,给出了一个出人意料的回答。
SparseDriveV2:Scoring is All You Need
Paper: SparseDriveV2
摘要
SparseDriveV2 重新审视了端到端自动驾驶中”静态候选轨迹 vs 生成式轨迹”的路线之争。通过 Scaling Study 发现,Hydra-MDP 的静态轨迹锚点从 1024 增至 16384 时,EPDMS 从 85.02 持续上涨至 87.35,直到 32768 才因显存溢出停止——性能并未饱和,先撞墙的是算力。这说明过去对静态词表的不满,核心原因不是”打分派范式不行”,而是词表覆盖率不够。
基于这一判断,SparseDriveV2 提出两项核心创新:(1)分解式轨迹词表(Factorized Vocabulary):将轨迹拆分为几何路径 path 和速度轮廓 velocity profile 的自由组合,以 1024 × 256 = 262,144 条候选覆盖极密的轨迹空间;(2)粗到细的分解评分(Coarse-to-Fine Factorized Scoring):先分别对 path 和 velocity 粗打分淘汰,再对少量高质量组合精细打分,将实际评分量从 26 万压缩至 400 条。最终在 NAVSIM 上达到 92.0 PDMS 和 90.1 EPDMS,以纯评分范式刷新端到端自动驾驶 SOTA。
核心论点:静态候选轨迹的瓶颈不在于范式,而在于覆盖率——通过路径×速度的分解式组合,词表可以指数级扩展而不爆显存;配合粗到细的层级评分,”Scoring is All You Need”足以匹敌乃至超越生成式方法。
问题与动机
SparseDriveV2 诞生于端到端自动驾驶的三条主线交汇之处:
| 路线 | 代表方法 | 核心思路 | 局限 |
|---|---|---|---|
| Planning-Oriented 统一范式 | UniAD, SparseDrive | 全栈端到端,打通感知-预测-规划 | 规划为单模态/有限模态 |
| 多模态规划候选集之争 | VADv2, Hydra-MDP, DiffusionDrive, GoalFlow | 静态词表打分 / 扩散生成 / Flow Matching | 静态词表太稀 or 生成模型复杂 |
| VLA / 世界模型 | DriveVLA-W0, Alpamayo-1, AutoVLA | 语义理解 + 未来想象 + 动作规划一体化 | 实时性差,安全约束难满足 |
在第二条路线中,生成式方法(DiffusionDrive、DiffusionDriveV2、GoalFlow)日益强势,但伴随着额外的 proposal 生成、去噪过程、mode collapse 等复杂性。SparseDriveV2 反其道而行,回到评分范式,追问一个被大多数人放弃的问题:
核心痛点:静态候选轨迹真的不行了吗?还是只是没人把词表做得够密?
核心洞察
洞察 1:Scaling Study——静态词表的真正瓶颈是覆盖率
传统认知:静态轨迹锚点(如 Hydra-MDP 的 8192 条)天然不如生成式方法灵活,无法覆盖复杂场景的真实可行解。
SparseDriveV2 发现:在 Hydra-MDP 上做 Scaling 实验,锚点数从 1024 逐步增至 32768:
| 轨迹锚点数 | EPDMS |
|---|---|
| 1024 | 85.02 |
| 4096 | 86.58 |
| 8192 | 86.83 |
| 16384 | 87.35 |
| 32768 | 显存溢出 |
关键结论:性能在 16384 anchors 时仍未饱和,先撞墙的是显存——说明”打分派天然不如生成派”的结论下得太早,覆盖率不够才是根本原因。
洞察 2:分解式轨迹词表——路径 × 速度 = 组合爆炸
传统做法:将完整轨迹 $\tau = {(x_t, y_t)}_{t=1}^T$ 作为不可分的整体聚类成锚点。想覆盖”左转半径 × 并线角度 × 加减速节奏 × 刹停时机”等组合,词表指数级膨胀。
SparseDriveV2 做法:将轨迹分解为两个独立维度:
$$\tau = \text{Compose}(P, V)$$其中几何路径 $P$ 描述”车往哪走”(空间形状),速度轮廓 $V$ 描述”以多快节奏走”(时间演化)。速度由相邻时刻位置差分得到:
$$v_t = \sqrt{(x_{t+1}-x_t)^2 + (y_{t+1}-y_t)^2} / \Delta t$$累计路程 $s_t = \sum_{i=1}^{t} v_i \cdot \Delta t$ 定义了沿路径的行进距离,再通过插值即可将 path 和 velocity 重新组合为一条完整轨迹。
词表规模从一维枚举变为组合式扩展:
$$|\text{Vocabulary}| = N_{\text{path}} \times N_{\text{velocity}}$$最终设置 1024 path anchors × 256 velocity anchors = 262,144 候选轨迹,是此前常见 8192 anchors 的 32× 密度。
为什么更好:同样的存储和聚类成本下,词表密度指数级提升。”路线模板”和”速度节奏”的自由配对,让词表不再需要穷举所有时空组合。
洞察 3:粗到细的分解评分——层级筛选压缩计算量
传统做法:给定场景特征,对每条候选轨迹逐一打分 $s_i = f(\tau_i, \mathbf{c})$。当词表涨到 26 万条时,逐条评分的计算量线性爆炸。
SparseDriveV2 做法:既然轨迹已被拆为 path 和 velocity,评分也可以分两阶段做:
- Coarse Factorized Scoring
:分别给 path anchors 和 velocity anchors 独立粗打分,保留 top-128 paths 和 top-64 velocities - Fine-Grained Trajectory Scoring
:第二层进一步收缩至 20 paths × 20 velocities =
400 条
composed trajectories,再做精细打分
打分器不是单纯的 imitation learning,同时使用 path loss、velocity loss、trajectory-level soft classification loss,再叠加 rule-based metric supervision:
$$\mathcal{L}_{\text{V2}} = \mathcal{L}_{\text{path}} + \mathcal{L}_{\text{velocity}} + \mathcal{L}_{\text{traj-cls}} + \mathcal{L}_{\text{metric}}$$为什么更好:从 262,144 → top-128×64 → 20×20 = 400,实际精细打分的轨迹数量压缩了 655×。层级筛选让超密词表不仅可行,而且高效。
三个关键数字:
- 262,144
:分解式词表覆盖的候选轨迹总数(1024 path × 256 velocity),是传统 8192 anchors 的 32× - 400
:最终进入精细打分的轨迹数量(20 paths × 20 velocities),仅占词表的 0.15% - 90.1 EPDMS
:NAVSIM 新 SOTA,纯评分范式超越 DiffusionDrive(88.1)等生成式方法
方法设计
整体架构
$$\tau^* = \arg\max_{\tau \in \text{Top-}k(\mathcal{P}) \times \text{Top-}k(\mathcal{V})} \; f_{\text{fine}}(\text{Compose}(p, v), \mathbf{c})$$多视图 6 cam |
关键组件
| 模块 | 输入 | 输出 | 核心设计 |
|---|---|---|---|
| 分解式词表 | 训练集轨迹 | 1024 paths + 256 velocities | path 和 velocity 分别 K-Means 聚类 |
| Path-Scene Interaction | path anchors + 场景特征 | path 评分 | 可变形聚合(Deformable Aggregation) |
| Coarse Scoring | path/velocity + 场景特征 | top-128 paths, top-64 velocities | 独立通道打分,淘汰低分候选 |
| Trajectory Composition | top-k paths × top-k velocities | composed trajectories | 沿 path 按 velocity 距离插值重组 |
| Trajectory Re-conditioning | composed 轨迹 + 场景特征 | 精调后轨迹 | 条件注入增强场景一致性 |
| Fine-Grained Scoring | 400 条 composed 轨迹 | 最终 $\tau^*$ | 精细逐条打分,选最高分 |
实验与分析
NAVSIM 主要结果
| 方法 | 范式 | PDMS↑ | EPDMS↑ |
|---|---|---|---|
| Hydra-MDP (8192) | 静态词表打分 | — | 86.83 |
| DiffusionDrive | 截断扩散生成 | 88.1 | — |
| GoalFlow | Flow Matching | — | — |
| SparseDriveV2 | 分解式词表打分 | 92.0 | 90.1 |
消融实验
词表密度消融
| Path × Velocity | 候选总数 | EPDMS |
|---|---|---|
| 512 × 128 | 65,536 | 88.7 |
| 1024 × 256 | 262,144 | 90.1 |
词表从 512×128 提升至 1024×256,EPDMS 提升 +1.4,且未出现性能饱和,验证了更密词表持续有效的核心判断。
打分架构消融
| 组件 | 效果 |
|---|---|
| Path-Scene Interaction → Deformable Aggregation | 有效提升 |
| + Trajectory Re-conditioning | 继续提升 |
| 最强配置 = 更密分解词表 + 更强 Coarse-to-Fine 打分 | 90.1 EPDMS |
V1 → V2 演进对比
| 维度 | SparseDrive V1 | SparseDriveV2 |
|---|---|---|
| 核心问题 | BEV 特征计算昂贵 | 静态词表覆盖不足 |
| 解法 | 稀疏实例替代 BEV | 分解式词表 + 层级打分 |
| 轨迹表示 | 6 条多模态轨迹(回归) | 262,144 条候选(path×velocity 组合) |
| 规划范式 | 并行运动规划器 + 碰撞感知重评分 | Coarse-to-Fine Factorized Scoring |
| 评估基准 | nuScenes 开环 | NAVSIM |
| PDMS | — | 92.0 |
| 关键洞察 | BEV 不是必需品 | Scoring is All You Need |
研究启示(V2)
V2 可迁移的思想
- 分解式表示
:将高维搜索空间拆分为低维子空间的组合,适用于任何需要大规模候选集的决策问题(机器人抓取姿态、无人机路径规划等) - Coarse-to-Fine 层级筛选
:在超大候选空间中,先粗筛再精选是平衡覆盖率与计算量的通用策略 - Scaling Study 先行
:在提出新方法前,先做 scaling 分析验证当前方法的真正瓶颈,避免”解决了一个不存在的问题”
V2 技术定位
SparseDriveV2 选择了一条与主流生成式方法相反的路线。DiffusionDrive/DiffusionDriveV2/GoalFlow 等方法通过动态生成 proposal 解决多模态规划;VLA 路线(DriveVLA-W0、Alpamayo-1、AutoVLA)则将语言推理和世界模型引入驾驶。SparseDriveV2 证明了:只要词表足够密、打分足够强,纯评分范式的性能天花板远高于此前的认知。两条路线并非对立,而是对端到端自动驾驶不同维度的探索。