Task: Multi-Camera 3D Object Detection
Method: Explicit Depth Supervision, Camera-Aware DepthNet, Depth Refinement Module
Venue: AAAI
Year: 2023
Paper: https://arxiv.org/abs/2206.10092
Code: https://github.com/Megvii-BaseDetection/BEVDepth
摘要
在基于 Lift-Splat(LSS) 范式的多相机 BEV 3D 检测方法中,深度估计是从 2D 到 3D 空间转换的核心环节,但现有方法对深度学习质量的关注严重不足。本文通过系统性实验揭示了一个关键现象:即使将 BEVDet 等 LSS-based 检测器的学习深度替换为随机深度,mAP 仅下降 3.7%;而替换为 LiDAR 点云真值深度时,mAP 和 NDS 各提升近 20%。这一发现直接指出了 LSS 管线的根本瓶颈——深度估计质量远未达标。
针对此瓶颈,本文提出 BEVDepth,包含三项核心改进:(1)显式深度监督(LiDAR 点云投影 + BCE 损失);(2)Camera-Aware 深度预测(相机内外参通过 MLP + SE 注入 DepthNet);(3)Depth Refinement Module(视锥体特征沿深度轴卷积精炼)。配合 Efficient Voxel Pooling(80× 加速)和多帧融合,BEVDepth 在 nuScenes test 集达到 50.3% mAP / 60.0% NDS,首次将纯相机方法的 NDS 推至 60% 大关。
核心论点:LSS 管线的性能瓶颈不在 BEV 编码或检测头,而在深度估计质量——通过显式 LiDAR 深度监督、相机参数感知和深度精炼机制,BEVDepth 证明”让深度学得更准”是提升纯相机 BEV 3D 检测的最直接路径,为后续 BEVStereo、FB-BEV 等工作奠定了深度优化范式。
问题与动机
2022 年上半年,基于 LSS 范式的 BEV 检测方法(BEVDet、BEVDet4D)虽然框架成熟,但其深度估计环节存在严重缺陷,成为制约性能的核心瓶颈。
| 方法类型 | 代表作 | 核心问题 | nuScenes val (mAP/NDS) |
|---|---|---|---|
| LSS-based 无深度监督 | BEVDet, BEVDet4D | 深度仅由检测 loss 间接监督,质量极差 | 28.2/32.7 (R50, 256×704) |
| Query-based | DETR3D, PETR | 无需显式深度,但缺乏几何约束,mATE 较高 | 30.3/37.4 |
| Attention-based | BEVFormer | 空间注意力隐式编码深度,计算量较大 | 37.5/44.8 |
| LiDAR 方法 | CenterPoint | 天然精确深度,但传感器成本高 | 56.4/64.8 |
核心痛点:LSS 管线中 DepthNet 的深度估计仅依赖检测损失的间接梯度,导致深度不准确、深度模块过拟合、BEV 语义不精确三大缺陷。论文通过“上限实验”定量证明:
| 深度来源 | mAP | mATE | NDS |
|---|---|---|---|
| 学习的深度 (baseline) | 0.282 | 0.768 | 0.327 |
| 随机软深度 (frozen) | 0.245 | 0.838 | 0.290 |
| 随机硬深度 (one-hot, frozen) | 0.176 | 0.922 | 0.224 |
| LiDAR 真值深度 | 0.470 | 0.393 | 0.515 |
学习深度与 GT 深度之间存在 18.8% mAP 的差距,这意味着仅改善深度估计质量就有巨大提升空间。
核心洞察
洞察 1:显式深度监督——从间接梯度到直接监督
传统做法:LSS 框架中 DepthNet 的深度预测 $D^{pred}$ 仅通过最终检测 loss 反向传播获得间接监督。由于检测 loss 到深度模块路径长、梯度稀疏,网络只学会在少数”关键区域”(如物体与地面接触点)预测合理的深度,绝大部分像素的深度估计毫无意义。
本文做法:将 LiDAR 点云投影到图像坐标系生成深度真值 $D^{gt}$,对 DepthNet 施加显式 Binary Cross Entropy 损失:
$$P_i^{img}(u \cdot d, v \cdot d, d) = K_i(R_i P + t_i)$$ $$D_i^{gt} = \phi(P_i^{img})$$ $$\mathcal{L}_{depth} = \text{BCE}(D^{pred}_{fg}, D^{gt}_{fg})$$ 其中 $\phi$ 包含 min pooling(处理遮挡)和 one-hot 编码(离散化),$fg$ 表示前景掩码(过滤无效像素)。最终总损失为 $\mathcal{L} = \mathcal{L}_{det} + 3.0 \cdot \mathcal{L}_{depth}$。为什么更好:显式监督迫使所有前景像素都学习合理的深度分布,而非仅依赖检测 loss 关注的少数点。
洞察 2:Camera-Aware 深度预测——让 DepthNet 感知”用什么相机在哪拍的”
传统做法:DepthNet 仅以图像特征为输入,对不同相机的内参(焦距、主点)和外参(安装位置、朝向)一视同仁。但在 nuScenes 等数据集中,6 个相机的 FOV 和安装位置各不相同,同一网络不知道当前特征来自哪个相机——这导致深度模块对相机参数变化极为敏感,泛化能力差。
本文做法:构建 27 维相机参数向量,通过 MLP 升维后以 SE(Squeeze-and-Excitation)机制重标定图像特征:
$$D_i^{pred} = \psi\bigl(SE(F_i^{2d} \mid MLP(\xi(R_i) \oplus \xi(t_i) \oplus \xi(K_i)))\bigr)$$27 维输入包含:4 维内参($f_x, f_y, c_x, c_y$)+ 6 维 IDA 矩阵参数 + 5 维 BDA 矩阵参数 + 12 维 sensor2ego 外参。
为什么更好:Camera-Aware 机制使 DepthNet 能够根据每个相机的几何配置自适应地调整深度预测策略。例如,前视相机(窄 FOV, 远距离)和侧向相机(宽 FOV, 近距离)需要完全不同的深度分布先验。消融实验显示 Camera-Aware 模块使 mATE 降低 0.041,证明其显著改善了定位精度。
洞察 3:Depth Refinement Module——在视锥体空间精炼深度
传统做法:深度预测与上下文特征做外积后直接进行 Voxel Pooling,即使深度预测有偏差也无任何修正机会。
本文做法:在外积生成 3D 视锥体特征 $F^{3d} \in \mathbb{R}^{C_F \times C_D \times H \times W}$ 后、Voxel Pooling 之前,将其 reshape 为 $[C_F \times H, C_D, W]$ 并在 $C_D \times W$ 平面上堆叠 3×3 卷积层进行精炼。
为什么更好:(1)当深度预测置信度低时,沿深度轴的卷积可以聚合周围深度 bin 的特征,起到”软化”作用;(2)当深度预测有偏差时,只要偏差在卷积感受野内,特征可以被”滑动”到正确位置。消融实验验证:使用 3×1 卷积(仅深度轴交互)即可提升 mAP 0.6%,证明信息沿深度轴的交互是该模块的核心机制。
三个关键数字:
- +18.8% mAP:GT 深度 vs 学习深度的差距,揭示深度估计是 LSS 管线的最大瓶颈
- 60.0% NDS:BEVDepth 在 nuScenes test 集达到的 NDS,首次突破 60% 大关(纯相机方案)
- 80×:Efficient Voxel Pooling 相比 LSS 原始 cumsum trick 的加速比
方法设计
4.1 整体架构
BEVDepth 的核心流程可概括为:
$$\text{Imgs} \xrightarrow{\text{Image Encoder}} F^{2d} \xrightarrow[\text{Camera-Aware}]{\text{DepthNet}} (D^{pred}, C) \xrightarrow{\text{Outer Product}} F^{3d} \xrightarrow{\text{Depth Refine}} F^{3d'} \xrightarrow{\text{Voxel Pooling}} F^{bev} \xrightarrow{\text{BEV Encoder + Head}} \text{3D Boxes}$$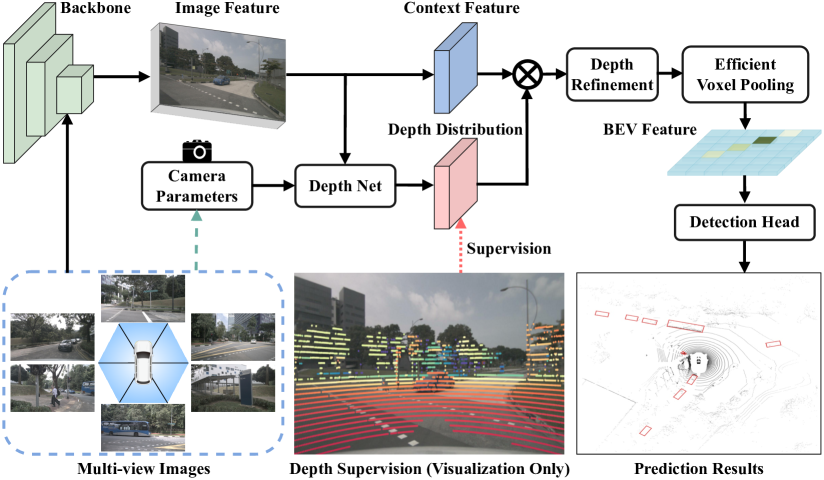
Multi-view Images (6×3×256×704)
│
▼
┌─────────────────────┐
│ Image Encoder │ ResNet-50 + SECONDFPN
│ (Backbone + FPN) │ → 6×512×16×44
└──────────┬──────────┘
│ Camera Params (27-dim)
▼ │
┌─────────────────────┐ ┌───────────┴──────────┐
│ Camera-Aware │◄───│ MLP(27→512) + │
│ DepthNet │ │ SE Reweight │
│ │ └──────────────────────┘
│ ┌───────┬────────┐ │
│ │Depth │Context │ │ Depth: 112ch, Context: 80ch
│ │Branch │Branch │ │ (112 = (58-2)/0.5 depth bins)
│ └───┬───┴────┬───┘ │
└──────┼────────┼─────┘ Depth GT (LiDAR proj.)
│ │ │
│ │ BCE Loss│ ×3.0
▼ ▼ │
D∈R^{112×H×W} C∈R^{80×H×W} │
│ │ │
└───┬────┘ │
Outer Product │
F_3d = D ⊗ C │
│ │
▼ │
┌─────────────────────┐ │
│ Depth Refinement │ 3×3 Conv on (D×W) plane
│ Module │ reshape → refine → reshape
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ Efficient Voxel │ CUDA kernel, 80× faster
│ Pooling │ → BEV Feature (80×128×128)
└──────────┬──────────┘
│ (Multi-frame: concat)
▼
┌─────────────────────┐
│ BEV Encoder │ ResNet-18 + SECONDFPN
│ (Backbone + Neck) │ → 256×128×128
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ CenterPoint Head │ 6 task heads
│ (heatmap, reg, │ → 3D Bounding Boxes
│ dim, rot, vel) │
└─────────────────────┘
4.2 关键组件
| 模块 | 输入 | 输出 | 功能 | 关键设计 |
|---|---|---|---|---|
| Image Encoder | 6×3×256×704 | 6×512×16×44 | 提取多尺度图像特征 | ResNet-50 + SECONDFPN (四尺度) |
| Camera-Aware DepthNet | 特征 + 27维相机参数 | depth(112) + context(80) | 预测深度分布与语义特征 | SE reweight + ASPP + DCN |
| Depth Refinement | ${C_F \times C_D \times H \times W}$ | 同维 | 沿深度轴精炼视锥体特征 | 3×3 Conv on $(C_D, W)$ plane |
| Efficient Voxel Pooling | 视锥体特征 + 几何坐标 | 80×128×128 BEV | 聚合到 BEV 栅格 | 每个特征一个 CUDA thread,原子加 |
| BEV Encoder | 80×128×128 | 256×128×128 | 编码 BEV 语义 | ResNet-18 + SECONDFPN |
| Detection Head | 256×128×128 | 3D boxes | 预测类别/位置/尺寸/朝向/速度 | CenterPoint (6 task heads) |
4.3 关键代码
核心代码来自官方仓库 Megvii-BaseDetection/BEVDepth,以下展示 BEVDepth 的三大关键实现。
| 函数/类 | 文件 | 功能 |
|---|---|---|
DepthNet |
base_lss_fpn.py | Camera-Aware 深度预测网络 |
get_depth_loss + get_downsampled_gt_depth |
base_exp.py | 深度监督损失 + GT 深度生成 |
📄 点击展开 DepthNet(Camera-Aware 深度预测网络)代码
(来源:bevdepth/layers/backbones/base_lss_fpn.py)
class DepthNet(nn.Module): |
📄 点击展开 get_depth_loss + get_downsampled_gt_depth 代码
(来源:bevdepth/exps/nuscenes/base_exp.py)
def get_depth_loss(self, depth_labels, depth_preds): |
实验与分析
5.1 主要结果
nuScenes val 集对比(无 TTA):
| 方法 | Backbone | 分辨率 | mAP | NDS |
|---|---|---|---|---|
| FCOS3D | R101-DCN | 900×1600 | 0.295 | 0.372 |
| DETR3D | R101-DCN | 900×1600 | 0.303 | 0.374 |
| BEVDet-R50 | R50 | 256×704 | 0.286 | 0.372 |
| BEVDet-Tiny | Swin-T | 512×1408 | 0.349 | 0.417 |
| PETR-R50-DCN | R50-DCN | 384×1056 | 0.313 | 0.381 |
| BEVDet4D-Tiny | Swin-T | 256×704 | 0.323 | 0.453 |
| BEVFormer-S | R101-DCN | — | 0.375 | 0.448 |
| BEVFormer | R101-DCN | 900×1600 | 0.416 | 0.517 |
| BEVDepth-R50 | R50 | 256×704 | 0.351 | 0.475 |
| BEVDepth-R101 | R101 | 512×1408 | 0.412 | 0.535 |
| BEVDepth-R101-DCN | R101-DCN | 512×1408 | 0.418 | 0.538 |
nuScenes test 集对比:
| 方法 | Modality | mAP | mATE↓ | mASE↓ | mAOE↓ | mAVE↓ | mAAE↓ | NDS |
|---|---|---|---|---|---|---|---|---|
| CenterPoint | LiDAR | 0.564 | — | — | — | — | — | 0.648 |
| FCOS3D | Camera | 0.358 | 0.690 | 0.249 | 0.452 | 1.434 | 0.124 | 0.428 |
| BEVDet4D | Camera | 0.451 | 0.511 | 0.241 | 0.386 | 0.301 | 0.121 | 0.569 |
| BEVFormer | Camera | 0.481 | 0.582 | 0.256 | 0.375 | 0.378 | 0.126 | 0.569 |
| PETRv2 | Camera | 0.490 | 0.561 | 0.243 | 0.361 | 0.343 | 0.120 | 0.582 |
| BEVDepth | Camera | 0.503 | 0.445 | 0.245 | 0.378 | 0.320 | 0.126 | 0.600 |
| BEVDepth† | Camera | 0.520 | 0.445 | 0.243 | 0.352 | 0.347 | 0.127 | 0.609 |
BEVDepth 使用 VoVNet backbone,640×1600 分辨率。BEVDepth† 使用 ConvNeXT backbone。
关键发现:mATE 仅 0.445(比 PETRv2 低 11.6%),直接受益于显式深度监督;首个纯相机方案突破 NDS 60%;BEVDepth-R50 (256×704) 即达 35.1/47.5,超越大分辨率的 BEVDet-Tiny 和 BEVFormer-S。
5.2 消融实验:验证三个洞察
组件逐步累加消融(R50, 256×704, nuScenes val):
| DL | CA | DR | MF | mAP | mATE↓ | mAOE↓ | NDS | 验证洞察 |
|---|---|---|---|---|---|---|---|---|
| 0.282 | 0.768 | 0.698 | 0.327 | baseline | ||||
| ✓ | 0.304 | 0.747 | 0.671 | 0.344 | 洞察 1 | |||
| ✓ | ✓ | 0.314 | 0.706 | 0.647 | 0.357 | 洞察 2 | ||
| ✓ | ✓ | ✓ | 0.322 | 0.707 | 0.636 | 0.367 | 洞察 3 | |
| ✓ | ✓ | ✓ | ✓ | 0.330 | 0.699 | 0.545 | 0.442 | +多帧 |
DL = Depth Loss, CA = Camera-Awareness, DR = Depth Refinement, MF = Multi-Frame
- **洞察 1 (Depth Loss)**:+2.2% mAP,验证显式深度监督改善分类能力
- **洞察 2 (Camera-Aware)**:mATE 降低 0.041,验证相机参数感知改善定位精度
- **洞察 3 (Depth Refinement)**:+0.8% mAP,验证深度轴特征交互的精炼效果
- 全部累加:+4.0% mAP / +4.0% NDS,各组件贡献正交叠加
Depth Refinement 卷积核消融:
| 卷积核 | mAP | mATE↓ | mAOE↓ | NDS |
|---|---|---|---|---|
| 无 | 0.314 | 0.706 | 0.647 | 0.357 |
| 1×3 (仅水平) | 0.315 | 0.703 | 0.650 | 0.357 |
| 3×1 (仅深度轴) | 0.320 | 0.695 | 0.624 | 0.369 |
| 3×3 | 0.322 | 0.707 | 0.636 | 0.367 |
3×1 与 3×3 性能相当,证明信息沿深度轴交互才是核心。
深度质量定量评估(nuScenes val, 所有前景像素):
| 指标 | Base Detector | + Depth Loss |
|---|---|---|
| SILog | 54.58 | 27.62 |
| Abs Rel | 3.03 | 0.23 |
| Sq Rel | 85.11 | 2.09 |
| RMSE | 19.45 | 5.78 |
加入深度监督后 Abs Rel 从 3.03 降至 0.23,深度质量提升超过一个数量级。
5.3 性能瓶颈与失效场景
- 深度估计仍未饱和:GT 深度上限为 47.0% mAP / 51.5% NDS,BEVDepth(单帧)为 32.2% / 36.7%,仍存在约 15% mAP 提升空间
- 远距离深度退化:LiDAR 点云在远距离更稀疏,监督信号变弱;遮挡区域无 LiDAR 真值,深度仍依赖间接信号
- 图像尺寸敏感:论文 Fig. 2 显示测试分辨率与训练不一致时性能下降,BEVDepth 比 Base Detector 鲁棒但仍有衰减
- 纯背景区域:前景掩码之外的像素不参与深度损失,这些区域的深度预测仍不可靠
工程实践
6.1 训练配置
Backbone: ResNet-50 (frozen_stages=0, pretrained=torchvision) |
6.2 复现要点
- 深度真值生成:LiDAR 投影后做 min pooling(16×16 取最小值处理遮挡),无效区域用 1e5 填充后取 min,再 one-hot 离散化到 112 bins
- 深度损失 fp32:混合精度训练时必须在深度 loss 计算处关闭 autocast,否则训练崩溃
- 27 维相机参数拼接顺序:需从
intrin_mats,ida_mats,bda_mat,sensor2ego_mats四个矩阵中提取特定元素,顺序不能错 - 深度损失权重 3.0:BCE 和 L1 Loss 差异不大(Table 5),但 3.0 系数是硬编码的关键超参
- EMA 注意事项:ckpt 保存原始参数而非 EMA 参数,且不支持断点续训
6.3 性能优化方向
精度提升:
- 更强的深度监督信号:可引入时序立体匹配(BEVStereo 的思路),在多帧间构建 cost volume 辅助深度估计,代价是增加时序计算量
- 更大分辨率 + 更强 backbone:R50 → ConvNeXT 在 test 集上 mAP 从 50.3% 升至 52.0%,但 FLOPs 成倍增加
- 深度监督扩展到背景区域:当前仅监督前景像素,可探索稀疏深度补全或自监督方式扩展监督范围
速度优化:
- Efficient Voxel Pooling:已将 Pooling 加速 80 倍(从 LSS 的 5 天训练缩短到 1.5 天),是论文的重要工程贡献
- 推理时跳过 Depth Refinement:论文代码中训练/推理使用不同的
_forward_single_sweep路径——推理时通过voxel_pooling_inference直接处理 depth 和 feature,避免显式构建 $C_F \times C_D \times H \times W$ 的视锥体张量,显著减少显存和计算量
研究启示
7.1 可迁移的思想
- “中间监督”解决端到端训练的梯度稀疏问题:当端到端训练中某一中间模块(如深度估计)的梯度来源太少时,引入中间监督是最直接有效的改善方式。这一思想可迁移到任何多级管线中——例如在 3D 占用网络中对体素密度施加中间监督
- 将传感器参数编码为网络条件输入:Camera-Aware 机制本质上是让网络”知道自己在用什么设备看什么方向”。同样的思路可用于多雷达融合(编码雷达安装参数)、跨数据集迁移(编码不同车型的相机配置差异)
- 几何空间中的特征精炼:在 3D 空间/视锥体空间对特征做卷积精炼,而非在 2D 图像空间。这个思路也提示后续方法,可以在 BEV 特征上做类似的”深度方向精炼”操作
7.2 方法局限
- 依赖 LiDAR 数据生成深度真值:训练阶段必须有 LiDAR 点云数据,无法在纯视觉数据集上使用。虽然推理不需要 LiDAR,但这限制了数据扩展性
- 远距离/稀疏区域深度监督退化:LiDAR 点云密度随距离衰减,远距离目标的深度真值稀疏且噪声较大,监督效果受限
- 深度离散化的精度上界:bin size = 0.5m 的离散深度标签本身引入了量化误差,对远距离目标(深度 > 50m)的相对精度下降
7.3 技术影响
- 奠定了 LSS 管线的深度优化范式:BEVDepth 首次系统性地证明”深度估计质量是 LSS 管线的核心瓶颈”,后续 BEVStereo(时序立体深度)、FB-BEV(前后向投影互补深度)等工作均以此为基础展开
- NDS 60% 里程碑:首个纯相机方案突破 nuScenes NDS 60%,大幅缩小了与 LiDAR 方法(CenterPoint 64.8%)的差距,推动了工业界对纯视觉 BEV 方案的信心
- Efficient Voxel Pooling 推动工程落地:80 倍 Pooling 加速使 BEV 方案的训练从”一周级”降到”两天级”,后续被 BEVDet、BEVFusion 等工作广泛复用
- Camera-Aware 设计成为标配:在 BEVDepth 之后,几乎所有 LSS-based 方法都采纳了将相机参数注入 DepthNet 的设计,成为该方向的标准实践
- 从 BEVDet 到 BEVDepth,量化了“深度补强”的价值:同配置(R50, 256×704)NDS 从 32.7 到 47.5(+14.8),仅通过补强深度环节实现,使“点云老师教视觉学生看深度”的显式监督思路成为工业界标配