Task: BEV Semantic Segmentation / Motion Planning
Method: Latent Depth Distribution, Frustum Pooling, Cost Map Planning
Venue: ECCV
Year: 2020
Paper: https://arxiv.org/abs/2008.05711
Code: https://github.com/nv-tlabs/lift-splat-shoot
摘要
自动驾驶感知系统的目标是从多个传感器中提取语义表示,并将其融合到统一的鸟瞰图(BEV)坐标系中供运动规划使用。本文提出了一种端到端架构 Lift-Splat-Shoot (LSS),能够从任意数量摄像头的图像数据中直接提取 BEV 表示。该方法的核心思路分三步:Lift——为每张图像的每个像素预测一个离散深度分布,将 2D 特征”提升”为视锥体形状的 3D 点云;Splat——利用相机内外参将所有视锥体”投射”到统一的 BEV 栅格上,通过 Pillar Pooling 进行聚合;Shoot——在 BEV 代价图上”射出”模板轨迹进行可解释的端到端运动规划。在 nuScenes 和 Lyft 数据集上的物体分割与地图分割任务中,LSS 超越了所有基线和同期工作。此外,该模型展现出了对标定误差和传感器失效的鲁棒性,以及跨相机配置的零样本迁移能力。
核心论点:多视图 BEV 感知的关键在于如何将 2D 图像特征”升维”到 3D 空间并融合——LSS 通过为每个像素预测隐式深度分布,以外积方式生成视锥体特征,开创了”Lift-Splat”这一从图像到 BEV 的通用转换范式,成为后续 BEVDet、BEVDepth、BEVFusion 等一系列 BEV 感知方法的基础。
问题与动机
自动驾驶感知系统需要将多相机图像融合到 BEV 坐标系中进行下游规划。现有方案面临核心挑战:如何从 2D 图像空间变换到 3D/BEV 空间。
| 方法类型 | 代表作 | 核心问题 | 特点 |
|---|---|---|---|
| 单目检测 + 后处理 | SSD-6D, MonoGRNet | 不可端到端微分,无法学习跨视图融合 | 逐视图独立检测再拼接 |
| Pseudo-LiDAR | PseudoLiDAR, PL++ | 需独立训练深度网络,误差传播 | 两阶段:深度估计 + BEV 检测 |
| 3D 体素投影 | OFT | 像素对所有体素贡献相同特征,未建模深度 | 固定体素投影 |
| BEV 直接推理 | MonoLayout, PON | 未利用几何先验,性能受限 | 直接学习图像到 BEV 映射 |
传统的单目检测融合方案虽然具有三个良好的对称性(平移等变性、排列不变性、自身坐标等距等变性),但由于使用后处理检测结果拼接,无法端到端训练,也无法学习最优的跨视图融合策略。OFT 虽然利用了相机几何,但一个像素对所有深度的体素贡献完全相同的特征,无法区分深度信息。
核心痛点:如何设计一个既保持几何对称性、又端到端可微分的架构,使模型能够从数据中学习最优的跨视图融合方式,同时对深度不确定性进行显式建模。
核心洞察
洞察 1:隐式深度分布——用概率建模替代确定性深度估计
单目深度估计存在固有歧义:同一像素可能对应多个深度值。传统方法要么忽略深度(OFT 对所有深度均匀分配特征),要么做确定性深度预测(PseudoLiDAR 预测一个深度值)。LSS 提出了一种折中方案:为每个像素预测一个离散深度分布 $\alpha \in \Delta^{|D|-1}$ 和一个上下文向量 $\mathbf{c} \in \mathbb{R}^C$,通过外积生成每个深度上的特征。
OFT 做法:像素特征不加区分地复制到所有深度位置(等价于 $\alpha$ 为均匀分布)
PseudoLiDAR 做法:预测单一确定性深度,特征仅存在于一个位置(等价于 $\alpha$ 为 one-hot 向量)
LSS 做法:预测连续的深度分布 $\alpha$,特征按概率分配到各深度位置
核心公式:
$$\mathbf{c}_d = \alpha_d \cdot \mathbf{c}$$其中 $\mathbf{c}_d \in \mathbb{R}^C$ 是像素 $p$ 在深度 $d$ 处的特征,$\alpha_d$ 是深度为 $d$ 的概率。
为什么更优:网络可以自适应地选择:对深度确定的区域(如地面)输出尖锐分布集中特征;对深度模糊的区域(如远处物体)输出平滑分布扩散特征。这一机制统一了”确定性深度”和”均匀分配”两种极端策略。
算子层面的设计选择:外积运算 depth_prob.unsqueeze(1) * image_feat.unsqueeze(2) 是纯粹的 broadcast + elementwise multiply,刻意避开了 F.grid_sample。原因在于:若对全分辨率特征图做 $D$ 次连续坐标插值采样($H \times W \times D$ 个采样点),grid_sample 的双线性插值会产生大量随机内存访问(non-coalesced access),cache 命中率极低;而 broadcast 是连续内存的规则 tensor 运算,GPU warp 利用率远高。这一取舍是 LSS 能以 35 Hz 运行的关键原因之一。
洞察 2:Pillar Pooling + Cumsum Trick——高效的视锥体到 BEV 转换
将每个像素提升到 $|D|$ 个深度点后,$n$ 个相机共生成 $n \times D \times H \times W$ 个 3D 点。如何将如此大规模的稀疏点云高效聚合到 BEV 栅格上是关键的工程挑战。
传统做法:对每个 pillar 分别收集落入的点,需要 padding 和变长索引操作
LSS 做法:借鉴 PointPillars,将所有点按照 pillar 编号排序,利用 cumulative sum 技巧实现零填充的 sum pooling
从 PyTorch 算子角度看,Splat 本质上是 voxel pooling(体素池化):将不规则分布的视锥体点离散聚合到规则 BEV 网格,等价于 torch.scatter_add。QuickCumsum 是 scatter_add 的高效替代实现——通过排序 + 累积求和 + 差分避免了 scatter 的原子操作竞争,在 CUDA 上更快。后续 BEVFusion 的 QuickCumsumCuda 进一步将 voxelization + pooling 融合为单一 kernel。
具体步骤:
- 将所有 3D 点映射到对应的 pillar(无限高度的体素)
- 按 pillar ID 排序所有点
- 对排序后的特征做累积求和
- 在 pillar 边界处做差值即得到每个 pillar 的聚合特征
为什么更优:避免了 padding 带来的额外内存开销,且累积求和有解析梯度,训练速度提升 2 倍。这使得在完整 6 相机输入上训练大规模模型成为可能。
洞察 3:端到端几何感知架构——三大对称性保持
LSS 架构在设计上天然保持了三个关键对称性,而不需要任何后处理:
- 平移等变性:图像内像素坐标平移 → 输出对应平移(来自全卷积设计)
- 排列不变性:$n$ 个相机的输入顺序不影响最终输出(Splat 操作是 sum pooling)
- 自身坐标等距等变性:同一场景在不同自车位姿下,检测结果随之刚体变换(通过内外参显式变换坐标)
传统的 CNN baseline 将所有相机特征直接拼接后上采样到 BEV,破坏了排列不变性和等距等变性。实验表明,这种缺乏几何归纳偏置的 baseline 性能远低于 LSS(nuScenes 车辆分割 IoU 仅 24.25% vs. 32.07%)。
三个关键数字:
- **32.07%**:nuScenes 车辆分割 IoU,超越所有基线和同期工作
- 35 Hz:Titan V GPU 上的前向推理速度,满足自动驾驶实时性需求
- 14.3M:模型总参数量,轻量级设计
方法设计
4.1 整体架构
给定 $n$ 张图像 ${X_k \in \mathbb{R}^{3 \times H \times W}}^n$ 及其对应的外参 $E_k \in \mathbb{R}^{3 \times 4}$ 和内参 $I_k \in \mathbb{R}^{3 \times 3}$,模型输出 BEV 表示 $\mathbf{y} \in \mathbb{R}^{C \times X \times Y}$:
$$\text{Images} \xrightarrow{\text{Lift}} \text{Frustum Point Cloud} \xrightarrow{\text{Splat}} \text{BEV Grid} \xrightarrow{\text{BEV CNN}} \text{Segmentation / Cost Map}$$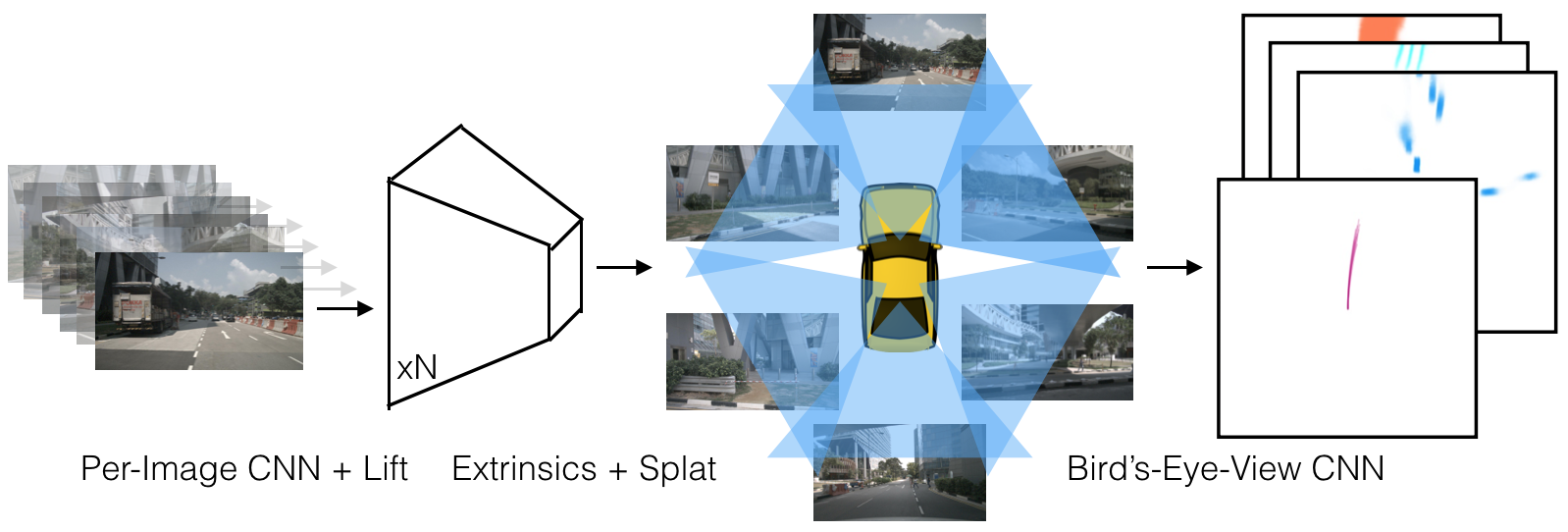
输入:n 张图像 (128×352) + 内参 I + 外参 E
│
▼
┌─────────────────────────────┐
│ EfficientNet-B0 Backbone │ 逐图像独立处理
│ + Up(320+112 → 512) │
└──────────────┬──────────────┘
│ 特征图 (8×22×512)
▼
┌─────────────────────────────┐
│ Depth Net (Conv 1×1) │ 输出 D+C = 41+64 = 105 通道
│ → α ∈ ℝ^D (softmax) │ 深度分布
│ → c ∈ ℝ^C │ 上下文向量
└──────────────┬──────────────┘
│ 外积: c_d = α_d · c
▼
┌─────────────────────────────┐
│ Frustum Point Cloud │ n × D × H × W × C
│ 坐标变换 (I, E) → ego frame │
└──────────────┬──────────────┘
│ 按 pillar 排序 + cumsum trick
▼
┌─────────────────────────────┐
│ BEV Pseudo Image │ C × 200 × 200
│ (200×200, 0.5m/pixel) │ [-50m, 50m] × [-50m, 50m]
└──────────────┬──────────────┘
│
▼
┌─────────────────────────────┐
│ BEV Encoder (ResNet-18) │ Conv7s2 → layer1 → layer2 → layer3
│ + Multi-scale Upsample │ Up(64+256→256, ×4) → Up(256→128→outC, ×2)
└──────────────┬──────────────┘
│
▼
BEV Segmentation Map
或 Cost Map (用于规划)
4.2 关键组件
| 组件 | 输出尺寸 | 功能 | 备注 |
|---|---|---|---|
| CamEncode | (B×N) × 105 × 8 × 22 | 提取图像特征 + 预测深度分布和上下文 | EfficientNet-B0 + 1×1Conv |
| Depth Head | D=41 通道 | 预测 4.0m~45.0m 离散深度概率 | Softmax 归一化 |
| Context Head | C=64 通道 | 提取上下文语义特征 | 与深度分布外积 |
| Frustum Pooling | C × 200 × 200 | 视锥体点云 → BEV 栅格聚合 | Cumsum trick, 2× 加速 |
| BevEncode | outC × 200 × 200 | BEV 特征提取 + 多尺度融合 | ResNet-18 前 3 层 + FPN |
损失函数:
物体分割和可行驶区域使用带正样本权重的二值交叉熵损失:
$$\mathcal{L} = \text{BCEWithLogitsLoss}(\hat{y}, y; w_{pos})$$其中车辆分割和可行驶区域分割的 $w_{pos} = 1.0$,车道线分割的 $w_{pos} = 5.0$。
运动规划使用 Boltzmann 分布形式的交叉熵损失:
$$p(\tau_i | o) = \frac{\exp(-\sum_{x_i, y_i \in \tau_i} c_o(x_i, y_i))}{\sum_{\tau \in \mathcal{T}} \exp(-\sum_{x_i, y_i \in \tau} c_o(x_i, y_i))}$$其中 $c_o(x, y)$ 为 BEV 代价图上 $(x, y)$ 处的代价值,$\mathcal{T}$ 为 K-Means 聚类得到的 $K=1000$ 条模板轨迹。
4.3 关键代码
| 函数 / 类 | 任务 |
|---|---|
CamEncode |
图像特征提取 + 深度分布/上下文预测 |
LiftSplatShoot.create_frustum |
构建视锥体网格坐标 |
LiftSplatShoot.get_geometry |
将视锥体坐标变换到 ego 坐标系 |
LiftSplatShoot.voxel_pooling |
Frustum Pooling(含 cumsum trick) |
QuickCumsum |
自定义 autograd 的高效累积求和 |
BevEncode |
BEV 特征编码器 |
📄 点击展开 CamEncode 代码
(来源:src/models.py)
class CamEncode(nn.Module): |
📄 点击展开 QuickCumsum(Frustum Pooling 核心)代码
(来源:src/tools.py)
class QuickCumsum(torch.autograd.Function): |
📄 点击展开 voxel_pooling 代码
(来源:src/models.py)
def voxel_pooling(self, geom_feats, x): |
实验与分析
5.1 主要结果
物体分割(IoU %):
| 方法 | nuScenes Car | nuScenes Vehicle | Lyft Car | Lyft Vehicle |
|---|---|---|---|---|
| CNN Baseline | 22.78 | 24.25 | 30.71 | 31.91 |
| Frozen Encoder | 25.51 | 26.83 | 35.28 | 32.42 |
| OFT | 29.72 | 30.05 | 39.48 | 40.43 |
| Lift-Splat | 32.06 | 32.07 | 43.09 | 44.64 |
| PON* | 24.7 | - | - | - |
| FISHING Net* | - | 30.0 | - | 56.0 |
地图分割(IoU %):
| 方法 | Drivable Area | Lane Boundary |
|---|---|---|
| CNN Baseline | 68.96 | 16.51 |
| Frozen Encoder | 61.62 | 16.95 |
| OFT | 71.69 | 18.07 |
| Lift-Splat | 72.94 | 19.96 |
| PON* | 60.4 | - |
注:PON 和 FISHING Net 使用不同的 BEV 网格定义和验证集划分,非严格对齐对比。
关键发现:
- LSS 在所有 4 个物体分割任务和 2 个地图分割任务上全面超越基线
- 相比无几何先验的 CNN baseline,LSS 在车辆分割上提升近 10 个百分点(24.25→32.07),证明显式建模 3D 几何结构的重要性
- 相比 OFT(不做深度区分),LSS 的深度分布建模带来约 2% 的额外提升
5.2 消融实验:验证三个洞察
| 配置 | nuScenes Vehicle IoU | 验证洞察 |
|---|---|---|
| CNN Baseline(无几何先验) | 24.25 | 洞察 3 |
| Frozen Encoder(深度隐式学习受限) | 26.83 | 洞察 1 |
| OFT(均匀深度分布) | 30.05 | 洞察 1 |
| Lift-Splat(学习深度分布) | 32.07 | 洞察 1 + 2 + 3 |
| 训练时 Sensor Dropout(随机丢 1 相机) | 最优性能(6 相机全在时) | 洞察 3 |
| 训练时加外参噪声 | 对高噪声更鲁棒 | 洞察 3 |
注:CNN baseline 直接将所有相机特征拼接上采样到 BEV;Frozen Encoder 冻结 EfficientNet-B0 的预训练权重。
- 洞察 1 验证:OFT(30.05)vs. Lift-Splat(32.07),学习深度分布优于均匀分配
- 洞察 2 验证:Lift-Splat 的高效实现使得在 6 相机 × 41 深度点 × 8×22 特征图的规模上端到端训练成为可能,模型以 35 Hz 运行
- 洞察 3 验证:CNN baseline(24.25)远低于 Lift-Splat(32.07),说明几何归纳偏置至关重要
5.3 性能瓶颈分析
与 Oracle Depth(LiDAR)对比:
| 方法 | Drivable Area | Lane | nuScenes Car | nuScenes Vehicle |
|---|---|---|---|---|
| Oracle Depth (1 sweep) | 74.91 | 25.12 | 40.26 | 44.48 |
| Oracle Depth (>1 sweep) | 76.96 | 26.80 | 45.36 | 49.51 |
| Lift-Splat | 70.81 | 19.58 | 32.06 | 32.07 |
主要性能差距来源:
- 深度估计精度:单帧图像的隐式深度分布远不如 LiDAR 点云提供的真实深度
- 远距离衰减:两种方法性能均随距离线性下降,但 LSS 衰减更快
- 夜间场景:LSS 在夜间性能显著下降,而 LiDAR 不受光照影响
提升空间明确在于深度估计的质量——未来需要多帧时序信息来接近或超越 LiDAR 的深度精度。
5.4 失效场景分析
- 夜间场景:图像质量大幅下降导致深度估计和语义理解同时恶化,性能相对 LiDAR 差距最大
- 远距离物体:单目深度歧义随距离增大而加剧,远处车辆分割 IoU 明显低于 LiDAR baseline
- 相机失效/遮挡区域:当缺失某个相机时,对应覆盖区域的预测变得模糊;后视相机(更宽视角)缺失时性能下降最大
- 单帧运动推理:没有时序信息,模型无法准确判断物体运动状态和速度,限制了规划性能(Top-5 规划准确率 15.52% vs. LiDAR 1-sweep 19.27%)
工程实践
6.1 训练配置
Backbone: EfficientNet-B0(ImageNet 预训练) |
6.2 复现要点
- 输入预处理:图像裁剪到 128×352 后必须相应调整内参(焦距和主点)和外参,否则投影关系错误
- 深度离散化范围:4.0m~45.0m 间隔 1.0m 共 41 个 bin,过小的 step 会显著增加内存消耗(点云规模 = $n \times D \times H/16 \times W/16$)
- Frustum Pooling 实现:必须使用
QuickCumsum(含自定义 backward)而非 autograd 默认梯度,否则训练速度减半 - 正样本权重:车道线分割的 pos_weight=5.0 对平衡极度不均衡的正负样本至关重要
- Sensor Dropout 训练策略:训练时随机丢弃 1 个相机可提升模型在完整输入下的性能(类似 Dropout 正则化效果)
- BEV 网格 Z 轴:虽然生成 3D 体素,但最终通过沿 Z 轴 concatenate 展平为 2D BEV 伪图像,Z 轴分辨率不需要太高
6.3 性能优化方向
精度提升:
- 时序融合:引入多帧图像,通过时序信息提升深度估计精度(论文结论明确指出这是未来方向)
- 深度监督:利用 LiDAR 投影深度对深度分布进行显式监督(后续 BEVDepth 已验证有效)
- 更高分辨率 BEV 网格:增大 BEV 分辨率可提升小物体检测,但会增加 Frustum Pooling 的计算量
速度优化:
- 特征图下采样:增大 downsample 比例减少点云规模,但会损失空间分辨率
- 深度 bin 数量:减少离散深度数量可线性降低计算量,但损失深度精度
- BEV Encoder 轻量化:使用更轻量的 BEV 网络(如 MobileNet 替代 ResNet-18),训练和推理均加速
- BEVPoolv2 算子优化:通过索引间接访问替代显式外积存储,避免计算和缓存完整的 $(N,D,H,W,C)$ 视锥体特征张量,速度可提升 3.1×
15.1×,显存降至原先的 2%5.7%(详见 BEVDet 系列论文笔记)
研究启示
7.1 可迁移的思想
- “Lift-Splat” 范式:将任意 2D 传感器特征通过深度分布提升到 3D 再投射到 BEV 的流程,已成为多视图 BEV 感知的标准方案,被 BEVDet、BEVDepth、BEVFusion、BEVFormer 等大量后续工作采用
- 隐式深度分布建模:用 softmax 将深度概率分布与上下文特征外积的思想,可推广到任何需要处理深度不确定性的任务(如 3D 语义分割、占据栅格预测)
- Cumsum Trick:基于排序的 scatter_add 替代方案(参见洞察 2),不仅适用于 pillar pooling,也可用于其他需要对稀疏数据按组求和的场景(如点云分割中的 voxel 特征聚合)
- 几何归纳偏置:在模型中显式嵌入已知的物理/几何约束(如相机投影模型),比让网络从数据中隐式学习更高效、更可泛化
7.2 方法局限
- 单帧推理缺少时序信息,深度估计精度有限,与 LiDAR 仍有明显差距
- 深度分布无显式监督信号,完全依赖下游任务反向传播间接学习
- Dense Lift 的空体素问题:每个像素按 $D$ 个 depth bin 展开后,$H \times W \times D$ 的视锥体中绝大多数体素概率接近 0(每个像素真实深度只有一个),带来显存浪费和计算冗余,后续 Sparse4D 等稀疏方案正是为解决这一问题而生
- BEV 表示为固定范围栅格(100m×100m),难以高效处理更大范围或更精细分辨率的需求
7.3 技术影响
- 开创 BEV 感知范式:LSS 是首个提出完整的”图像→视锥体→BEV”端到端流程的工作,直接催生了 BEVDet(2021)、BEVDepth(2022)、BEVFusion(2022)等显式深度路线,同时也启发了 BEVFormer(2022)等 query-based 路线,进而演化出 Sparse4D(2022)等 sparse query 方法——两条路线共同构成了当前 BEV 感知的技术版图
- 推动纯视觉自动驾驶方案:证明了不依赖 LiDAR 进行 BEV 感知的可行性,对降低自动驾驶硬件成本具有重要意义(Tesla 纯视觉方案的理论基础之一)
- Frustum Pooling 工程实践:QuickCumsum(scatter_add 的高效替代,参见洞察 2)及其 CUDA 实现被广泛复用,成为 BEV 感知 codebase 的标准组件
- 引发 BEV 深度估计研究:LSS 暴露的深度估计瓶颈直接催生了 BEVDepth(LiDAR 深度监督)、STS(时空立体匹配)等一系列改进工作
- 工业界偏好 LSS 范式:尽管 dense lift 产生大量空体素,但全流程均为连续内存的 dense tensor 计算(参见洞察 1),GPU 利用率高、TensorRT 易量化、延迟稳定;静态计算图利于 GPU/NPU 算子融合,BEVPoolv2 等工程优化进一步抵消空体素开销。相比之下,BEVFormer 的 query-driven attention 是 memory-bound 的随机访存,落地困难得多。因此 LSS 仍是 Tesla、NVIDIA 及国内多家 OEM 量产方案的主流架构——算得多但算得规整,比算得少但算得零散更适合 GPU