Task: Multi-Sensor 3D Object Detection / BEV Map Segmentation
Method: BEV-Level Fusion, Efficient BEV Pooling, Fully-Convolutional Fusion, Multi-Task Heads
Venue: ICRA
Year: 2023
Paper: https://arxiv.org/abs/2205.13542
Code: https://github.com/mit-han-lab/bevfusion
摘要
多传感器融合是自动驾驶感知系统的核心。现有方法几乎全部基于点级融合(Point-Level Fusion):将图像特征投射到 LiDAR 点云上进行装饰(PointPainting、MVP、DeepFusion 等)。然而,Camera-to-LiDAR 投影丢弃了图像特征的语义密度——对于 32 线 LiDAR,仅约 5% 的图像特征能匹配到 LiDAR 点,其余全部丢弃。这使得点级融合在语义导向任务(如 BEV 地图分割)上几乎失效。
本文提出 BEVFusion,将多模态特征统一到共享 BEV 表示空间中进行融合,同时保留 LiDAR 的几何结构和相机的语义密度。核心技术贡献是诊断并解决了 Camera-to-BEV 视图变换的效率瓶颈——原始 BEV Pooling 耗时超过 500ms(占模型推理的 80%+)。通过预计算(Precomputation)和区间归约(Interval Reduction)两项优化,将 BEV Pooling 延迟从 500ms 降至 12ms,实现 40× 加速。融合后的 BEV 特征经卷积编码器处理,接不同任务头即可支持检测和分割。
在 nuScenes 上,BEVFusion 同时刷新了 3D 检测(70.2% mAP / 72.9% NDS,test)和 BEV 地图分割(62.7% mIoU,val)的 SOTA,且计算量比 TransFusion 低 1.9×。
核心论点:多传感器融合不应让一种模态迁就另一种——BEVFusion 打破了”点级融合是最优解”的长期信条,证明在共享 BEV 空间中保留各模态完整信息进行融合,既能处理几何导向任务(3D 检测),也能处理语义导向任务(地图分割),是真正的 task-agnostic 融合方案。
问题与动机
2022 年中,多传感器融合面临”融合空间”选择的根本性问题:
| 融合范式 | 代表作 | 融合空间 | 几何保真 | 语义保真 | 分割适用 | 典型检测性能 (val) |
|---|---|---|---|---|---|---|
| LiDAR-to-Camera | RGB-D 网络 | 透视图 | 差(几何畸变) | 好 | 有限 | — |
| Camera-to-LiDAR | PointPainting, MVP | 点云 | 好 | 差(仅 5% 匹配) | 差 | 65.8/69.6 |
| Proposal-Level | TransFusion, FUTR3D | 3D query | 好 | 中 | 差(仅前景) | 67.5/71.3 |
| BEV-Level | BEVFusion | BEV | 好 | 好 | 好 | 68.5/71.4 |
三大问题:
- Camera-to-LiDAR 投影的语义损失:32 线 LiDAR 仅有约 5% 的相机像素能匹配到点云点,导致 95% 的语义信息被丢弃。这使 PointPainting/MVP 在 BEV 分割上甚至不如纯相机模型
- 视图变换的效率瓶颈:LSS 风格的 Camera-to-BEV 变换需要生成约 200 万个 3D 特征点并做 BEV Pooling,原始实现耗时 500ms+,占模型总推理时间的 80% 以上
- 融合方案的任务特异性:点级/Proposal 级融合本质上是 object-centric 的,仅适用于检测任务,无法自然扩展到分割、追踪等不同任务
核心痛点:如何找到一个统一的融合空间,既不损失任何模态的信息(几何 + 语义),又足够高效、可扩展到任意 3D 感知任务?
核心洞察
洞察 1:BEV 是保留全部模态信息的最优融合空间
传统做法:Camera-to-LiDAR(将图像特征”paint”到点云上)或 LiDAR-to-Camera(投影深度到图像平面),都会让一种模态迁就另一种,不可避免地造成信息损失。
本文做法:将所有传感器特征统一变换到 BEV 空间后再融合。LiDAR-to-BEV 仅沿高度维度压缩(不产生几何畸变);Camera-to-BEV 通过 LSS 风格的深度分布投射(保留完整语义密度)。
为什么更好:
- LiDAR BEV 特征保留了完整的空间结构(x, y 平面),适合 3D 检测
- Camera BEV 特征保留了所有像素的语义信息(对比点级融合仅 5%),适合地图分割
- 消融实验证实:Camera-only BEVFusion 在分割任务上比 LiDAR-only 高 8-13% mIoU,而在检测任务上 LiDAR-only 更优——两者互补
洞察 2:Efficient BEV Pooling——预计算 + 区间归约消除视图变换瓶颈
传统做法:LSS 的 BEV Pooling 先对所有点计算前缀和(prefix sum),再在边界处做差。GPU 上的前缀和需要多级树归约(tree reduction),产生大量无用的中间结果,对约 200 万个特征点耗时超 500ms。
本文做法:两步优化:
- 预计算(Precomputation):相机特征点云的 3D 坐标在标定固定时不变,预计算 BEV 格点索引和排序 rank,推理时仅需按 rank 重排(17ms → 4ms)
- 区间归约(Interval Reduction):实现专用 CUDA kernel,每个 GPU 线程直接对一个 BEV 格点内的连续特征做区间求和,无需全局前缀和(500ms → 2ms)
为什么更好:
- 总延迟从 500ms 降至 12ms(40× 加速),仅占模型端到端推理的 10%
- 与 BEVDet 的近似方法(截断/均匀深度)不同,本方法是精确计算,不引入任何近似误差
- 这一优化使 BEV 空间融合在速度上首次可行,是整个 BEVFusion 框架的关键使能器
洞察 3:简单的卷积融合 + 任务头分离 = 任务无关的多任务感知
传统做法:不同任务需要不同的融合策略(检测用点级融合,分割需要密集融合),导致多任务系统架构复杂。
本文做法:多模态 BEV 特征经 concat 拼接后,通过一个轻量全卷积 BEV 编码器(几个残差块)补偿局部对齐误差,再接不同任务头(CenterPoint 检测头 / Focal Loss 分割头)。
为什么更好:
- 融合模块仅用一层 3×3 Conv + BN + ReLU(
ConvFuser),计算开销极小 - 架构天然 task-agnostic:同一融合特征接不同头即可支持检测、分割、追踪
- 消融:分开 BEV 编码器训练可缓解负迁移(NDS 69.9 + mIoU 58.4 vs 共享编码器 69.7 + 54.0)
三个关键数字:
- 40×:Efficient BEV Pooling 的加速比(500ms → 12ms),使 BEV 融合首次在速度上可行
- 70.2% mAP:nuScenes test 集 3D 检测 SOTA(单模型无 TTA),比 TransFusion 高 1.3%
- 62.7% mIoU:nuScenes val 集 BEV 地图分割,比 LiDAR-only 高 13.6%、比 Camera-only 高 6.1%
方法设计
4.1 整体架构
BEVFusion 的核心流程:
$$\{I_i\}_{i=1}^{N_{cam}} \xrightarrow{\text{Swin-T + FPN}} F_{cam} \xrightarrow{\text{LSS + BEV Pool}} F_{BEV}^{cam} \xrightarrow[\text{+ } F_{BEV}^{lidar}]{\text{ConvFuser}} F_{fused} \xrightarrow{\text{Task Heads}} \text{Det / Seg}$$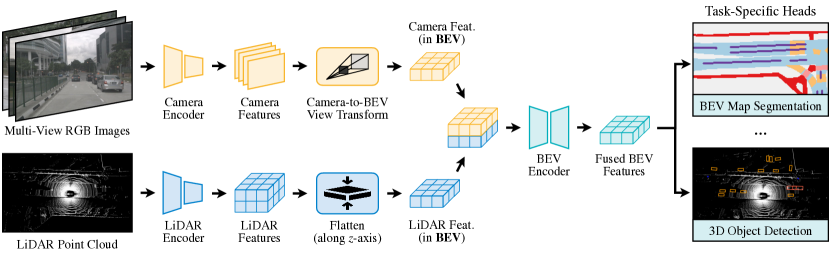
Camera (6 views, 256×704) LiDAR Point Cloud
│ │
▼ ▼
Swin-T + FPN VoxelNet (0.075m)
(1/8 feature map) (Sparse 3D Conv)
│ │
▼ │
DepthNet (D+C channels) │
│ │
▼ ▼
LSS View Transform BEV Scatter
+ Efficient BEV Pool (12ms) (高度维压缩)
│ │
▼ ▼
F_BEV^cam ─────────┬──────── F_BEV^lidar
│
concat + Conv(3×3)
(ConvFuser)
│
▼
F_fused (BEV)
┌────┴────┐
▼ ▼
Detection Head Segmentation Head
(CenterPoint) (Binary per-class)
cls + reg + vel focal loss × 6 classes
- Camera 分支:Swin-T + FPN 提取 1/8 分辨率特征 → 1×1 Conv 预测 $(D+C)$ 通道($D$ 个深度 bin + $C$ 维语义特征)→ 深度 softmax × 语义 = 视锥体特征 → BEV Pooling
- LiDAR 分支:VoxelNet 体素化(检测 0.075m / 分割 0.1m)→ 稀疏 3D 卷积 → BEV scatter(沿高度聚合)
- 融合:两路 BEV 特征 concat → ConvFuser(1 层 Conv-BN-ReLU)
- 任务头:检测用 CenterPoint 风格热力图 + 回归;分割用逐类二分类 + Focal Loss
4.2 关键组件
| 模块 | 输入 | 输出 | 功能 | 关键参数 |
|---|---|---|---|---|
| DepthNet | 图像特征 $[B \cdot N, C_{in}, fH, fW]$ | 深度+语义 $[B \cdot N, D+C, fH, fW]$ | 预测深度分布和语义特征 | $D=59$ (0.5-54m), $C=80$ |
| BEV Pool | 视锥体特征 $[B, N, C, D, fH, fW]$ + 几何索引 | BEV 特征 $[B, C, X, Y]$ | 3D 特征聚合到 BEV 网格 | 预计算 rank, 区间归约 |
| ConvFuser | 多模态 BEV 特征 list | 融合 BEV 特征 | 通道拼接 + 卷积对齐 | 3×3 Conv + BN + ReLU |
| Detection Head | 融合 BEV 特征 | 热力图 + 3D 回归 | CenterPoint 风格检测 | 10 类,anchor-free |
| Segmentation Head | 融合 BEV 特征 | 逐类二值分割 | 6 类背景分割 | [-50m, 50m]² |
损失函数:
$$\mathcal{L}_{det} = \mathcal{L}_{heatmap} + \lambda_{reg}\mathcal{L}_{reg}$$ $$\mathcal{L}_{seg} = \sum_{c=1}^{6} \text{FocalLoss}(\hat{y}_c, y_c)$$4.3 关键代码
代码来自官方仓库 mmdet3d/:
| 文件 | 类/函数 | 功能 |
|---|---|---|
ops/bev_pool/bev_pool.py |
QuickCumsumCuda |
Efficient BEV Pooling(区间归约) |
models/vtransforms/lss.py |
LSSTransform.get_cam_feats |
Camera-to-BEV 视图变换 |
models/fusers/conv.py |
ConvFuser |
全卷积 BEV 融合 |
📄 点击展开 Efficient BEV Pooling (QuickCumsumCuda) 代码
(来源:bev_pool.py)
class QuickCumsumCuda(torch.autograd.Function): |
📄 点击展开 LSSTransform.get_cam_feats 代码
(来源:lss.py)
|
📄 点击展开 ConvFuser 代码
(来源:conv.py)
|
实验与分析
5.1 主要结果
nuScenes 3D 检测(Table 1):
| 方法 | 模态 | mAP (test)↑ | NDS (test)↑ | mAP (val)↑ | NDS (val)↑ | MACs (G) | Latency (ms) |
|---|---|---|---|---|---|---|---|
| BEVFormer | C | 44.5 | 53.5 | 41.6 | 51.7 | — | — |
| CenterPoint | L | 60.3 | 67.3 | 59.6 | 66.8 | 153.5 | 80.7 |
| PointPainting | C+L | — | — | 65.8 | 69.6 | 370.0 | 185.8 |
| MVP | C+L | 66.4 | 70.5 | 66.1 | 70.0 | 371.7 | 187.1 |
| TransFusion | C+L | 68.9 | 71.6 | 67.5 | 71.3 | 485.8 | 156.6 |
| BEVFusion | C+L | 70.2 | 72.9 | 68.5 | 71.4 | 253.2 | 119.2 |
nuScenes BEV 地图分割(Table 2, val):
| 方法 | 模态 | Drivable | Ped Cross. | Walkway | Stop Line | Parking | Divider | mIoU↑ |
|---|---|---|---|---|---|---|---|---|
| LSS | C | 75.4 | 38.8 | 46.3 | 30.3 | 39.1 | 36.5 | 44.4 |
| BEVFusion | C | 81.7 | 54.8 | 58.4 | 47.4 | 50.7 | 46.4 | 56.6 |
| CenterPoint | L | 75.6 | 48.4 | 57.5 | 36.5 | 31.7 | 41.9 | 48.6 |
| PointPainting | C+L | 75.9 | 48.5 | 57.1 | 36.9 | 34.5 | 41.9 | 49.1 |
| BEVFusion | C+L | 85.5 | 60.5 | 67.6 | 52.0 | 57.0 | 53.7 | 62.7 |
关键发现:
- BEV 分割完全翻转了模态优势:纯 Camera BEVFusion (56.6%) 大幅超越纯 LiDAR CenterPoint (48.6%),而在 3D 检测上 LiDAR 仍占优——证明两种模态是互补的
- 点级融合在分割上失效:PointPainting (49.1%) 几乎没超过对应的 LiDAR-only (48.6%),而 BEVFusion (62.7%) 提升 13.6%——点级融合的 object-centric 设计无法捕捉背景语义
- 检测 + 速度双优:BEVFusion (70.2% mAP) 比 TransFusion (68.9%) 高 1.3%,计算量低 1.9×,延迟低 1.3×
5.2 消融实验:验证三个洞察
模态融合效果(验证洞察 1, Table 4a):
| 模态 | mAP | NDS | mIoU | 验证洞察 |
|---|---|---|---|---|
| L | 57.6 | 64.9 | 48.6 | — |
| C | 33.3 | 40.2 | 56.6 | — |
| L+C | 66.4 | 69.5 | 62.7 | 洞察 1 |
BEV 融合后检测 mAP 提升 +8.8%(vs LiDAR-only),分割 mIoU 提升 +6.1%(vs Camera-only),证明 BEV 空间同时保留了两种模态信息。
图像分辨率和体素大小消融(验证洞察 2, Table 4b-d):
| 图像分辨率 | mAP | NDS | mIoU |
|---|---|---|---|
| 128×352 | 64.0 | 68.2 | 60.5 |
| 256×704 | 66.4 | 69.5 | 62.7 |
| 384×1056 | 67.2 | 70.0 | 59.9 |
256×704 在检测和分割上取得最佳平衡。分割在高分辨率时反而下降(59.9 vs 62.7),可能因 BEV Pooling 点过密导致深度歧义增大。这一发现证明了 Efficient BEV Pooling 对不同分辨率的良好扩展性。
图像 Backbone 和训练策略消融(验证洞察 3, Table 4e-f):
| 策略 | mAP | NDS | mIoU | 验证洞察 |
|---|---|---|---|---|
| Swin-T (freeze) | 66.1 | 69.3 | 52.8 | — |
| Swin-T (finetune) | 66.4 | 69.5 | 62.7 | 洞察 3 |
| Image aug only | 63.8 | 68.1 | 62.3 | — |
| LiDAR aug only | 65.7 | 69.1 | 61.3 | — |
| Both aug | 66.4 | 69.5 | 62.7 | 洞察 3 |
冻结图像 backbone(现有融合方法的默认做法)导致分割 mIoU 暴跌 10%(52.8 vs 62.7)——因为点级融合中图像仅提供辅助信息,而在 BEV 融合中图像是语义的主要来源。端到端训练 + 双模态数据增强是充分发挥 BEV 融合潜力的关键。
5.3 性能瓶颈与失效场景
性能瓶颈:
- 深度估计质量:Camera-to-BEV 的精度依赖深度预测,当前仅用 1×1 Conv 无 LiDAR 深度监督,导致 Camera BEV 特征与 LiDAR BEV 存在局部空间错位——作者指出引入显式深度监督(如 BEVDepth)是有潜力的改进方向
- 多任务负迁移:联合训练检测 + 分割时存在性能下降(NDS 70.4 → 69.7),即使用分开的 BEV 编码器也仅缓解部分(69.9)
失效场景:
- 夜间纯相机性能骤降:Camera-only BEVFusion 在夜间 mAP 从白天 33.7 降至 13.5,但融合后提升 7.4(42.8 vs 35.4)——几何信息在相机失效时的价值
- 雨天 LiDAR 性能下降:CenterPoint 在雨天 mAP 从 62.9 降至 59.2,而 BEVFusion 可补偿恶劣天气带来的传感器退化
- 稀疏 LiDAR 场景:1 线 LiDAR 下 CenterPoint 仅 35.8 NDS,但 BEVFusion 仍可维持较高性能——密集 Camera 特征在 LiDAR 退化时起到关键补充
工程实践
6.1 训练配置
Image Backbone: Swin-T (nuImages pretrained), end-to-end finetune |
6.2 复现要点
- 必须端到端训练:冻结图像 backbone(现有融合方法默认做法)会导致分割 mIoU 暴跌 10%,BEVFusion 的优势来自充分利用图像语义
- 两侧数据增强缺一不可:仅用 Image aug(mAP 63.8)或仅用 LiDAR aug(65.7)均不如两侧同时增强(66.4)
- BEV Pooling CUDA 编译:高效 BEV Pooling 依赖自定义 CUDA 算子(
bev_pool_ext),需要python setup.py develop编译 - 检测和分割使用不同体素大小:检测 0.075m、分割 0.1m,BEV 空间范围也不同——需要 grid sampling 做分辨率转换
- 预训练权重加载顺序:训练 BEVFusion 检测模型时,需先加载 LiDAR-only 预训练权重(
--load_from pretrained/lidar-only-det.pth),再设置 Camera backbone 预训练
6.3 性能优化方向
精度提升:
- 引入 LiDAR 深度监督:当前 DepthNet 无深度 GT 监督,引入 BEVDepth 风格的深度 loss 可改善 Camera BEV 特征质量
- 更强 Backbone:test 集 BEVFusion-base (71.72% mAP) 使用更大模型,验证了 backbone 扩展的收益
- 缓解多任务负迁移:使用分开的 BEV 编码器 + 更精细的 loss 权重调节(当前 pilot study 仅初步验证)
速度优化:
- TensorRT 部署:NVIDIA 已提供 CUDA-BEVFusion INT8 方案,在 Jetson Orin 上达到 25 FPS
- 降低 BEV 分辨率:体素从 0.075m 增大到 0.125m,mAP 仅降 1.3 但显存和计算量显著减少
研究启示
7.1 可迁移的思想
- “保留全部信息再融合”原则:在多源数据融合中,不应让一种模态迁就另一种而丢弃信息——先将各源数据变换到统一空间,再做对等融合。这一思想可推广到 Radar-Camera、多光谱、V2X 等融合场景
- 效率瓶颈诊断方法论:先 profiling 定位瓶颈(BEV Pooling 占 80%+ → 500ms),再针对性优化(预计算 + 区间归约)。这种”测量→诊断→定点优化”的方法论适用于任何系统加速
- 简单融合胜过复杂设计:仅用一层 Conv(
ConvFuser)即可有效融合多模态 BEV 特征,比 Attention、MLP Mixer 等复杂融合机制更稳健,且任务无关
7.2 方法局限
- 无时序建模:BEVFusion 仅处理单帧数据,未利用多帧信息。后续 BEVFormer 和 StreamPETR 表明时序融合可大幅改善速度估计和遮挡目标检测
- Camera 分支无深度监督:DepthNet 仅通过下游任务 loss 间接学习深度,深度预测质量远低于 BEVDepth 等有显式监督的方法
- 多任务训练尚未解决:联合训练存在负迁移,当前只能分任务训练多个模型,未能真正实现”一个模型多任务”的愿景
7.3 技术影响
- 打破”点级融合最优”的长期信条:BEVFusion 首次系统性地证明 BEV 空间融合在检测和分割上均优于点级融合,改变了多传感器融合的研究范式
- 推动 BEV 融合工业落地:BEVFusion 被集成到 NVIDIA DeepStream、mmdetection3d,提供 TensorRT INT8 部署方案(Jetson Orin 25 FPS),成为工业界 LiDAR-Camera 融合的标准基线
- **弥合相机与 LiDAR 的”任务鸿沟”**:首次定量揭示了相机在语义任务上的优势和 LiDAR 在几何任务上的优势,为后续多模态互补性研究(如恶劣天气、稀疏 LiDAR)奠定了实验基础
- Efficient BEV Pooling 成为基础组件:40× 加速的 BEV Pooling 后续被 BEVDet 系列和 BEVPoolv2 等广泛采用,成为 LSS 范式的标准加速方案