Task: Multi-Camera 3D Object Detection / BEV Map Segmentation
Method: BEV Queries, Spatial Cross-Attention, Temporal Self-Attention, Deformable DETR Head, Perspective Supervision
Venue: ECCV 2022 (BEVFormer) / arXiv 2022 (BEVFormer v2)
Year: 2022
Paper: https://arxiv.org/abs/2203.17270 (BEVFormer) / https://arxiv.org/abs/2211.10439 (BEVFormer v2)
Code: https://github.com/fundamentalvision/BEVFormer
摘要
在多相机 3D 感知中,如何将多视图图像特征统一到鸟瞰图(BEV)表示是核心问题。以 LSS 为代表的显式深度范式需要预测逐像素深度分布,其性能严重依赖深度估计质量(BEVDepth 对此有系统性验证)。本文提出 BEVFormer,采用完全不同的思路——通过时空 Transformer 学习 BEV 表示,不显式依赖深度信息。BEVFormer 的核心是一组可学习的栅格状 BEV Queries,它们通过空间交叉注意力(Spatial Cross-Attention) 从多视图图像中自适应采样空间特征,通过时序自注意力(Temporal Self-Attention) 以类 RNN 方式递归融合历史 BEV 特征。6 层编码器堆叠后,输出的统一 BEV 特征可同时支持 3D 目标检测和地图分割任务。
在 nuScenes test 集上,BEVFormer 达到 56.9% NDS,比此前最优的 DETR3D 高出 9.0 个点,首次使纯相机方法逼近 LiDAR 基线。时序融合大幅改善了速度估计(mAVE 0.378 m/s)和低可见度目标召回率。
核心论点:BEV 特征的生成不必依赖显式深度估计——通过可学习的 BEV Queries 配合可变形注意力,Transformer 可以自适应地从多视图图像中”查询”所需的空间信息;而 BEV 空间天然适合作为时序融合的桥梁,以递归方式引入历史帧几乎不增加计算量,却显著提升运动估计和遮挡检测能力。
问题与动机
2022 年初,多相机 BEV 感知存在两条主要技术路线,各有核心瓶颈:
| 方法类型 | 代表作 | BEV 生成方式 | 核心问题 | nuScenes val (mAP/NDS) |
|---|---|---|---|---|
| LSS-based | BEVDet, BEVDepth | 像素级深度分布 → 视锥体投影 | 依赖深度估计质量,对标定敏感 | 28.2/32.7 ~ 41.6/51.7 |
| Query-based (稀疏) | DETR3D | 3D query 投影到 2D 采样 | 无 BEV 表示,无法做地图分割 | 34.6/42.5 |
| MLP-based | VPN | MLP 学习视角变换 | 参数量大,分辨率受限 | 25.2/33.4 |
| IPM-based | — | 逆透视映射 | 假设地平面,无法处理 3D 结构 | — |
两条路线的根本矛盾:
- LSS 路线:BEV 生成质量强依赖深度准确度,深度预测不准则 BEV 特征不准,形成”深度-检测”复合误差
- Query-based 路线:DETR3D 的 3D query 只与图像做稀疏交互,不生成空间密集的 BEV 特征,无法同时支持检测和分割等多任务
- 时序缺失:上述方法大多为单帧推理,不利用时序信息,导致速度估计几乎失效(mAVE > 0.8 m/s),且遮挡目标召回率低
核心痛点:如何设计一种不依赖显式深度的 BEV 生成方法,既能生成空间密集的 BEV 特征支持多任务,又能高效引入时序信息改善运动估计和遮挡检测。
核心洞察
洞察 1:BEV Queries 作为可学习栅格——用注意力替代显式深度投影
传统做法:LSS 系列通过 DepthNet 为每个像素预测深度分布 $\alpha \in \Delta^{|D|-1}$,外积形成视锥体特征后投影到 BEV。这要求深度预测足够准确,否则整条管线的 BEV 特征质量直接受损。
本文做法:定义一组可学习的栅格状参数 $Q \in \mathbb{R}^{H \times W \times C}$ 作为 BEV Queries,其中每个 query $Q_p$ 对应 BEV 平面上位置 $p = (x, y)$ 的网格单元,负责该区域的特征聚合。每个网格对应真实世界 $s$ 米的范围,BEV 中心默认与自车位置对齐。BEV Queries 不预测深度,而是通过注意力机制主动从图像特征中”查询”所需信息。
为什么更好:
- 深度估计的误差不再是硬约束——注意力权重由数据驱动学习,可自适应选择最有用的图像区域
- BEV Queries 的栅格结构天然输出空间密集的 BEV 特征,可直接接检测头或分割头
- 不依赖 LiDAR 深度真值做中间监督,纯视觉端到端训练
洞察 2:空间交叉注意力——从 BEV “柱体”到 2D 图像的高效采样
传统做法:让每个 BEV query 与所有相机的全部图像特征做全局注意力。6 个相机、多尺度特征的输入规模巨大,全局注意力的 $O(N^2)$ 计算量不可承受。
本文做法:基于可变形注意力(Deformable Attention)设计空间交叉注意力(SCA)。核心思路是将 BEV query “提升”为 3D 柱体,在柱体上采样 $N_{ref}$ 个参考点,投影到 2D 视图后,仅在命中视图($\mathcal{V}_{hit}$)的参考点附近局部采样:
$$\text{SCA}(Q_p, F_t) = \frac{1}{|\mathcal{V}_{hit}|} \sum_{i \in \mathcal{V}_{hit}} \sum_{j=1}^{N_{ref}} \text{DeformAttn}(Q_p, \mathcal{P}(p, i, j), F_t^i)$$ 其中投影函数 $\mathcal{P}$ 的计算方式为:先由 BEV 坐标还原真实世界位置 $x' = (x - W/2) \cdot s$, $y' = (y - H/2) \cdot s$,再结合预设高度锚点 $\{z_j'\}_{j=1}^{N_{ref}}$(从 $-5$m 到 $3$m 均匀采样),通过相机投影矩阵 $T_i$ 得到 2D 参考点: $$z_{ij} \cdot [x_{ij}, y_{ij}, 1]^T = T_i \cdot [x', y', z_j', 1]^T$$为什么更好:每个 BEV query 只与其几何上可能对应的视图区域交互(通常 1-2 个视图),而非全部 6 个视图的全部像素。全局注意力 36G 显存,可变形注意力仅需 20G,且 NDS 高出 4.4 个点(0.448 vs 0.404)。
范式对比:LSS 为了避免 dense F.grid_sample 的高昂开销($H \times W \times D$ 个采样点的随机插值),转用 broadcast 显式构造 3D 特征。BEVFormer 之所以能”重新引入”采样思想,关键在于 BEV query 数量(200×200 = 40K)远少于图像像素数(~1M)——每个 query 仅需 $N_{ref} \times |\mathcal{V}_{hit}|$ 个采样点(通常 4~8 个),使得 deformable sampling 的计算量可控,同时换来了更强的几何对齐精度和跨视角融合能力。本质上:LSS 用规则计算换效率(快但粗),BEVFormer 用稀疏采样换精度(慢但准)。
洞察 3:时序自注意力——以 RNN 方式递归融合历史 BEV
传统做法:FIERY 等方法通过直接堆叠多帧 BEV 特征引入时序信息,但固定窗口长度限制了时序范围,且计算量随帧数线性增长。
本文做法:时序自注意力(TSA)采用类 RNN 的递归策略,仅使用前一帧的 BEV 特征 $B_{t-1}$ 与当前 BEV queries $Q$ 做可变形注意力:
$$\text{TSA}(Q_p, \{Q, B'_{t-1}\}) = \sum_{V \in \{Q, B'_{t-1}\}} \text{DeformAttn}(Q_p, p, V)$$ 其中 $B'_{t-1}$ 是根据自车运动对齐后的历史 BEV 特征。注意力偏移量 $\Delta p$ 由 $Q$ 和 $B'_{t-1}$ 的拼接输入预测,使网络能学习动态目标的运动补偿。序列首帧无历史 BEV 时,退化为普通自注意力 ${Q, Q}$。训练时,从过去 2 秒序列中随机采样 3 帧 + 当前帧共 4 帧,前 3 帧无梯度递归生成 ${B_{t-3}, B_{t-2}, B_{t-1}}$,仅最后一帧计算 loss。推理时按时间序列在线递推,仅保存上一帧 BEV 特征,几乎无额外计算开销。
为什么更好:递归方式使时序信息理论上可无限传播,而堆叠方式的时序窗口固定。BEVFormer vs BEVFormer-S(无时序):NDS 51.7 → 44.8(+6.9),速度估计 mAVE 从 0.802 降至 0.394,低可见度(0-40%)目标召回率提升 6.0% 以上。
三个关键数字:
- 56.9% NDS:nuScenes test 集 SOTA,比 DETR3D 高 9.0 个点,逼近 LiDAR 基线
- mAVE 0.378 m/s:速度估计误差,时序融合使纯相机方法首次接近 LiDAR 水平
- +6.9 NDS:BEVFormer vs BEVFormer-S(无时序),时序自注意力带来的最大增益
方法设计
4.1 整体架构
BEVFormer 的核心流程可概括为:
$$\{I_t^i\}_{i=1}^{N_{view}} \xrightarrow{\text{Backbone+FPN}} F_t \xrightarrow[\text{+ } B_{t-1}]{\text{BEV Encoder (×6)}} B_t \xrightarrow{\text{Task Head}} \text{3D Boxes / Seg Map}$$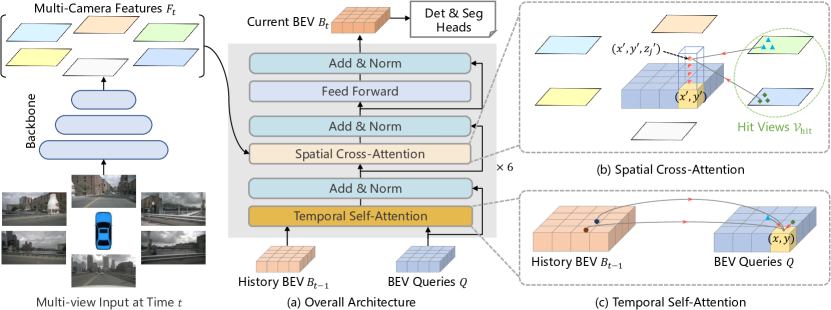
6× Camera Images (900×1600)
│
▼
ResNet-101-DCN (FCOS3D pretrained)
│
▼
FPN (1/16, 1/32, 1/64), C=256
│
▼ ┌───────────────────┐
BEV Queries Q ∈ R^{200×200×256} │ Prev BEV B_{t-1} │
│ │ (ego-motion align)│
▼ └────────┬──────────┘
┌───────────────────────────────────────────┤
│ BEV Encoder Layer (×6) │
│ ┌─────────────────────────────────┐ │
│ │ Temporal Self-Attention (TSA) │◄─────┘
│ │ Q_p attends {Q, B'_{t-1}} │
│ ├─────────────────────────────────┤
│ │ LayerNorm │
│ ├─────────────────────────────────┤
│ │ Spatial Cross-Attention (SCA) │◄── Multi-view Features F_t
│ │ BEV → Pillar → 2D projection │
│ │ DeformAttn on V_hit only │
│ ├─────────────────────────────────┤
│ │ LayerNorm + FFN + LayerNorm │
│ └─────────────────────────────────┘
└───────────────────────────────────────────┘
│
▼
BEV Features B_t ∈ R^{200×200×256}
│
┌────┴────┐
▼ ▼
Det Head Seg Head
(Deformable (Panoptic
DETR) SegFormer)
│ │
▼ ▼
3D Boxes Semantic Map
+ Velocity
- BEV Queries:$200 \times 200$ 栅格,每网格 $0.512$m,覆盖 $[-51.2, 51.2]\text{m}^2$,附加可学习位置编码
- Spatial Cross-Attention:每个 query 对应 $N_{ref} = 4$ 个高度锚点($-5$m 到 $3$m),投影到 2D 后每个参考点用 4 个采样点
- Temporal Self-Attention:$\text{num_bev_queue} = 2$(当前 + 上一帧),利用自车运动对齐历史 BEV
- Detection Head:基于 Deformable DETR,900 个 object queries,预测 $(l, w, h, x_o, y_o, z_o, \cos\theta, \sin\theta, v_x, v_y)$ 共 10 个参数,无 NMS
- Segmentation Head:基于 Panoptic SegFormer 的 mask decoder,每个语义类别一个固定 query
4.2 关键组件
| 模块 | 输入 | 输出 | 功能 | 关键参数 |
|---|---|---|---|---|
| BEV Queries | — | $(200, 200, 256)$ | 可学习的 BEV 栅格 | $s = 0.512$m |
| Spatial Cross-Attention | $Q_p$, $F_t$ | refined $Q_p$ | 从多视图采样空间特征 | $N_{ref}=4$, 4 sampling pts |
| Temporal Self-Attention | $Q_p$, $B’_{t-1}$ | refined $Q_p$ | 融合历史时序信息 | ego-motion align |
| FFN | refined $Q_p$ | encoder output | 非线性变换 | 2 层 FC |
| Det Head (Deformable DETR) | $B_t$ | 3D boxes + vel | 端到端检测 | 900 queries, $L_1$ loss |
| Seg Head (Mask Decoder) | $B_t$ | semantic map | 语义分割 | class-fixed queries |
损失函数:检测任务仅使用 $L_1$ loss 监督 3D 框回归(含速度),配合 Deformable DETR 的匈牙利匹配;分割任务使用标准 cross-entropy + dice loss。
4.3 关键代码
核心代码涉及 3 个模块,均来自官方仓库 projects/mmdet3d_plugin/bevformer/modules/:
| 文件 | 类/函数 | 功能 |
|---|---|---|
encoder.py |
BEVFormerEncoder.get_reference_points |
生成 3D/2D 参考点 |
encoder.py |
BEVFormerEncoder.point_sampling |
3D 参考点投影到 2D 视图 |
spatial_cross_attention.py |
SpatialCrossAttention.forward |
空间交叉注意力推理 |
temporal_self_attention.py |
TemporalSelfAttention.forward |
时序自注意力推理 |
📄 点击展开 get_reference_points 代码
(来源:encoder.py)
|
📄 点击展开 SpatialCrossAttention.forward 代码
(来源:spatial_cross_attention.py)
def forward(self, query, key, value, residual=None, query_pos=None, |
📄 点击展开 TemporalSelfAttention.forward 代码
(来源:temporal_self_attention.py)
def forward(self, query, key=None, value=None, identity=None, |
实验与分析
5.1 主要结果
nuScenes test 集 3D 检测(Table 1):
| 方法 | 模态 | Backbone | NDS↑ | mAP↑ | mATE↓ | mAOE↓ | mAVE↓ |
|---|---|---|---|---|---|---|---|
| CenterPoint | LiDAR | — | 65.5 | 58.0 | — | — | — |
| FCOS3D | Camera | R101 | 42.8 | 35.8 | 0.690 | 0.452 | 1.434 |
| DETR3D | Camera | V2-99 | 47.9 | 41.2 | 0.641 | 0.394 | 0.845 |
| BEVFormer-S | Camera | R101 | 46.2 | 40.9 | 0.650 | 0.439 | 0.925 |
| BEVFormer | Camera | R101 | 53.5 | 44.5 | 0.631 | 0.405 | 0.435 |
| BEVFormer | Camera | V2-99 | 56.9 | 48.1 | 0.582 | 0.375 | 0.378 |
nuScenes val 集 3D 检测(Table 2):
| 方法 | Backbone | NDS | mAP | mAVE |
|---|---|---|---|---|
| FCOS3D | R101 | 41.5 | 34.3 | 1.292 |
| DETR3D | R101 | 42.5 | 34.6 | 0.842 |
| BEVFormer-S | R101 | 44.8 | 37.5 | 0.802 |
| BEVFormer | R101 | 51.7 | 41.6 | 0.394 |
关键发现:
- BEVFormer (R101) 比 DETR3D (R101) 在 val 集高出 9.2 NDS(51.7 vs 42.5),在 test 集高出 9.0 NDS
- 时序融合对速度估计贡献最大:mAVE 从 0.925 降至 0.435(test, R101),改善幅度超 50%
- BEVFormer 的 56.9% NDS 逼近 LiDAR 方法 SSN(56.9%)和 PointPainting(58.1%)
5.2 消融实验:验证三个洞察
空间注意力类型消融(验证洞察 1 & 2,Table 5):
| 方法 | 注意力类型 | NDS | mAP | mATE | 显存 |
|---|---|---|---|---|---|
| VPN | — | 33.4 | 25.2 | 0.926 | 20G |
| Lift-Splat | — | 39.7 | 34.8 | 0.784 | 20G |
| BEVFormer-S | Global | 40.4 | 32.5 | 0.837 | 36G |
| BEVFormer-S | Points only | 42.3 | 35.1 | 0.753 | 20G |
| BEVFormer-S | Local (deformable) | 44.8 | 37.5 | 0.725 | 20G |
- 可变形注意力(Local)同时优于全局注意力和纯参考点交互:NDS 44.8 vs 40.4 vs 42.3
- 全局注意力虽不需要精确标定,但显存翻倍(36G vs 20G),且性能最差
- BEVFormer-S 已超越 Lift-Splat(44.8 vs 39.7 NDS),验证了 query-based BEV 生成的有效性
时序融合效果(验证洞察 3):
| 模型 | 时序 | NDS | mAP | mAVE | 低可见度召回率 |
|---|---|---|---|---|---|
| BEVFormer-S | ✗ | 44.8 | 37.5 | 0.802 | baseline |
| BEVFormer | ✓ | 51.7 | 41.6 | 0.394 | +6.0% (0-40%) |
训练帧数消融(Table 7):
| 训练帧数 | NDS | mAP | mAVE |
|---|---|---|---|
| 1 | 44.8 | 37.5 | 0.802 |
| 2 | 49.0 | 38.8 | 0.467 |
| 3 | 51.0 | 41.0 | 0.423 |
| 4 | 51.7 | 41.6 | 0.394 |
| 5 | 51.7 | 41.2 | 0.387 |
4 帧后性能饱和,更多帧不再有显著提升,论文默认使用 4 帧。
设计选择消融(Table 8):
| 配置 | 自车对齐(A) | 随机采样(R) | 双输入预测(B) | NDS | mAP |
|---|---|---|---|---|---|
| #1 | ✗ | ✓ | ✓ | 51.0 | 41.0 |
| #2 | ✓ | ✗ | ✓ | 51.3 | 41.0 |
| #3 | ✓ | ✓ | ✗ | 51.3 | 40.4 |
| #4 | ✓ | ✓ | ✓ | 51.7 | 41.6 |
自车运动对齐、随机帧采样增强、双输入(Q + B’_{t-1})预测偏移量三者均有正向贡献。
5.3 性能瓶颈与失效场景
性能瓶颈:
- Backbone 是推理延迟瓶颈:Table 6 显示 BEV Encoder 从 6 层减到 1 层(130ms→25ms),但 backbone 固定开销不变,整体加速受限
- Camera-based 深度定位精度:mATE(0.631m)仍远高于 LiDAR 方法,准确推断 3D 位置仍是纯相机方法的长期挑战
- 小远目标检测:可视化结果(Fig. 4)显示 BEVFormer 在小型/远距离目标上仍有漏检
失效场景:
- 严重标定偏差:Appendix B 实验显示,在 level 4 外参噪声下 NDS 下降 14.3%(BEVFormer)。虽然可变形注意力相比纯参考点交互更鲁棒(14.3% vs 17.3%),但对标定精度仍有依赖
- 序列首帧无时序信息:TSA 退化为自注意力,此时性能等价于 BEVFormer-S,速度估计能力完全丧失
- 负迁移(多任务联合训练):Table 4 显示检测+分割联合训练时,道路分割 IoU 从 80.1% 降至 77.5%,车道线从 25.7% 降至 23.9%
工程实践
6.1 训练配置
Backbone: ResNet-101-DCN (FCOS3D pretrained) / VoVNet-99 (DD3D pretrained) |
6.2 复现要点
- FCOS3D 预训练必要性:Backbone 从 FCOS3D checkpoint 初始化,直接 ImageNet 初始化会导致注意力发散
- Deformable Attention CUDA 编译:
MultiScaleDeformableAttnFunction需要编译 CUDA 扩展(ms_deform_attn_forward/backward),FP16 不稳定需用 FP32 - 历史 BEV 无梯度:训练时前 3 帧递归生成 $B_{t-3}, B_{t-2}, B_{t-1}$ 需用
torch.no_grad(),仅当前帧 $B_t$ 参与反向传播 - 自车运动对齐:
prev_bev需根据相邻帧间的 ego-motion 变换矩阵做空间平移对齐,使同一网格位置对应同一真实世界位置 - 4 帧随机采样:从过去 2s 的连续序列中随机采样 3 帧 + 当前帧,这个随机采样策略本身是一种数据增强
- shift_ref_2d 已知 bug:官方代码注释中标注了
shift_ref_2d = ref_2d.clone()有 bug,但为了论文结果可复现保留了该实现
6.3 性能优化方向
精度提升:
- 更大感受野的 Backbone:V2-99(DD3D 预训练)比 R101 提升 3.4 NDS(56.9 vs 53.5),更强的 backbone 直接提升图像特征质量
- 增加 BEV 分辨率:当前 200×200(0.512m/格),提升到 0.25m/格 可改善小目标检测精度,但计算量和显存二次增长
- 引入深度先验:BEVFormer 不使用显式深度,但 BEVDepth 证明显式深度监督能显著改善 mATE,两种路线的融合(如在 SCA 中引入深度引导采样)是有潜力的方向
速度优化:
- 轻量化配置:Table 6 Config D(单尺度 + 1 层 encoder + 小 BEV)仅 7ms encoder 延迟,NDS 47.8%,但 backbone 仍是瓶颈
- 高效 Backbone:当前 R101-DCN 的推理时间远大于 BEV Encoder,替换为 EfficientNet / SwinT 等轻量 backbone 收益更大
- BEV Query 稀疏化:非关键区域的 BEV query 可跳过(如远距离/背景区域),减少 SCA 的计算量
研究启示
7.1 可迁移的思想
- “查询驱动”的跨视图特征聚合:BEV Queries + Deformable Attention 的模式不限于 BEV 感知——任何多视图融合任务(如多传感器融合、多模态融合)都可以用可学习 queries 主动查询各输入源的兴趣区域,替代显式的几何投影或全局注意力
- RNN 式递归时序融合:仅保存上一帧的”状态”即可实现理论上无限长时序依赖,远优于固定窗口堆叠。这一思路可迁移到视频理解、在线建图、轨迹预测等任务
- 柱体参考点投影:从 BEV 网格沿高度轴生成柱体 3D 参考点、再投影到 2D 获取感兴趣视图的方法,提供了一种通用的”3D → 2D 稀疏索引”范式,可用于任何需要从 3D 空间查询 2D 信息的场景
- 多任务共享 BEV 特征:统一的 BEV 表示可直接接检测头和分割头,避免为不同任务维护独立的特征管线
7.2 方法局限
- 不使用显式深度,mATE 较高:BEVFormer 的翻译误差(mATE 0.631m)明显高于后续加入深度监督的方法(如 BEVDepth 的 mATE ~0.45m),纯注意力驱动的深度感知仍不如显式几何约束
- BEV-grid-query 的计算瓶颈:200×200 = 40K 个 BEV query 每个都需做多视图 deformable sampling,本质是 scatter-gather 型算子(随机访存、cache 不连续),GPU 利用率远低于 LSS 的 dense tensor 计算。这也是 BEV-grid-query 路线后续跟随者极少的根本原因——工程落地困难,TensorRT 导出复杂,延迟报动大
- 训练开销较大:6 层 encoder × 6 视图 × 多尺度特征 × 4 帧时序,R101-DCN base 版需 28.5G 显存,训练成本高于 LSS-based 方法
- 对 Backbone 预训练依赖强:必须从 FCOS3D/DD3D 等 3D 感知任务的 checkpoint 初始化,若从 ImageNet 直接训练则收敛困难
7.3 技术影响
- 开创 Transformer-based BEV 生成路线:BEVFormer 是首个用 Transformer 注意力(而非显式深度投影)生成 BEV 特征并达到 SOTA 的方法,与 LSS/BEVDet 的显式深度路线形成两大技术流派。后续的 BEVFormerV2、StreamPETR、Sparse4D、SparseBEV 等均延续了 query-based 范式
- 确立”时序 BEV”的基本框架:RNN 式递归融合的设计被后续 SOLOFusion、VideoBEV 等大量工作采纳,成为时序 BEV 融合的标准范式之一
- 推动 BEV 感知统一架构:BEVFormer 首次在同一框架下同时处理检测和分割任务,启发了后续 UniAD、Planning-oriented AD 等端到端自动驾驶系统将感知、预测、规划统一在 BEV 空间中
- Waymo Challenge 冠军方案基础:BEVFormer++ 基于 BEVFormer 改进,获得 CVPR 2022 Waymo 3D Camera-Only Detection Challenge 冠军,验证了该框架在工业级竞赛中的竞争力
BEVFormer v2:透视视角监督解锁现代 Backbone
论文:BEVFormer v2: Adapting Modern Image Backbones to Bird’s-Eye-View Recognition via Perspective Supervision(arXiv 2022,同一实验室:清华大学/商汤,Jifeng Dai 等)
BEVFormer v2 解决了 BEVFormer 的核心工程问题:BEV 监督对 Backbone 的梯度信号太稀疏、太间接,导致非深度预训练的现代 Backbone(如 ConvNeXt、InternImage)难以有效适配。
BEVFormerV2 核心改进
改进 1:透视视角辅助监督
BEV 检测头的损失经过多层 Transformer 传播到 Backbone,梯度稀疏且间接。BEVFormer v2 在 Backbone 上直接加一个 FCOS3D 风格的透视 3D 检测头,提供密集、直接的图像级监督。总损失:
$$\mathcal{L}_{total} = \lambda_{bev} \mathcal{L}_{bev} + \lambda_{pers} \mathcal{L}_{pers}$$消融实验显示(R101, 48ep, val, 无时序):
- BEV Only: 42.6% NDS / 35.5% mAP
- Perspective & BEV: 45.1% NDS / 37.4% mAP(+2.5% NDS)
- BEV & BEV(两阶段但均用 BEV 头): 42.8% NDS——证明提升来自透视监督而非两阶段结构
透视监督对 R50/DLA-34/R101/V2-99/InternImage-B 等不同 Backbone 均稳定提升 ~3% NDS / ~2% mAP。
改进 2:两阶段 BEV 检测器
透视头的预测结果经 NMS 后,将 3D 框中心投影到 BEV 平面作为 per-image reference points,与原始可学习 query 合并为“混合 object queries”,送入 Deformable DETR 解码器。这使第二阶段既能利用图像级概率先验,也保留原始 query 的全局搜索能力。
改进 3:重设计时序编码器
用 warp-and-concatenate 替代原始 RNN 式递归,并增大采样间隔(从 0.5s 到 2s)获取更长时距信息。离线模式还支持双向时序融合(未来帧)。
BEVFormerV2 主要结果
nuScenes test 集:
| 方法 | Backbone | NDS | mAP |
|---|---|---|---|
| BEVFormer | V2-99† | 0.569 | 0.481 |
| PETRv2 | V2-99 | 0.582 | 0.490 |
| BEVDepth | V2-99† | 0.600 | 0.503 |
| BEVFormer v2 | InternImage-B | 0.620 | 0.540 |
| BEVFormer v2 | InternImage-XL | 0.634 | 0.556 |
† 表示 V2-99 经过深度估计预训练。BEVFormer v2 的 InternImage Backbone 仅用 COCO 预训练,无需任何 3D 深度预训练。
关键发现:
- 透视监督在 24ep 即可达到 BEV-only 48ep 的性能,收敛速度约快一倍
- InternImage-XL 仅用 COCO 预训练即创 63.4% NDS SOTA,超 BEVStereo(V2-99 + 深度预训练 + 90ep)+2.4% NDS
- 透视监督贡献 +2.2% NDS / +2.6% mAP(Tab.6 对比“All but Perspective” vs 全配置)