Task: Multi-Camera 3D Object Detection
Method: LSS View Transformer, BEV Data Augmentation, Scale-NMS, Temporal BEV Fusion
Venue: arXiv
Year: 2021 (BEVDet) / 2022 (BEVDet4D)
Paper: https://arxiv.org/abs/2112.11790 (BEVDet) / https://arxiv.org/abs/2203.17054 (BEVDet4D)
Code: https://github.com/HuangJunJie2017/BEVDet
摘要
本文提出 BEVDet 范式,首次将 BEV 语义分割中成熟的 Lift-Splat-Shoot(LSS)框架系统性地应用于多相机 3D 目标检测任务。BEVDet 采用模块化设计:图像视图编码器(Image-view Encoder)提取特征→视图变换器(View Transformer, 即 LSS)将图像特征提升到 BEV→BEV 编码器进一步编码 BEV 特征→CenterPoint 检测头在 BEV 空间完成 3D 目标检测。虽然框架的各模块均复用已有工作,但 BEVDet 通过两项关键贡献显著提升了性能:(1)发现 LSS 视图变换器解耦了图像视图与 BEV 视图的数据增强,据此设计了图像空间(IDA)+ BEV 空间(BDA)的双重数据增强策略,从根本上解决了 BEV 空间学习的过拟合问题;(2)提出 Scale-NMS 解决 BEV 空间中小物体(行人、交通锥)因占地面积小于网格分辨率而导致传统 NMS 失效的问题。在 nuScenes 数据集上,BEVDet-Tiny 以 704×256 输入仅需 215.3 GFLOPs 即达到 31.2% mAP / 39.2% NDS,比 FCOS3D 快 9.2 倍;BEVDet-Base 以 1600×640 输入达到 39.3% mAP / 47.2% NDS,大幅超越所有已发表结果。
核心论点:将 LSS 从 BEV 分割迁移到 3D 目标检测的关键不在于架构创新,而在于解决 BEV 空间过拟合——视图变换器的像素级坐标映射在数据增强层面解耦了两个视图空间,使得独立的 BEV 数据增强成为可能,这一发现开启了 BEVDet 系列及整个 BEV 3D 检测方向的快速发展。
问题与动机
自动驾驶多相机 3D 目标检测在 2021 年底主要由图像视图方法主导,缺少一个统一且可扩展的 BEV 范式。
| 方法类型 | 代表作 | 核心问题 | nuScenes val (mAP/NDS) | FPS |
|---|---|---|---|---|
| 图像视图检测 | FCOS3D | 逐视图独立检测,难以感知 BEV 尺度/朝向/速度 | 29.5/37.2 | 1.7 |
| 图像视图+深度 | PGD | 额外深度估计模块增加计算量 | 33.5/40.9 | 1.4 |
| Query-based | DETR3D | 注意力流程复杂,推理速度与 FCOS3D 相当 | 30.3/37.4 | 2.0 |
| BEV 分割 | LSS | 仅用于分割,未扩展到 3D 检测 | — | — |
一个自然的想法是将 LSS 的 BEV 分割框架(Image Encoder → View Transformer → BEV Encoder → Head)直接用于 3D 目标检测。然而,作者发现直接迁移后严重过拟合:mAP 在第 4 epoch 即饱和(23.0%),到第 20 epoch 大幅下降到 17.4%——远低于 FCOS3D 的 29.5%。
过拟合的根源在于:
- 每个训练样本在 BEV 空间只对应一份数据(不像图像视图每个 sample 有 6 张图),BEV 空间训练数据量不足
- LSS 的视图变换通过逆内参矩阵 $I^{-1}$ 逐像素映射坐标,图像空间的数据增强变换 $A$ 会被 $A^{-1}$ 精确抵消,对 BEV 编码器和检测头无任何正则化效果
核心痛点:如何解决 BEV 空间训练数据不足导致的过拟合问题,使 LSS 范式在 3D 目标检测上发挥出应有的性能。
核心洞察
洞察 1:视图变换器解耦两个视图空间的数据增强
LSS 视图变换器通过相机内参 $I$ 和图像增强变换 $A$ 将像素坐标映射到 3D 空间:
$$\mathbf{p}_{\text{camera}} = I^{-1}(\mathbf{p}_{\text{image}} \cdot d)$$ 当图像施加数据增强 $\mathbf{p}'_{\text{image}} = A \cdot \mathbf{p}_{\text{image}}$ 时,视图变换器会施加逆变换 $A^{-1}$: $$\mathbf{p}'_{\text{camera}} = I^{-1}(A^{-1} \cdot \mathbf{p}'_{\text{image}} \cdot d) = I^{-1}(\mathbf{p}_{\text{image}} \cdot d) = \mathbf{p}_{\text{camera}}$$这意味着图像空间的任何增强(翻转、旋转、裁剪)在 BEV 空间完全不可见——BEV 编码器和检测头的输入不受任何影响。
传统做法:只在图像空间做数据增强(翻转、缩放、旋转),期望正则化整个网络
BEVDet 做法:在图像空间做 IDA(正则化 Image Encoder)+ 在 BEV 空间独立做 BDA(翻转、旋转 ±22.5°、缩放 0.95~1.05,正则化 BEV Encoder + Head)
为什么关键:消融实验表明(Tab. 4),仅用 IDA 无 BDA 时 mAP 从 23.0%→20.5%(反而下降!),仅用 BDA 无 IDA 时 26.2%,两者结合时 31.6%——BDA 是 BEVDet 性能的根基,贡献了大部分提升。
洞察 2:Scale-NMS——解决 BEV 小物体的 NMS 失效
在 BEV 空间中,不同类别物体的占地面积差异巨大:汽车可能占多个 grid cell,但行人和交通锥的实际尺寸(约 0.5m)可能小于 BEV 分辨率(0.8m)。这导致传统 NMS 基于 IoU 的抑制策略完全失效——两个关于同一行人的冗余预测框之间 IoU 为零,NMS 无法抑制。
传统 NMS:按 IoU 阈值抑制重叠框,对 BEV 小物体失效
Circular-NMS(CenterPoint):基于中心距离抑制,有所改善但不够精确
Scale-NMS(BEVDet):在 NMS 前按类别缩放框尺寸,使小物体的重叠框产生有效 IoU
为什么有效:Scale-NMS 将类别特定的尺度因子作为超参数,通过在验证集上搜索得到。对行人 +4.8% AP,交通锥 +7.5% AP,整体 +1.7% mAP(29.5%→31.2%)。
洞察 3:模块化设计——BEV 范式的可扩展性基础
BEVDet 的核心设计哲学是模块化:每个模块(Image Encoder、View Transformer、BEV Encoder、Head)独立且可替换。这不是技术创新,但是范式选择的深远影响。
图像视图方法(FCOS3D):检测在图像坐标系完成,难以感知 BEV 空间的尺度/朝向/速度
BEVDet:检测在 BEV 坐标系完成,天然适合感知这些在 BEV 空间有清晰几何含义的属性
BEVDet 在预测位移(ATE)、尺度(ASE)、朝向(AOE)、速度(AVE)上均显著优于 FCOS3D,仅在属性预测(AAE)上稍弱(属性依赖外观线索,图像视图更擅长)。更重要的是,模块化设计使 BEVDet 成为可持续演进的框架——后续的 BEVDet4D(时序融合)、BEVDepth(深度监督)、BEVPoolv2(部署优化)都是在此基础上替换或增强单个模块。
三个关键数字:
- 39.3% mAP / 47.2% NDS:BEVDet-Base 在 nuScenes val 上达到的 SOTA 性能,超 PGD 达 +5.8% mAP / +6.3% NDS
- 15.6 FPS:BEVDet-Tiny 的推理速度,是 FCOS3D(1.7 FPS)的 9.2 倍
- +8.6% mAP:IDA + BDA 双重数据增强相比无增强 baseline 的提升幅度
方法设计
4.1 整体架构
给定 $n=6$ 个相机的图像,BEVDet 输出 BEV 空间的 3D 检测框:
$$\text{Images} \xrightarrow{\text{Image Encoder}} \text{Image Features} \xrightarrow{\text{View Transformer (LSS)}} \text{BEV Features} \xrightarrow{\text{BEV Encoder}} \text{Encoded BEV} \xrightarrow{\text{CenterPoint Head}} \text{3D Boxes}$$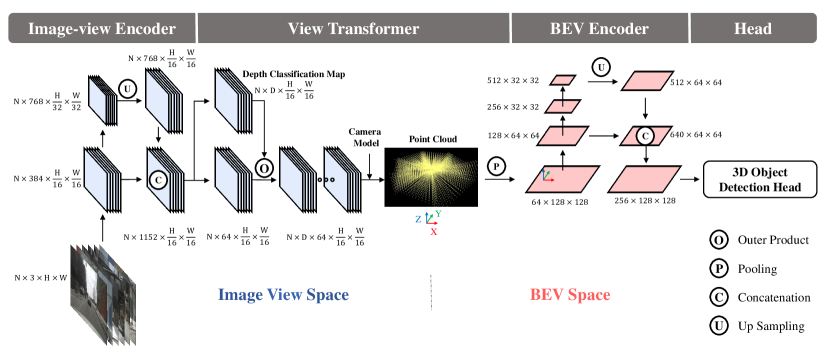
输入:6 张图像 (704×256 / 1600×640)
│
▼
┌──────────────────────────────┐
│ Image-view Encoder │
│ Backbone: SwinT/R50/R101 │
│ Neck: FPN-LSS (512ch) │ × 6 cameras, 共享权重
└──────────────┬───────────────┘
│ IDA (Image Data Aug)
▼
┌──────────────────────────────┐
│ View Transformer (LSS) │
│ depth ∈ [1, 60]m, Δ=1.25r │
│ 深度分类 + 外积 + Pillar Pool │ IDA 在此被 A⁻¹ 抵消
└──────────────┬───────────────┘
│ BDA (BEV Data Aug)
│ 翻转 + 旋转±22.5° + 缩放0.95~1.05
▼
┌──────────────────────────────┐
│ BEV Encoder │
│ ResNet Basic Blocks │
│ 128→256→512 + FPN-LSS │
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ CenterPoint Head (Stage 1) │
│ heatmap + offset + size + │
│ rotation + velocity │ Scale-NMS 后处理
└──────────────────────────────┘
│
▼
3D Bounding Boxes + Velocity
4.2 关键组件
| 模块 | BEVDet-Tiny | BEVDet-Base | 功能 |
|---|---|---|---|
| Backbone | SwinTransformer-Tiny | SwinTransformer-Base | 图像特征提取 |
| Neck | FPN-LSS-512 | FPN-LSS-512 | 多尺度特征融合 |
| View Transformer | LSS-64-0.8m | LSS-64-0.4m | 图像→BEV,64ch,0.8m/0.4m 分辨率 |
| BEV Encoder | 2×Basic-128/256/512 + FPN | 同左 | BEV 特征编码 |
| Head | CenterPoint Stage1 | CenterPoint Stage1 | 3D 检测(10 类) |
| Input Size | 704×256 | 1600×640 | — |
| Parameters | 53.7M | 126.6M | — |
| GFLOPs | 215.3 | 2,962.6 | — |
损失函数:
沿用 CenterPoint 检测头的标准损失组合:
$$\mathcal{L} = \mathcal{L}_{\text{heatmap}} + \lambda_1 \mathcal{L}_{\text{offset}} + \lambda_2 \mathcal{L}_{\text{size}} + \lambda_3 \mathcal{L}_{\text{rotation}} + \lambda_4 \mathcal{L}_{\text{velocity}}$$其中 heatmap 使用 Focal Loss,其余使用 L1 Loss。
4.3 关键代码
| 函数 / 类 | 任务 |
|---|---|
LSSViewTransformer |
LSS 视图变换器(含 BEVPoolv2 优化) |
voxel_pooling_prepare_v2 |
预计算 Frustum Pooling 索引 |
bev_pool_v2_kernel |
CUDA forward kernel |
DepthNet |
Camera-Aware 深度预测网络(BEVDepth 扩展) |
📄 点击展开 LSSViewTransformer.forward 代码
(来源:mmdet3d/models/necks/view_transformer.py)
def forward(self, input): |
📄 点击展开 BEVPoolv2 CUDA Forward Kernel 代码
(来源:mmdet3d/ops/bev_pool_v2/src/bev_pool_cuda.cu)
/* |
实验与分析
5.1 主要结果
nuScenes val set 对比:
| 方法 | Input Size | Modality | mAP | NDS | GFLOPs | FPS |
|---|---|---|---|---|---|---|
| FCOS3D | 1600×900 | Camera | 29.5 | 37.2 | 2,008.2 | 1.7 |
| PGD | 1600×900 | Camera | 33.5 | 40.9 | 2,223.0 | 1.4 |
| DETR3D | 1600×900 | Camera | 30.3 | 37.4 | 1,016.8 | 2.0 |
| BEVDet-Tiny | 704×256 | Camera | 31.2 | 39.2 | 215.3 | 15.6 |
| BEVDet-Base | 1600×640 | Camera | 39.3 | 47.2 | 2,962.6 | 1.9 |
| PointPillar (LiDAR) | — | LiDAR | 50.3 | 60.2 | — | — |
nuScenes test set:
| 方法 | mAP | NDS |
|---|---|---|
| FCOS3D | 35.8 | 42.8 |
| PGD | 38.6 | 44.8 |
| DETR3D | 38.6 | 47.9 |
| BEVDet | 42.2 | 48.2 |
| PointPillars (LiDAR) | 30.5 | 45.3 |
关键发现:
- BEVDet-Tiny 仅用 FCOS3D 1/8 的输入分辨率和 1/10 的计算量,即超越其精度,推理速度快 9.2 倍
- BEVDet 在位移(ATE)、尺度(ASE)、朝向(AOE)、速度(AVE)等 BEV 空间定义的属性上大幅优于图像视图方法
- 纯视觉的 BEVDet(42.2% mAP)已可对标经典 LiDAR 方法 PointPillars(30.5% mAP)
5.2 消融实验:验证三个洞察
数据增强策略消融(BEVDet-Tiny,20 epochs):
| ID | IDA | BDA | BEV Encoder | mAP-best | mAP-final | 过拟合 drop | 验证洞察 |
|---|---|---|---|---|---|---|---|
| A | ✗ | ✗ | ✓ | 23.0 (e4) | 17.4 | -5.6% | 洞察 1 |
| B | ✓ | ✗ | ✓ | 20.5 (e10) | 17.8 | -2.7% | 洞察 1 |
| C | ✗ | ✓ | ✓ | 26.2 (e11) | 23.6 | -2.6% | 洞察 1 |
| D | ✓ | ✓ | ✓ | 31.6 (e17) | 31.2 | -0.4% | 洞察 1 |
| H | ✓ | ✓ | ✗ | 29.9 (e20) | 29.9 | -0.0% | 洞察 3 |
- 洞察 1 验证:B vs. A 表明仅 IDA 反而降低 peak(23.0→20.5),因为 IDA 对 BEV 空间无正则化效果;C vs. A 表明 BDA 才是关键(23.0→26.2);D 组合后 31.6,消除过拟合
- 洞察 2 验证:Scale-NMS 对行人 +4.8% AP、交通锥 +7.5% AP,整体 29.5→31.2 mAP
- 洞察 3 验证:D vs. H 表明 BEV Encoder 贡献 +1.7% mAP(29.9→31.2),但其性能建立在 BDA 正则化之上
5.3 性能瓶颈分析
- 深度估计精度:BEVDet 的 View Transformer 仅通过下游检测 loss 间接学习深度分布,无显式深度监督。与 LiDAR 方法(50.3% mAP)仍有明显差距
- 属性预测:BEVDet 的 AAE(0.247)高于 FCOS3D(0.170),属性(如”停放/行驶”)依赖外观纹理,BEV 特征中外观信息已被抽象
- 输入分辨率敏感性:从 704×256 到 1408×512,mAP 提升 +4.5%(31.2→35.7),但计算量从 215.3 增至 824.6 GFLOPs
5.4 失效场景分析
- BEV 空间小物体:行人和交通锥的 BEV 投影面积可能小于一个 grid cell(如 0.8m 分辨率),Scale-NMS 缓解但未根本解决
- 远距离深度歧义:无显式深度监督的情况下,远处物体的深度预测不确定性大,导致 BEV 空间的定位不准
- 属性预测弱:依赖外观线索的属性(如车辆是否停放)在 BEV 抽象特征中丢失,论文指出需结合图像视图信息
工程实践
6.1 训练配置
Backbone: SwinTransformer-Tiny (BEVDet-Tiny) / SwinT-Base (BEVDet-Base) |
6.2 复现要点
- BDA 是性能基础:没有 BEV 数据增强,模型会严重过拟合,mAP 可能只有 17~23%。BDA 对 BEV Encoder 和 Head 的正则化效果不可替代
- IDA 需要与 BDA 配合:单独使用 IDA 可能反而降低性能(消融实验 B vs. A),只有在 BDA 存在时 IDA 才正向贡献
- Scale-NMS 超参数搜索:缩放因子是类别特定的,需要在验证集上搜索。对行人和交通锥等小物体尤其关键
- 加速推理:将 cumulative sum 操作替换为辅助索引 + 矩阵 sum(预计算模式下),推理延迟从 137ms 降至 64ms(-53.3%)
- 深度范围扩展:BEVDet 将 LSS 原始的 4
45m 扩展到 160m,使用 $\Delta d = 1.25 \times r$($r$ 为 BEV 分辨率),增大了深度覆盖范围 - CBGS 采样:类别均衡采样策略对长尾分布的 10 类检测至关重要
6.3 性能优化方向
精度提升:
- 显式深度监督 + Camera-Aware:BEVDepth 利用 LiDAR 投影深度 + 相机内参 SE 编码显著提升定位精度(同配置 NDS +14.8)
- 时序融合:BEVDet4D 引入历史帧 BEV 特征对齐和融合,获取运动信息和深度线索
速度优化 / 部署优化(BEVPool 系列演进):
BEVDet 系列在部署优化方面经历了三代 BEV Pooling 实现的演进:
| 版本 | 实现方式 | 瓶颈 | 速度 (640×1760) |
|---|---|---|---|
| LSS 原始 (Cumsum Trick) | 显式构建 $(N,D,H,W,C)$ → 排序 → cumsum | 显存 + 排序开销 | 最慢 |
| BEVFusion BEVPool | 显式构建 $(N,D,H,W,C)$ → 多线程聚合 | 仍需存储完整视锥体特征 | 81 FPS |
| BEVPoolv2 (dev2.0) | 索引间接访问 + 延迟外积 | 几乎无瓶颈 | 1,509 FPS |
BEVPoolv2(arXiv:2211.17111)的核心突破:不显式计算 $(N,D,H,W,C)$ 的视锥体特征张量。取而代之的是预计算两组索引(ranks_depth 指向 depth 分布、ranks_feat 指向 context 特征),在 CUDA kernel 中每个线程通过索引按需读取 $\alpha$ 和 $\mathbf{c}$,实时计算外积并累加到 BEV 网格。
关键性能数据:
- 速度提升:低分辨率 3.1×,高分辨率 15.1×
- 显存节省:低分辨率 94.3%,高分辨率 98.0%
- 640×1600、D=118 配置下视图变换仅 0.82 ms
- TensorRT-FP16 下 BEVDet-R50 达 138.9 FPS
所有几何相关的索引仅依赖相机内外参,可完全离线预计算,推理时作为固定参数零开销输入。这使 LSS 范式在边缘设备上部署成为可能。
研究启示
7.1 可迁移的思想
- 数据增强的解耦分析:当模型中存在解耦不同特征空间的模块时,应分别为各空间设计独立的数据增强策略。这一思想可推广到任何涉及坐标变换的架构(如 NeRF 的世界坐标与像素坐标)
- Scale-NMS 的类别自适应后处理:在 BEV/3D 空间中,不同类别的尺度差异远大于 2D 空间,后处理策略需要类别自适应设计
- 先验结构 vs. 学习结构:BEVDet 表明,使用已知的几何变换(相机投影模型)作为先验结构,再通过数据增强充分训练后续模块,比完全数据驱动的方法更高效
- “索引间接访问”的部署优化:BEVPoolv2 展示的”不存储中间张量、用索引按需访问”方案,是 GPU 算子优化的通用模式
7.2 方法局限
- 无显式深度监督,深度估计精度受限,与 LiDAR 方法差距明显
- 单帧推理缺少时序信息,对速度估计和远距离检测不利
- 属性预测依赖外观信息,BEV 空间的抽象特征对此支持不足
7.3 技术影响
- 确立 BEV 3D 检测范式:BEVDet 是首个系统性地将 LSS 框架应用于 3D 目标检测并达到 SOTA 的工作,直接催生了 BEVDet4D、BEVDepth、BEVStereo 等系列演进;与之并行的 BEVFormer 则走向了 query-based Transformer 路线,两大技术流派的竞争推动了 BEV 感知的快速发展
- BEV 数据增强成为标配:BDA 策略被后续几乎所有 BEV 检测方法采用,成为训练 BEV 模型的标准操作
- 推动 BEV 感知生态:BEVDet 代码库(mmdetection3d 风格)成为 BEV 感知研究的标准 codebase 之一,BEVPoolv2 成为工业部署的标准算子
- 工业量产落地:BEVDet 系列(尤其 dev2.0 分支)被国内多家 OEM 采纳为量产方案的基础,其模块化 + TensorRT 导出 + BEVPoolv2 优化的完整链路成为 BEV 感知部署的参考标准。其中 BEVDet → BEVDepth 的跃升尤其关键——同等 R50 / 256×704 配置下 NDS 从 32.7 到 47.5(+14.8),仅通过补强深度估计环节就实现,证明了 BEVDet 框架的性能天花板不在架构本身而在深度质量
BEVDet 系列演进时间线:
| 版本 | 时间 | 核心贡献 | nuScenes val NDS |
|---|---|---|---|
| BEVDet | 2021.12 | LSS→3D 检测 + BDA + Scale-NMS | 39.2 (Tiny) / 47.2 (Base) |
| BEVDet4D | 2022.03 | 时序 BEV 特征对齐融合 | ~50 |
| BEVDepth | 2022.06 | LiDAR 深度监督 + Camera-Aware DepthNet | ~50+ |
| BEVStereo | 2022.09 | 时序立体深度估计 | ~50+ |
| BEVPoolv2 (dev2.0) | 2022.11 | 部署优化:15.1× 加速 + 98% 显存节省 + TensorRT | 52.3 (4D-R50-Depth-CBGS) |
BEVDet4D:时空 4D 工作空间扩展
论文:BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection(2022.03,同一作者黄俊杰)
BEVDet4D 将 BEVDet 从 spatial-only 3D 工作空间提升到 spatial-temporal 4D 工作空间。核心思路极其简洁:保留前一帧的中间 BEV 特征,经自车运动对齐后与当前帧拼接,其余框架不变。
BEVDet4D 核心改进
改进 1:时序 BEV 特征对齐与融合
BEVDet4D 保留 View Transformer 生成的前一帧 BEV 特征,通过自车运动矩阵对齐后与当前帧拼接。对齐操作的数学表达:
$$\mathcal{F}'(T-1, P^{e(T)}) = \mathcal{F}(T-1, T_{e(T)}^{e(T-1)} P^{e(T)})$$即用自车运动变换矩阵 $T_{e(T)}^{e(T-1)}$ 将当前帧的 BEV 坐标映射回前一帧的特征空间,再通过双线性插值采样。对齐后的特征与当前帧沿通道维拼接,送入 BEV Encoder。
关键设计选择:
- 对齐包含旋转和平移(消融 Tab.3 F vs E:加入旋转对齐后 mAVE 从 0.435 降至 0.376,-13.6%)
- 融合位置在 Extra BEV Encoder 之后(Tab.5 B vs A: mAVE 0.429 vs 0.480)
- BEV 特征太稀疏,石截融合前需额外 BEV Encoder(2 个 ResNet Basic Block)先精炼
改进 2:速度预测简化为位移预测
传统做法直接预测目标的世界坐标系速度 $(v_x, v_y)$,但这需要网络同时学习位置差异和时间因子。BEVDet4D 将学习目标简化为相邻帧的位置偏移(消除时间因子),且通过对齐操作消除自车运动分量,使学习目标仅为目标自身的运动。
消融 Tab.3 验证:
- 无对齐直接拼接(A):NDS 从 39.2% 降至 37.6%,反而恶化
- 仅平移对齐(B):mAVE 从 1.544 降至 1.186(-23.2%)
- 平移对齐 + 位移目标(C):mAVE 急降至 0.479(-59.6%)
- 完整配置 + 时间增强(G):mAVE = 0.328,比 BEVDet-Tiny 降 62.9%
BEVDet4D 主要结果
nuScenes val 集:
| 方法 | Input | mAP | NDS | mAVE | FPS |
|---|---|---|---|---|---|
| BEVDet-Tiny | 704×256 | 0.312 | 0.392 | 0.909 | 15.6 |
| BEVDet4D-Tiny | 704×256 | 0.338 | 0.476 | 0.337 | 15.5 |
| BEVDet-Base | 1600×640 | 0.393 | 0.472 | 0.822 | 1.9 |
| BEVDet4D-Base | 1600×640 | 0.421 | 0.545 | 0.301 | 1.9 |
| BEVFormer | 1600×900 | 0.416 | 0.517 | 0.394 | 1.7 |
nuScenes test 集:
| 方法 | mAP | NDS | mAVE |
|---|---|---|---|
| BEVDet | 0.422 | 0.482 | 0.979 |
| BEVFormer | 0.445 | 0.535 | 0.435 |
| BEVDet4D | 0.451 | 0.569 | 0.301 |
关键发现:
- BEVDet4D-Tiny 以可忽略的额外计算量(+6.7 GFLOPs / +1M 参数)实现 +8.4% NDS,速度几乎不变(15.6→15.5 FPS)
- 速度估计误差降 62.9%(mAVE 0.909→0.337),纯视觉方法首次在速度精度上超越多传感器融合方法 CenterFusion(0.540)
- BEVDet4D-Base 在 test 集达 56.9% NDS(含 TTA),超越 BEVFormer +3.4% NDS