Task: Multi-Camera 3D Object Detection / Multi-Object Tracking
Method: Sparse 4D Keypoint Sampling, Deformable Feature Aggregation, Recurrent Instance Propagation, Temporal Instance Denoising
Venue: arXiv
Year: 2022–2023
Paper: https://arxiv.org/abs/2211.10581 (v1) / https://arxiv.org/abs/2305.14018 (v2) / https://arxiv.org/abs/2311.11722 (v3)
Code: https://github.com/HorizonRobotics/Sparse4D
摘要
BEV-based 方法(如 LSS、BEVDet、BEVFormer)通过构建 dense BEV 特征取得了显著进展,但 dense 视角变换计算量大、感知范围受限于 BEV 栅格尺寸、且高度信息被压缩。本文介绍 Sparse4D 系列(v1→v2→v3),采用完全不同的路线——以稀疏实例(anchor + instance feature)为核心,通过 4D 关键点采样(空间 + 时间)在多视图多尺度多时间戳图像特征上稀疏采样并层次化融合,迭代精炼 3D 框。v1 提出 Deformable 4D Aggregation 和 Depth Reweight Module;v2 将时序融合从 $O(T)$ 多帧采样改为 $O(1)$ 递归实例传播,并引入 Efficient Deformable Aggregation(EDA)和 Dense Depth Supervision;v3 进一步通过 Temporal Instance Denoising、Quality Estimation(centerness + yawness)和 Decoupled Attention 提升训练收敛性,并以极简方式将检测器扩展为端到端跟踪器。
在 nuScenes test 集上,Sparse4Dv3(VoV-99)达到 65.6% NDS / 57.0% mAP,刷新纯相机方法记录;最强配置(EVA02-Large + 未来帧)达到 71.9% NDS,甚至超越部分 LiDAR 方法的 NDS 和 mAVE。跟踪方面,v3 以 67.7% AMOTA 达到 SOTA。
核心论点:多视图 3D 感知不必依赖 dense BEV 表示——以稀疏实例为核心、用 4D 关键点做局部采样即可高效完成特征聚合和时序对齐;稀疏方法的检测头计算量与图像分辨率无关,天然适合高分辨率 / 大感知范围场景,且实例级输出直接服务于端到端跟踪和规划。
问题与动机
2022 年底,多相机 3D 检测的主流方案可分为三类:
| 方法类型 | 代表作 | 特征融合方式 | 核心问题 | nuScenes val NDS |
|---|---|---|---|---|
| LSS-based (Dense BEV) | BEVDet, BEVDepth | 像素级深度 → dense 视角变换 | 计算量大、范围受限于 BEV 栅格、高度信息丢失 | ~51.7 |
| Query-based (Dense Attn) | PETR, PETRv2 | 3D PE + 全局注意力 | 计算量随图像分辨率二次增长 | ~53.7 |
| Query-based (Sparse) | DETR3D | 单参考点投影采样 | 特征采样不充分,无时序融合 | ~42.5 |
三类方案的根本矛盾:
- Dense BEV 路线:视角变换需处理全部像素的 $H \times W \times D$ 个点(LSS),计算量固定且与感知范围/分辨率强耦合;BEV 栅格压缩了高度信息,不适合路牌、红绿灯等需要高度区分的任务
- 全局注意力路线:PETR 的计算量为 $O(N_{query} \times N_{pixel})$,无法处理高分辨率(如 4K)输入
- 已有稀疏方法:DETR3D 每个 anchor 仅用单个参考点采样,特征表达能力严重不足;且所有稀疏方法均缺乏时序融合
核心痛点:如何设计一种检测头计算量与图像分辨率无关的稀疏方案,同时在特征采样充分度、时序融合效率和训练收敛性上全面追赶 dense 方法。
核心洞察
洞察 1:4D 关键点稀疏采样——用多关键点替代单参考点和 dense BEV
传统做法:DETR3D 每个 anchor 仅用 1 个 3D 参考点投影到图像上采样,信息极度稀疏;BEV-based 方法为获取丰富特征不得不构建完整的 dense 表示。
本文做法:为每个 3D anchor 分配 $K$ 个关键点($K_F$ 个固定点 + $K_L$ 个可学习点),分布在 anchor 框的中心和六面中心(固定)以及由实例特征预测的自适应位置(可学习)。这些关键点进一步沿时间轴扩展为 4D 关键点 $P_m \in \mathbb{R}^{K \times T \times 3}$,通过速度补偿和 ego motion 对齐投影到各历史帧的图像坐标系:
$$P_{m,t}' = P_{m,t_0} - dt \cdot (t_0 - t) \cdot [v_x, v_y, v_z]_m$$ $$P_{m,t} = R_{t_0 \to t} \cdot P_{m,t}' + T_{t_0 \to t}$$采样后的多维特征 $f_m \in \mathbb{R}^{K \times T \times N \times S \times C}$ 通过层次化融合(先按 view/scale 加权求和,再沿时间轴顺序融合,最后多关键点求和)生成高质量实例特征。
为什么更好:
- 多关键点采样提取 anchor 内部丰富的上下文(vs. DETR3D 的单点)
- 关键点天然扩展到时间维度,实现特征级的时序对齐(vs. BEV-based 的帧级对齐)
- 采样点数量仅与 anchor 数(900)和关键点数(13)相关,与图像分辨率无关
洞察 2:递归实例传播——从 $O(T)$ 多帧采样到 $O(1)$ 递归传播
传统做法(Sparse4D v1):时序融合需在每帧推理时对所有历史帧重复做关键点投影 + 图像特征采样,计算量和显存随历史帧数 $T$ 线性增长。$T=9$ 时 FPS 从 21.5 降至 6.1,显存从 424M 涨至 1149M。
本文做法(v2):将实例解耦为结构化 anchor(3D 框参数,有物理意义)和隐式 instance feature(高阶语义特征)。跨帧传播时,只需对 anchor 做 ego motion 投影并重新编码位置嵌入,instance feature 直接复用:
$$A_t = \text{Project}_{t-1 \to t}(A_{t-1}), \quad E_t = \Psi(A_t), \quad F_t = F_{t-1}$$Instance Bank 在每帧结束时缓存 top-$k$ 高置信度实例,下一帧将其与新初始化实例合并输入 decoder。Temporal Cross-Attention 在 decoder 中融合当前实例与历史传播实例。
为什么更好:
- 时序融合复杂度从 $O(T)$ 降至 $O(1)$,推理速度几乎不受历史帧数影响
- 递归传播理论上可累积无限长时序信息(vs. v1 受 GPU 显存限制最多 9 帧)
- 实例级传播直接产出跨帧关联关系,是后续端到端跟踪(v3)的基础
洞察 3:Temporal Instance Denoising + Quality Estimation——解决稀疏方法的训练收敛难题
传统做法:稀疏检测器使用 one-to-one 匈牙利匹配,正样本数量极少且早期匹配不稳定,导致 decoder 训练效率低、收敛慢。dense-BEV 方法天然拥有大量 BEV 栅格像素参与训练,无此问题。
本文做法(v3):
- Temporal Instance Denoising:对 GT 添加随机噪声生成 $M$ 组 noisy anchors,通过二分图匹配分配正负样本,提供稳定且充足的训练信号。关键创新是将 noisy instances 沿时间轴传播(ego motion + 速度补偿),使 decoder 在时序场景下也获得足够多的正样本
- Quality Estimation:引入 centerness(位置质量)和 yawness(朝向质量)作为辅助监督。推理时用 centerness × cls_confidence 作为最终得分排序依据,使检测结果排序更准确
为什么更好:
- Denoising 使正样本数增加数倍,训练收敛显著加速(Figure 6(a) 所示 loss 曲线和 metric 曲线均快速下降)
- Quality Estimation 改善高置信度但低质量预测的排序问题,mATE 降低 2.8%
- 两者结合使 v3 在 R50 上比 v2 提升 3.0% mAP / 2.2% NDS / 7.6% AMOTA
三个关键数字:
- 71.9% NDS:nuScenes test 集最强配置(EVA02-Large + 未来帧),超越部分 LiDAR 方法
- **$O(T) \to O(1)$**:v2 递归时序融合将计算复杂度从线性降至常数
- +7.6% AMOTA:v3 训练改进对跟踪的提升幅度(R50, 41.4→49.0),证明检测收敛性直接影响跟踪质量
方法设计
4.1 整体架构
$$\{I_t^i\}_{i=1}^{N} \xrightarrow{\text{Backbone+FPN}} F_t \xrightarrow[\text{+ Instance Bank}]{\text{Decoder (×6)}} \{(B_m, F_m, \text{cls}_m)\} \xrightarrow{\text{ID Assignment}} \text{3D Boxes + Tracks}$$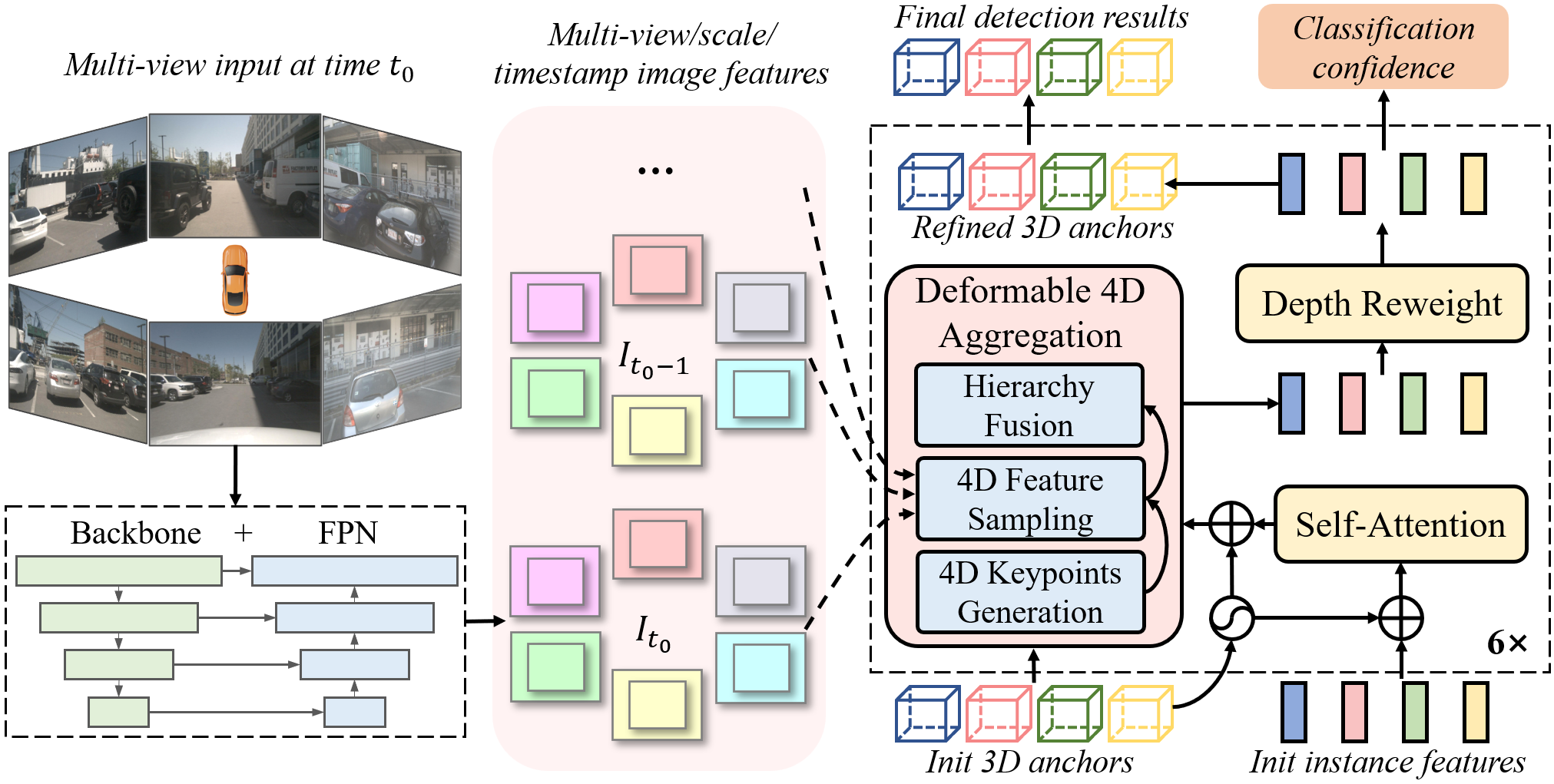
Multi-view Images (6 cams, multi-timestamp)
│
▼
Image Encoder (ResNet/VoV + FPN)
→ Multi-scale Feature Maps I = {I_{t,n,s}}
│
▼ ┌─────────────────────┐
Instance Bank │ Temporal Instances │
├─ Learnable Anchors (300) │ (top-600 from prev) │
└─ Learnable Features (300) └──────────┬──────────┘
│ │
▼ ▼
┌──────────────────────────────────────────────────────┐
│ Decoder Layer (×1 single-frame + ×5 multi) │
│ ┌──────────────────────────────────────────┐ │
│ │ Temporal Cross-Attention (temp_gnn) │◄──────┘
│ │ Q=instance, K/V=temporal instances │
│ ├──────────────────────────────────────────┤
│ │ Instance Self-Attention (gnn) │
│ │ Decoupled: concat(F, E) instead of F+E │
│ ├──────────────────────────────────────────┤
│ │ Deformable 4D Aggregation (deformable) │
│ │ Keypoints → project → sample → fuse │
│ ├──────────────────────────────────────────┤
│ │ FFN + Refine Layer │
│ │ → Δ(x,y,z,w,l,h,yaw,vx,vy) + cls + qt │
│ └──────────────────────────────────────────┘
└──────────────────────────────────────────────────────┘
│
▼
3D Boxes (10-dim) + Classification + Quality
│
┌───────┴───────┐
│ Instance Bank │ cache top-k → next frame
│ ID Assignment │ confidence > T → assign ID
└───────────────┘
│
▼
Detection Results + Tracking Trajectories
4.2 关键组件
| 模块 | 输入 | 输出 | 功能 | 关键参数 |
|---|---|---|---|---|
| Deformable 4D Aggregation | anchor, instance_feature, feature_maps | 更新的 instance_feature | 4D 关键点稀疏采样 + 层次化融合 | $K_F$=7, $K_L$=6, $S$=4 |
| Instance Bank | 上帧 top-k instances + 当前初始化 instances | 合并后的 instances | 递归传播 + top-k 选择 | 600 temporal + 300 new |
| Anchor Encoder | anchor (11-dim) | anchor_embed (256-dim) | 结构化位置编码 | MLP |
| Refine Layer | instance_feature, anchor | 精炼 anchor + cls + quality | 逐层迭代精炼 | 6 层 cascade |
| Temporal Cross-Attention | current queries, temporal instances | 融合后 queries | 时序特征融合 | Decoupled Attention (v3) |
| Denoising Sampler | GT + noise | noisy anchors + targets | 训练时辅助正样本生成 | $M$=5 groups, 3 temporal |
损失函数:
$$\mathcal{L} = \lambda_1 \mathcal{L}_{cls} + \lambda_2 \mathcal{L}_{box} + \lambda_3 \mathcal{L}_{depth} + \lambda_4 (\text{CE}(Y_{pred}, Y) + \text{Focal}(C_{pred}, C))$$ 其中 $\mathcal{L}_{cls}$ 为 Focal Loss,$\mathcal{L}_{box}$ 为 $L_1$ Loss,$\mathcal{L}_{depth}$ 为 dense depth 辅助监督($L_1$,仅训练时),最后一项为 Quality Estimation 损失(v3)。4.3 关键代码
核心代码来自 HorizonRobotics/Sparse4D 仓库 projects/mmdet3d_plugin/models/:
| 文件 | 类/函数 | 功能 |
|---|---|---|
blocks.py |
DeformableFeatureAggregation.forward |
关键点生成→投影→采样→融合 |
blocks.py |
DeformableFeatureAggregation.feature_sampling |
多视图多尺度 grid_sample |
instance_bank.py |
InstanceBank.get |
获取当前帧实例(合并 temporal + new) |
instance_bank.py |
InstanceBank.cache |
缓存 top-k 实例供下帧使用 |
sparse4d_head.py |
Sparse4DHead.forward |
Decoder 主循环 |
📄 点击展开 DeformableFeatureAggregation.forward 代码
(来源:blocks.py)
def forward( |
📄 点击展开 feature_sampling(PyTorch 实现)代码
(来源:blocks.py)
|
📄 点击展开 InstanceBank.get / cache 代码
(来源:instance_bank.py)
def get(self, batch_size, metas=None, dn_metas=None): |
实验与分析
5.1 主要结果
nuScenes val 集 3D 检测:
| 方法 | 版本 | Backbone | Image Size | mAP↑ | NDS↑ | mAVE↓ | FPS |
|---|---|---|---|---|---|---|---|
| BEVFormer-S | — | R101 | 900×1600 | 0.375 | 0.448 | 0.802 | — |
| BEVFormer | — | R101 | 900×1600 | 0.416 | 0.517 | 0.394 | — |
| StreamPETR | — | R50 | 256×704 | 0.432 | 0.537 | 0.279 | 26.7 |
| Sparse4D | v1 | R101-DCN | 640×1600 | 0.444 | 0.550 | 0.309 | 2.9 |
| Sparse4Dv2 | v2 | R50 | 256×704 | 0.439 | 0.539 | 0.282 | 20.3 |
| Sparse4Dv2 | v2 | R101† | 512×1408 | 0.505 | 0.594 | 0.239 | 8.4 |
| Sparse4Dv3 | v3 | R50 | 256×704 | 0.469 | 0.561 | 0.227 | 19.8 |
| Sparse4Dv3 | v3 | R101† | 512×1408 | 0.537 | 0.623 | 0.194 | 8.2 |
† 表示使用 nuImage 预训练权重。
nuScenes test 集 3D 检测:
| 方法 | Backbone | mAP↑ | NDS↑ | mATE↓ | mAVE↓ |
|---|---|---|---|---|---|
| BEVFormer | V2-99 | 0.481 | 0.569 | 0.582 | 0.378 |
| StreamPETR | V2-99 | 0.550 | 0.636 | 0.479 | 0.241 |
| Sparse4D v1 | V2-99 | 0.511 | 0.595 | 0.533 | 0.317 |
| Sparse4Dv2 | V2-99 | 0.557 | 0.638 | 0.462 | 0.264 |
| Sparse4Dv3 | V2-99 | 0.570 | 0.656 | 0.412 | 0.210 |
| Sparse4Dv3-offline | EVA02-L | 0.668 | 0.719 | 0.346 | 0.142 |
关键发现:
- v1→v2 提升主要来自递归时序融合(NDS 0.550→0.594),同时推理速度从 2.9 FPS 跃升至 8.4 FPS
- v3 三项改进带来 +3.0% mAP / +2.2% NDS(R50),且速度几乎无损(20.3→19.8 FPS)
- 稀疏方法在高分辨率输入下速度优势明显:R101 512×1408 时 Sparse4Dv2(8.4 FPS)超过 StreamPETR(6.4 FPS),因为检测头计算量与分辨率无关
5.2 消融实验:验证三个洞察
v1 消融——4D 关键点(验证洞察 1):
| 配置 | mAP | mAOE | NDS | 验证洞察 |
|---|---|---|---|---|
| 无 Depth Reweight,无 Learnable KP | 0.432 | 0.408 | 0.533 | baseline |
| + Depth Reweight | 0.431 | 0.381 | 0.537 | 洞察 1 |
| + Learnable Keypoints | 0.432 | 0.379 | 0.537 | 洞察 1 |
| + 两者 | 0.436 | 0.363 | 0.541 | 洞察 1 |
v2 消融——递归传播(验证洞察 2):
| 配置 | Multi-Frame | Single-Frame Layer | mAP | NDS | 验证洞察 |
|---|---|---|---|---|---|
| 非时序模型 | ✗ | — | 0.341 | 0.414 | baseline |
| 全 multi-frame layers | ✓ | ✗ | 0.384 | 0.504 | 洞察 2 |
| + Single-Frame Layer | ✓ | ✓ | 0.419 | 0.524 | 洞察 2 |
| + Camera Param Encoding + Dense Depth | ✓ | ✓ | 0.439 | 0.539 | 洞察 2 |
时序融合带来 +9.8 mAP / +12.5 NDS(0.341→0.439),是最大提升来源。
v3 消融——训练改进(验证洞察 3):
| 配置 | mAP | mATE | mAVE | NDS | AMOTA | 验证洞察 |
|---|---|---|---|---|---|---|
| Sparse4Dv2 baseline | 0.439 | 0.598 | 0.282 | 0.539 | 0.414 | — |
| + Single-frame Denoising | 0.447 | 0.586 | 0.257 | 0.548 | 0.445 | 洞察 3 |
| + Decoupled Attention | 0.458 | 0.599 | 0.238 | 0.551 | 0.472 | 洞察 3 |
| + Temporal Denoising | 0.462 | 0.581 | 0.246 | 0.557 | 0.457 | 洞察 3 |
| + Centerness | 0.463 | 0.563 | 0.221 | 0.554 | 0.466 | 洞察 3 |
| + Yawness (Sparse4Dv3) | 0.469 | 0.553 | 0.227 | 0.561 | 0.490 | 洞察 3 |
Denoising 贡献最大(+0.9% NDS),Decoupled Attention 主要改善 mAVE(-1.9%),Quality Estimation 主要改善 mATE(-2.8%)。
5.3 性能瓶颈分析
- Backbone 仍是瓶颈:Sparse4D 检测头 FLOPs(165G, $T$=1)远低于 backbone(854G, R101),高分辨率场景下 backbone 开销主导总延迟
- 深度定位精度:mATE(0.412m, test, V2-99)虽优于 BEVFormer(0.582m),但仍是纯相机方法的主要误差来源
- 训练资源需求:100 epoch 训练(R50, 256×704)需 22 小时 / 8×RTX3090,比 BEVDet 等 24 epoch 方案更耗时
5.4 失效场景分析
- 严重遮挡目标:稀疏关键点投影到图像上可能完全被遮挡,采样到的特征无意义
- 高密度小目标区域:900 个 anchor 数量固定,在行人密集的城区场景中可能欠分配
- 首帧无时序信息:第一帧没有 temporal instances 输入,等价于单帧 Sparse4D(性能比时序版低约 12.5% NDS)
- 极端自车运动:速度补偿基于匀速假设(Eq. 3),急刹/急转场景下关键点投影偏差会增大
工程实践
6.1 训练配置
Backbone: ResNet50/101 (ImageNet/nuImage) 或 VoVNet-99 (DD3D) |
6.2 复现要点
- Anchor 初始化:3D anchor 的位置参数 $(x,y,z)$ 由 K-Means 在训练集上聚类得到(
nuscenes_kmeans900.npy),其他参数固定初始化 ${1,1,1,0,1,0,0,0}$ - 历史特征 detach:所有 temporal instances 的 feature 和 anchor 在 cache 时断梯度(
detach()),避免跨帧反向传播导致显存爆炸 - Efficient Deformable Aggregation(EDA):v2 的定制 CUDA kernel 将 grid_sample + weighted sum 融合为单一操作,训练显存降 51%(6328M→3100M),推理速度提升 42%(13.7→20.3 FPS)
- Dense Depth Supervision:训练时对多尺度特征图预测 dense depth,LiDAR 点云投影作为 GT,$L_1$ loss。推理时该分支不激活。移除此监督会导致训练梯度坍缩
- Denoising 训练不改变推理:所有 noisy instances 仅用于训练辅助,推理时完全去除,不增加推理开销
- 端到端跟踪零成本:v3 跟踪功能无需修改训练流程或 loss,仅在推理时对 confidence > threshold 的 temporal instances 分配 ID
6.3 性能优化方向
精度提升:
- 更强 Backbone:从 R50 换到 EVA02-Large 带来 +5.98% mAP(test),Backbone 特征质量直接决定检测精度上限
- 未来帧融合:利用后续 8 帧图像特征(离线场景),mAVE 降低 5.67%、NDS 提升 3.23%
- 增加 Anchor 数量:当前 900 个 anchor 在高密度场景可能不足,增加至 1200+ 可改善小目标召回
速度优化:
- 轻量化 Backbone:稀疏检测头计算量已极低(~165G),优化 Backbone(如 EfficientNet、MobileNet)收益最大
- EDA CUDA Kernel:v2 的 EDA 已证明可将训练时间从 23.5h 降至 14.5h,进一步的 kernel 融合仍有空间
- 高分辨率优势:稀疏方法在 512×1408 分辨率下仍保持 8.4 FPS(vs. StreamPETR 6.4 FPS),适合部署在高分辨率需求场景
研究启示
7.1 可迁移的思想
- “实例为中心”的感知范式:以 anchor + instance feature 为原子单元,所有操作(采样、融合、时序、跟踪)围绕实例展开,取代 BEV 栅格作为中间表示。这一范式直接催生了后续 SparseDrive 等端到端规划方法
- 递归实例传播:将跨帧特征传播解耦为”结构化投影 + 隐式特征复用”,$O(1)$ 时间复杂度实现无限长时序融合。该思路可迁移到在线建图、占据预测等需要长时序信息的任务
- 训练阶段去噪增强:通过向 GT 添加噪声生成大量辅助正样本,在不改变推理流程的情况下显著加速收敛。DN-DETR 在 2D 检测中提出此思想,Sparse4Dv3 将其扩展到 3D 时序场景
- 检测器即跟踪器:利用 query-based 方法的实例级输出天然包含跨帧关联关系,仅需在推理时添加 ID 分配即可实现端到端跟踪,无需数据关联或轨迹滤波等后处理
7.2 方法局限
- 训练成本高于 dense 方法:100 epoch 训练(v2/v3)比 BEVDet 的 24 epoch 更耗时,训练收敛性仍弱于 dense BEV 路线
- 采样依赖标定精度:关键点投影到图像的准确性依赖相机内外参质量,虽然 Camera Parameter Encoding(v2)部分缓解,但极端标定偏差仍会导致特征失配
- 固定 anchor 数量:900 个 anchor 是超参数,在高密度场景可能不足、在空旷场景则有冗余,缺乏自适应机制
7.3 技术影响
- 确立稀疏感知路线的竞争力:Sparse4D 系列首次证明稀疏方法可以在 nuScenes 上与 dense BEV 方法持平甚至超越(v3 65.6% NDS vs. BEVFormer 56.9%),扭转了”稀疏不如 dense”的普遍认知
- 检测头复杂度与分辨率解耦:稀疏方法的检测头 FLOPs 与图像分辨率无关,这对自动驾驶中日益增长的高分辨率需求(远距离检测、4K 相机)具有关键意义,与 LSS 系列的 dense 方案形成互补
- 推动端到端自动驾驶:SparseDrive 直接基于 Sparse4D 框架实现端到端规划,证明了”稀疏实例→跟踪→预测→规划”全链路的可行性
- Horizon Robotics 量产方案基础:Sparse4D 由地平线机器人提出,其稀疏架构对边缘设备部署友好(无 dense BEV 计算),是该公司自动驾驶芯片的重要适配方案