Task: End-to-End Autonomous Driving (Perception → Planning)
Method: Vectorized Scene Representation + Probabilistic Planning (Trajectory Vocabulary)
Venue: ICCV 2023 (VAD) / arXiv 2024 (VADv2)
Year: 2023–2024
Paper: https://arxiv.org/abs/2303.12077 (VAD) / https://arxiv.org/abs/2402.13243 (VADv2)
Code: https://github.com/hustvl/VAD
1. 摘要
VAD(ICCV 2023)与 VADv2(arXiv 2024)由华中科技大学 + 地平线团队提出,是端到端自动驾驶在 UniAD 之后最关键的两步演进:把感知-规划全链路从”BEV 栅格 + 多任务级联 + 单轨迹回归”重塑为”全向量化场景 + 概率分布规划”。
- VAD 用
MapTR + Planning的设计哲学,把地图、交通参与者、自车都表示为 vector query,在 nuScenes 开环上把 avg L2 从 UniAD 的 1.03 m 降到 0.72 m(−30.1%)、avg Col 从 0.31% 降到 0.22%(−29.0%),推理速度 +2.5×。Planning Head 仅占 5.7% 推理时间。 - VADv2 进一步把”回归一条轨迹”换成”在 4096 条轨迹词汇表上学习 $p(a|o)$ 概率分布”,并用 Probabilistic Field(NeRF 式位置编码 + Transformer 打分头)建模动作不确定性。在 CARLA Town05 Long benchmark 上把 Driving Score 从 SOTA 的 76.1 抬到 85.1(+9.0)。
核心论点:端到端规划不该被建模成”环境 → 唯一动作”的确定性映射——真实驾驶充满歧义和多模态选择。VAD 用向量化把约束注入设计、VADv2 用概率分布把不确定性注入学习,二者合起来定义了”评分派”端到端规划的范式基线(DiffusionDrive 是其”生成派”对照)。
2. 问题与动机
| 方法 | 痛点 |
|---|---|
| 模块化 pipeline(感知→检测→跟踪→预测→规划→控制) | 信息瓶颈、误差累积、模块耦合复杂 |
| UniAD | 多任务全栈级联(含 tracking / occupancy),栅格 BEV 重,planning 仍是单轨迹回归(avg L2 1.03 m) |
| VAD 自身(v1) | 仍是确定性回归——非凸可行解空间下倾向输出”中间解”或最频繁模式(停车 / 直行),歧义场景失败 |
核心痛点(VAD → VADv2 两步走):
- 表示太重:dense BEV + tracking + occupancy 让端到端方案推理慢且工程复杂;
- 决策太窄:单轨迹回归无法表达”直行 or 变道”这类多模态合理动作;
- 约束太隐式:纯模仿学习缺少显式安全约束(碰撞 / 边界 / 车道方向)。
3. 核心洞察
洞察 1(VAD):向量化场景 = 轻量化 + 显式约束
UniAD 的 dense BEV + occupancy 既贵又难直接表达”自车 vs 第 i 个 agent 的距离”这类几何约束。VAD 把场景全部 vector 化:
- map vector:100 个 map query × 20 个点(沿用 MapTR 的分层查询设计);
- agent vector:300 个 agent query → 多模态未来轨迹;
- ego vector:1 个 ego query → 自车未来 $T_f$ 步轨迹。
显式约束直接写成 loss:
$$\mathcal{L}_{col}^{i,t} = \begin{cases} \delta_i - d^i_{a,t}, & d^i_{a,t} < \delta_i \\ 0, & \text{otherwise} \end{cases}$$ $$\mathcal{L}_{dir} = \frac{1}{T_f}\sum_{t=1}^{T_f} F_{\text{ang}}(\hat{v}^m_t,\ \hat{v}^{ego}_t)$$三项约束(碰撞 / 越界 / 车道方向)累加,让规划在训练时就被几何”硬”约束推开危险区。消融:栅格化 map 0.74 m / 0.39% Col → 向量化 map 0.72 m / 0.22% Col,碰撞率近半。
洞察 2(VAD):ego query 通过 Transformer 隐式吸收场景
Planning Head 只是一个 MLP,但其输入 ego query 经过两步 Transformer 交互:
$$Q'_{ego} = \text{Cross-Attn}(Q_{ego},\ \{Q_{agent}\})$$ $$Q''_{ego} = \text{Cross-Attn}(Q'_{ego},\ \{Q_{map}\})$$最终轨迹由 $[Q'_{ego}, Q''_{ego}, s_{ego}, \text{cmd}]$ 通过 MLP 输出。这里”隐式(attention 学习)+ 显式(vector loss)”是 VAD 最优雅的设计——前者管”理解”、后者管”安全”。
洞察 3(VADv2):把规划建模为 $p(a|o)$ 概率分布,不再回归
VADv2 的论点直接而尖锐:环境到动作根本不存在确定性映射,强行回归会输出”平均解”。把规划改造为概率分布:
- Trajectory Vocabulary:从演示数据用 furthest-trajectory sampling 离线采样 $N = 4096$ 条代表性轨迹,每条 $a = (x_1, y_1, \ldots, x_T, y_T)$;
- Probabilistic Field:用 NeRF 式位置编码 $\Gamma$ 把每条轨迹映射到 embedding 空间
- Scoring Head:所有轨迹与场景 token 一起进 Transformer,输出每条轨迹的概率
训练用 KL 散度把预测分布与”GT 为正、其余按距离加权”的目标分布对齐。消融最有冲击力:去掉 Distribution Loss 时 1 s L2 从 0.082 m 暴涨到 1.415 m(17×),证明概率建模是 v2 的本质,而不是装饰。
三个洞察的递进关系
- 表示(VAD):向量化让场景轻量化、约束可显式书写;
- 交互(VAD):ego query 通过 attention 隐式吸收 agent / map 信息;
- 决策(VADv2):把”回归一条”换成”在词汇表上分布建模”,捕捉真实驾驶的多模态。
三个关键数字:
- avg L2 0.72 m / Col 0.22% / 4.5 FPS(VAD-Base):vs UniAD 1.03 / 0.31% / 1.8 FPS,−30% L2 + 2.5× speed;
- DS 85.1 vs 76.1(VADv2 vs DriveMLM, CARLA Town05 Long):概率规划在闭环上的纯增益;
- 去掉 Distribution Loss → L2 ↑ 17×:概率分布而非词汇表是 VADv2 的真正灵魂。
4. 方法设计
4.1 整体架构
VAD:
$$\text{6 cams} \xrightarrow{\text{R50}} \text{PV} \xrightarrow{\text{BEV Encoder}} \text{BEV} \to \begin{cases} \text{Map Query (100×20)} \\ \text{Agent Query (300, multi-mode)} \\ \text{Ego Query (1)} \end{cases} \xrightarrow{\text{Cross-Attn ×2}} \text{Planning Head} \to \tau_{ego}$$VADv2 在 VAD 基础上把 Planning Head 换成 Probabilistic Planning:
$$\{\text{Map / Agent / Traffic / Image / Navi / State tokens}\} + \{a_i\}_{i=1}^{4096} \to \text{Scoring Head} \to p(a_i | o)$$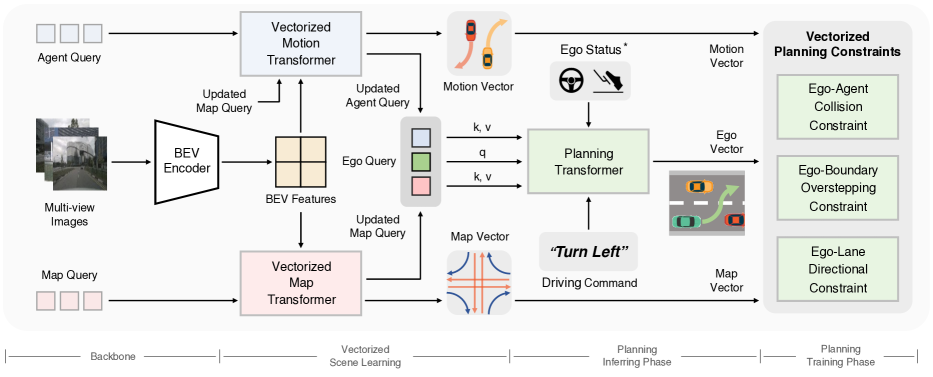
图 1:VAD 整体架构(来源:论文 Figure 2)

图 2:VADv2 概率规划架构(来源:论文 Figure 2)
v1/v2 架构对比:
┌─────────────────────┐
6 cams ──► R50 ──► │ BEV Encoder │
│ (200×200 BEV query) │
└──────────┬──────────┘
│ BEV feat
┌──────────────────────┼──────────────────────┐
▼ ▼ ▼
┌────────────────┐ ┌──────────────────┐ ┌────────────────┐
│ Map Module │ │ Agent Module │ │ Traffic Module │
│ 100 q × 20 pt │ │ 300 q multi-mode │ │ (VADv2) │
│ (MapTR-style) │ │ trajectories │ │ light/sign │
└──────┬─────────┘ └────────┬─────────┘ └────────┬───────┘
│ map vec │ agent vec │ traffic vec
│ │ │
└─────────┬────────────┴──────────────────────┘
│
▼
┌────────────────────────────────────────┐
│ Ego Query │
│ Q'_ego = CrossAttn(Q_ego, Agents) │ ──┐
│ Q''_ego = CrossAttn(Q'_ego, Maps) │ │
└────────────────────┬───────────────────┘ │
│ │
┌───────────────────┴───────────────────┐ │
▼ VAD ▼ VADv2
┌────────────────────┐ ┌────────────────────────────┐
│ Planning Head MLP │ │ Probabilistic Planning │
│ regress 1 traj │ │ • Vocabulary 𝕍 (4096 traj) │
│ + L_col / L_bd / │ │ • Probabilistic Field │
│ L_dir / L_imi │ │ E(a) via NeRF posenc Γ │
│ │ │ • Scoring Transformer │
│ │ │ p(a) over all 4096 │
└─────────┬──────────┘ │ • L_distribution (KL) + │
│ │ L_conflict + L_token │
▼ └────────────┬───────────────┘
τ_ego ▼
sampled / argmax τ_ego
4.2 关键组件对比
| 模块 | VAD | VADv2 |
|---|---|---|
| Backbone | ResNet-50 | ResNet-50 |
| BEV | 200×200 BEV query | scene token(map / agent / traffic / image / navi / state) |
| Map Head | 100 map query × 20 pt(MapTR-style) | map token(centerline / divider / boundary / crossing) |
| Agent Head | 300 agent query,多模态轨迹 | agent token,多模态轨迹 |
| Planning | MLP 回归 1 条 ego 轨迹 | 4096-轨迹词汇表 + Probabilistic Field + Transformer 评分 |
| Loss | $\mathcal{L}_{map} + \mathcal{L}_{mot} + \mathcal{L}_{col} + \mathcal{L}_{bd} + \mathcal{L}_{dir} + \mathcal{L}_{imi}$ | $\mathcal{L}_{distribution} + \mathcal{L}_{conflict} + \mathcal{L}_{token}$ |
| 评估 | nuScenes 开环 | CARLA 闭环 + nuScenes 开环 |
4.3 关键代码
VAD Planning Head 的 ego-agent / ego-map 双交互(基于官方 vad_head.py 整理):
# 来源:projects/mmdet3d_plugin/VAD/dense_heads/VAD_head.py |
📄 点击展开:VADv2 概率规划评分头核心伪代码
# 来源(基于论文 Eq. 1 与官方实现整理) |
5. 实验与分析
5.1 主要结果
nuScenes 开环(VAD,论文 Table 1)
| 方法 | Avg L2 (m) | Avg Col (%) | Latency (ms) | FPS |
|---|---|---|---|---|
| UniAD | 1.03 | 0.31 | 555.6 | 1.8 |
| VAD-Tiny | 0.78 | 0.38 | 59.5 | 16.8 |
| VAD-Base | 0.72 | 0.22 | 224.3 | 4.5 |
CARLA 闭环(VADv2,论文 Tab. 1–2,Town05)
| 方法 | Sensor | Town05 Long DS | Long RC (%) | Town05 Short DS | Short RC (%) |
|---|---|---|---|---|---|
| Transfuser | C+L | 31.0 | 47.5 | – | – |
| ST-P3 | C | 11.5 | 83.2 | 55.1 | 86.7 |
| VAD | C | 30.3 | 75.2 | 64.3 | 87.3 |
| ThinkTwice | C+L | 70.9 | 95.5 | – | – |
| DriveMLM | C+L | 76.1 | 98.1 | – | – |
| VADv2 | C | 85.1 | 98.4 | 89.7 | 93.0 |
关键发现:
- VAD 在开环上首次让端到端方法的 avg Col 进入 0.2% 区间,且 4.5 FPS 接近实时;
- VADv2 在 CARLA Long benchmark 上以纯相机超越多传感器 SOTA(DriveMLM)9.0 DS;
- Tiny 配置(59.5 ms / 16.8 FPS)证明向量化范式的工程友好性。
5.2 消融实验:验证三个洞察
VAD(论文 Tab. 2 / Tab. 3)
| 配置 | Avg L2 (m) | Avg Col (%) | 验证洞察 |
|---|---|---|---|
| 栅格化 map | 0.74 | 0.39 | 洞察 1(向量化优于栅格) |
| 向量化 map(默认) | 0.72 | 0.22 | 洞察 1 |
| 去掉 Map 交互 | 0.76 | 0.28 | 洞察 2(map 对规划至关重要) |
| 去掉 Agent + Map 交互 | 0.82 | 0.26 | 洞察 2(隐式交互不可或缺) |
| 三项显式约束都开 | 0.72 | 0.22 | 洞察 1 / 2 联合 |
VADv2(论文 Tab. 3)
| ID | Dist. Loss | Conf. Loss | Map / Agent / Traf | 1 s L2 | 1 s Col |
|---|---|---|---|---|---|
| 1 | ✗ | ✓ | ✓ | 1.415(崩溃) | 0.698 |
| 2 | ✓ | ✗ | ✓ | 0.086 | 0.012(增加) |
| 7 | ✓ | ✓ | ✓ | 0.082 | 0.000 |
1 行验证洞察 3:去掉 Distribution Loss → L2 暴涨 17×,证明概率分布建模才是 v2 的核心;2 行验证 Conflict Loss 主管安全;scene token 任一缺失都略降。
5.3 性能瓶颈分析
VAD-Tiny 推理时间分布(论文 Tab. 5):
| 模块 | 耗时 (ms) | 占比 |
|---|---|---|
| Backbone | 23.2 | 39.0% |
| BEV Encoder | 12.3 | 20.7% |
| Motion Module | 11.5 | 19.3% |
| Map Module | 9.1 | 15.3% |
| Planning Module | 3.4 | 5.7% |
Backbone + BEV Encoder 占 60%,与 MapTR / BEVFormer 同构;Planning 仅 5.7%,证明”重感知 + 轻规划”的工程取向。
5.4 失效场景分析
- VAD:碰撞约束只用最高置信度 agent motion,多模态预测被浪费;缺少高层信息(lane graph 拓扑、信号灯、停车标志);依赖外部 driving command 给方向;
- VADv2:仅在 CARLA 验证,真实路况未充分检验;轨迹词汇表大小 4096 是固定的,无在线扩充机制;KL 损失对长尾驾驶行为依赖良好分布的演示数据。
6. 工程实践
6.1 训练配置
VAD: |
6.2 复现要点
- VAD 的 collision loss 阈值 $\delta_i$ 与 agent 类别绑定——对车 / 人 / 自行车要分别设置,过大会让规划畏首畏尾;
- map vector 必须用 MapTR-style 分层查询:把所有点拼成长 query 会让 ego-map cross-attn 退化为均值池化;
- VADv2 的 trajectory vocabulary 必须用 furthest sampling——随机采样会丢失低频但关键的”急停 / 变道”模式;
- NeRF 位置编码的频段 $L$ 是关键超参:太小(< 4)轨迹差异被抹平,太大(> 10)训练不稳定;论文用 $2L = 10$;
- VADv2 的 KL 目标分布需要给 GT 之外的”次优”轨迹合理权重(通常按几何距离衰减),否则 Distribution Loss 退化为 one-hot 分类。
6.3 性能优化方向
精度提升
- 把 agent 多模态预测全部进入 collision 约束(VAD 的明确遗留问题);
- 引入 lane graph 拓扑、信号灯、限速等高级语义;
- VADv2 的词汇表换成动态生成(在线扩充罕见场景轨迹);
- 用 DiffusionDrive 的截断扩散替代固定词汇表,是评分 → 生成的天然延伸。
速度优化
- VAD-Tiny 已达 16.8 FPS,可用蒸馏 / 更小 backbone 进一步压缩;
- VADv2 的 4096 条评分可在 GPU 上批量并行,瓶颈在 backbone;
- 2 stage 推理(先在词汇表上选 top-32,再细化)可降评分头计算量 100×。
7. 研究启示
7.1 可迁移的思想
- 向量化场景 + 显式几何约束:在任何”感知-决策”任务里都比 dense 表示 + 隐式损失更可控;
- 隐式交互(attention) + 显式约束(loss):是 VAD 最优雅的设计哲学,可推广到所有 query-based 决策网络;
- 离散动作词汇表 + 概率分布:受 GPT 启发的”$p(\text{action} | \text{obs})$”建模,是把 LLM 范式带进策略学习的关键模板;
- NeRF 位置编码用于动作:Probabilistic Field 把连续动作空间编码到高频 embedding,是连续控制问题的通用 trick。
7.2 方法局限
| 局限 | VAD | VADv2 |
|---|---|---|
| 多模态利用 | agent 多模态预测仅取最自信一条做 collision | 动作多模态完整建模 |
| 评测 | 仅 nuScenes 开环 | 仅 CARLA 闭环(真实路况未验证) |
| 词汇表 | – | 固定 4096 条,无在线扩充 |
| 安全 | 显式 loss 仍是软约束 | KL 目标分布权重设计敏感 |
7.3 技术影响
- VAD 直接定义了”评分派”端到端规划范式:把规划简化为”在多模态 vector 场景上输出一条轨迹”,被后续 SparseDrive / Hydra-MDP / GoalFlow 等大量复用;
- VADv2 把 LLM 范式 $p(a|o)$ 引入端到端规划,与 DiffusionDrive 的”生成派”形成 2024–2025 端到端规划两条主线(评分 vs 生成);
- MapTR + Planning = VAD 的工程公式直接催生 SparseDrive(去 BEV)、SparseDriveV2(分解词表 + 层级评分)等后续工作;
- VADv2 的 Trajectory Vocabulary 设计成为多模态规划的事实基线:DiffusionDrive 的 20 个锚点、Hydra-MDP 的 8192 条、SparseDriveV2 的 26 万分解组合都在与之对照;
- 端到端范式的下一站(DriveWorld / DiffAD / VLA 等)几乎都把 VAD 的”vector scene”或 VADv2 的”action vocabulary”当作起点。